MicroT: Low-Energy and Adaptive Models for MCUs

0

Sign in to get full access
Overview
- Introduces MicroT, a new approach for designing low-energy and adaptive machine learning models for resource-constrained microcontroller units (MCUs)
- Focuses on optimizing deployment of tiny transformer models on low-power MCUs
- Builds on recent advancements in optimizing deployment of tiny transformers on low-power MCUs, resource-aware task-adaptive sparse training, memory-efficient energy-adaptive inference on pre-trained models, and model predictive control on resource-constrained MCUs
- Aims to enable efficient machine learning on low-power embedded devices for a wide range of real-world applications
Plain English Explanation
The paper introduces a new approach called MicroT that is designed to make machine learning models more energy-efficient and adaptable when running on low-power microcontroller units (MCUs). MCUs are small, inexpensive computer chips found in many everyday devices like appliances, toys, and sensors.
Traditionally, deploying machine learning models on MCUs has been challenging due to the limited computational resources and battery life of these devices. MicroT addresses this by optimizing the design of tiny transformer models - a type of machine learning model that has shown promise for MCU applications.
The key innovations of MicroT include techniques for:
- Optimizing Deployment: Efficiently deploying tiny transformer models on low-power MCUs, building on prior research in this area.
- Resource-Aware Training: Adapting the machine learning model during the training process to be more efficient for the target MCU hardware.
- Energy-Adaptive Inference: Dynamically adjusting the model's energy consumption during inference (when making predictions) based on the available battery life.
- Model Predictive Control: Incorporating model predictive control algorithms to help the MCU make decisions that balance performance and energy usage.
By incorporating these strategies, MicroT aims to enable a new class of intelligent, energy-efficient devices that can run advanced machine learning models on low-power hardware. This could open up a wide range of real-world applications, from smart home devices to wearable health trackers.
Technical Explanation
The paper first provides background on the challenges of deploying machine learning models on resource-constrained MCUs, and reviews related work in areas such as optimizing deployment of tiny transformers, resource-aware sparse training, memory-efficient energy-adaptive inference, and model predictive control on MCUs.
The core of the MicroT approach consists of the following key elements:
- Optimizing Deployment: Techniques for efficiently deploying tiny transformer models on low-power MCUs, building on prior work in this area.
- Resource-Aware Training: Adapting the machine learning model during the training process to be more efficient for the target MCU hardware, taking into account factors like memory constraints and computational capabilities.
- Energy-Adaptive Inference: Dynamically adjusting the model's energy consumption during inference (when making predictions) based on the available battery life, in order to maximize performance while minimizing energy usage.
- Model Predictive Control: Incorporating model predictive control algorithms to help the MCU make decisions that balance performance and energy usage, optimizing for the specific constraints of the target application.
The paper describes the architectural details and design choices for each of these components, as well as the experimental evaluation conducted to validate the effectiveness of the MicroT approach.
Critical Analysis
The paper provides a comprehensive overview of the MicroT approach and the key innovations that differentiate it from prior work. The authors have clearly put a lot of thought into addressing the unique challenges of deploying machine learning on low-power MCUs.
One potential limitation of the work is the specific focus on tiny transformer models. While transformers have shown promise for MCU applications, there may be other model architectures or approaches that could also be effective. The authors acknowledge this and suggest that the general principles of MicroT could be applied to a wider range of model types.
Additionally, the paper does not delve deeply into the potential real-world implications and applications of this technology. While the authors mention a range of potential use cases, more discussion of the societal impact and potential ethical considerations could be valuable.
Overall, the MicroT approach appears to be a significant step forward in enabling efficient machine learning on resource-constrained devices. The technical innovations and experimental results presented in the paper are compelling, and the work opens up interesting avenues for further research and development in this important area.
Conclusion
The MicroT paper introduces a novel approach for designing low-energy and adaptive machine learning models for resource-constrained microcontroller units (MCUs). By incorporating techniques like optimized deployment, resource-aware training, energy-adaptive inference, and model predictive control, the MicroT framework aims to enable a new class of intelligent, energy-efficient devices that can run advanced machine learning models on low-power hardware.
The key innovations of MicroT build on recent advancements in areas like tiny transformer optimization, resource-aware sparse training, memory-efficient energy-adaptive inference, and model predictive control on MCUs. By combining these strategies, the MicroT framework holds significant promise for enabling a wide range of real-world applications on low-power embedded devices, from smart home systems to wearable health trackers.
The paper provides a comprehensive technical explanation of the MicroT approach, along with a critical analysis of its potential limitations and areas for further research. Overall, the work represents an important step forward in the field of tiny machine learning, and could have far-reaching implications for the development of intelligent, energy-efficient devices in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MicroT: Low-Energy and Adaptive Models for MCUs
Yushan Huang, Ranya Aloufi, Xavier Cadet, Yuchen Zhao, Payam Barnaghi, Hamed Haddadi
We propose MicroT, a low-energy, multi-task adaptive model framework for resource-constrained MCUs. We divide the original model into a feature extractor and a classifier. The feature extractor is obtained through self-supervised knowledge distillation and further optimized into part and full models through model splitting and joint training. These models are then deployed on MCUs, with classifiers added and trained on local tasks, ultimately performing stage-decision for joint inference. In this process, the part model initially processes the sample, and if the confidence score falls below the set threshold, the full model will resume and continue the inference. We evaluate MicroT on two models, three datasets, and two MCU boards. Our experimental evaluation shows that MicroT effectively improves model performance and reduces energy consumption when dealing with multiple local tasks. Compared to the unoptimized feature extractor, MicroT can improve accuracy by up to 9.87%. On MCUs, compared to the standard full model inference, MicroT can save up to about 29.13% in energy consumption. MicroT also allows users to adaptively adjust the stage-decision ratio as needed, better balancing model performance and energy consumption. Under the standard stage-decision ratio configuration, MicroT can increase accuracy by 5.91% and save about 14.47% of energy consumption.
Read more7/10/2024
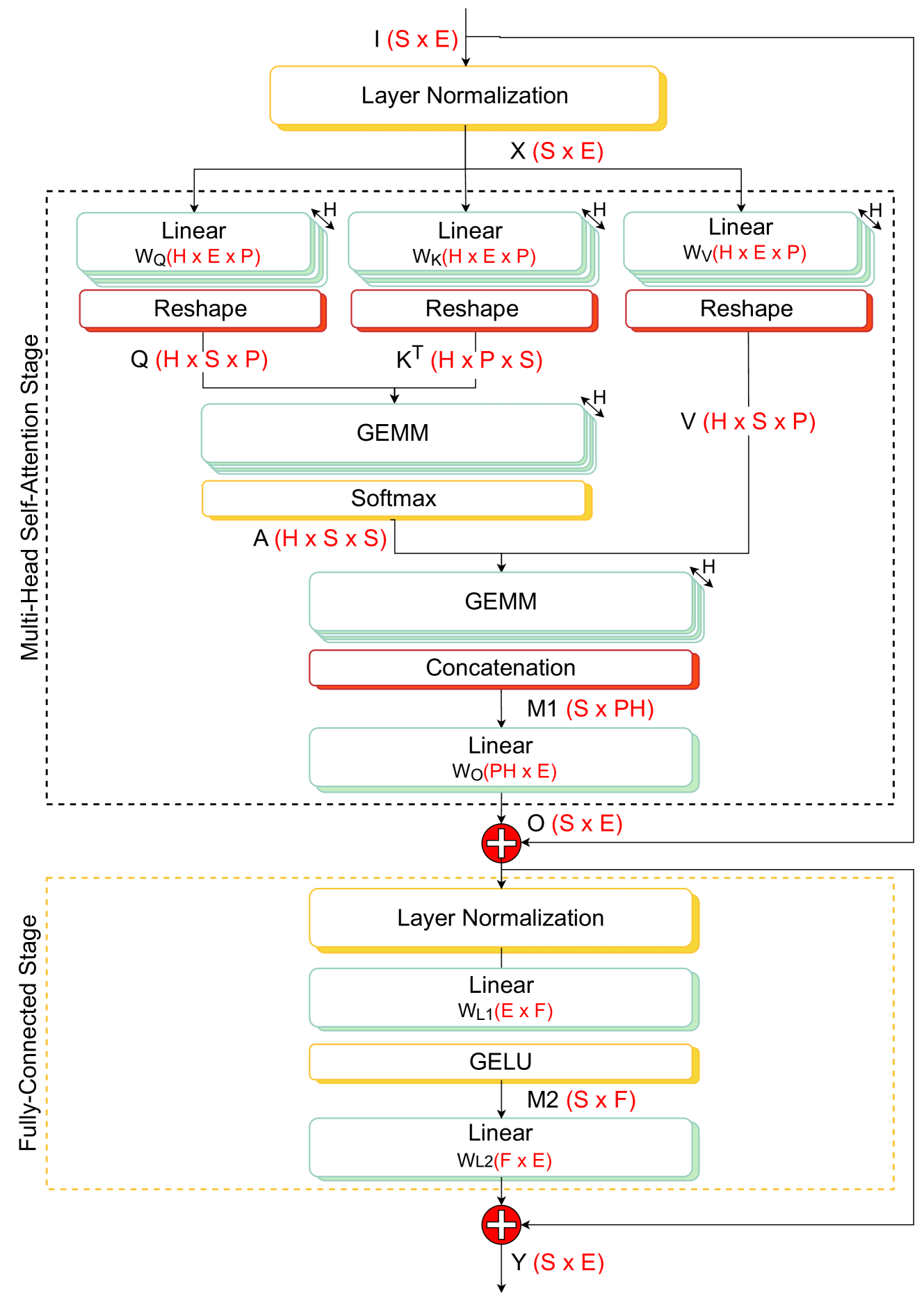
0
Optimizing the Deployment of Tiny Transformers on Low-Power MCUs
Victor J. B. Jung, Alessio Burrello, Moritz Scherer, Francesco Conti, Luca Benini
Transformer networks are rapidly becoming SotA in many fields, such as NLP and CV. Similarly to CNN, there is a strong push for deploying Transformer models at the extreme edge, ultimately fitting the tiny power budget and memory footprint of MCUs. However, the early approaches in this direction are mostly ad-hoc, platform, and model-specific. This work aims to enable and optimize the flexible, multi-platform deployment of encoder Tiny Transformers on commercial MCUs. We propose a complete framework to perform end-to-end deployment of Transformer models onto single and multi-core MCUs. Our framework provides an optimized library of kernels to maximize data reuse and avoid unnecessary data marshaling operations into the crucial attention block. A novel MHSA inference schedule, named Fused-Weight Self-Attention, is introduced, fusing the linear projection weights offline to further reduce the number of operations and parameters. Furthermore, to mitigate the memory peak reached by the computation of the attention map, we present a Depth-First Tiling scheme for MHSA. We evaluate our framework on three different MCU classes exploiting ARM and RISC-V ISA, namely the STM32H7, the STM32L4, and GAP9 (RV32IMC-XpulpV2). We reach an average of 4.79x and 2.0x lower latency compared to SotA libraries CMSIS-NN (ARM) and PULP-NN (RISC-V), respectively. Moreover, we show that our MHSA depth-first tiling scheme reduces the memory peak by up to 6.19x, while the fused-weight attention can reduce the runtime by 1.53x, and number of parameters by 25%. We report significant improvements across several Tiny Transformers: for instance, when executing a transformer block for the task of radar-based hand-gesture recognition on GAP9, we achieve a latency of 0.14ms and energy consumption of 4.92 micro-joules, 2.32x lower than the SotA PULP-NN library on the same platform.
Read more4/5/2024
🏋️
0
TinyTrain: Resource-Aware Task-Adaptive Sparse Training of DNNs at the Data-Scarce Edge
Young D. Kwon, Rui Li, Stylianos I. Venieris, Jagmohan Chauhan, Nicholas D. Lane, Cecilia Mascolo
On-device training is essential for user personalisation and privacy. With the pervasiveness of IoT devices and microcontroller units (MCUs), this task becomes more challenging due to the constrained memory and compute resources, and the limited availability of labelled user data. Nonetheless, prior works neglect the data scarcity issue, require excessively long training time (e.g. a few hours), or induce substantial accuracy loss (>10%). In this paper, we propose TinyTrain, an on-device training approach that drastically reduces training time by selectively updating parts of the model and explicitly coping with data scarcity. TinyTrain introduces a task-adaptive sparse-update method that dynamically selects the layer/channel to update based on a multi-objective criterion that jointly captures user data, the memory, and the compute capabilities of the target device, leading to high accuracy on unseen tasks with reduced computation and memory footprint. TinyTrain outperforms vanilla fine-tuning of the entire network by 3.6-5.0% in accuracy, while reducing the backward-pass memory and computation cost by up to 1,098x and 7.68x, respectively. Targeting broadly used real-world edge devices, TinyTrain achieves 9.5x faster and 3.5x more energy-efficient training over status-quo approaches, and 2.23x smaller memory footprint than SOTA methods, while remaining within the 1 MB memory envelope of MCU-grade platforms.
Read more6/12/2024

0
Memory-efficient Energy-adaptive Inference of Pre-Trained Models on Batteryless Embedded Systems
Pietro Farina, Subrata Biswas, Eren Y{i}ld{i}z, Khakim Akhunov, Saad Ahmed, Bashima Islam, Kas{i}m Sinan Y{i}ld{i}r{i}m
Batteryless systems frequently face power failures, requiring extra runtime buffers to maintain inference progress and leaving only a memory space for storing ultra-tiny deep neural networks (DNNs). Besides, making these models responsive to stochastic energy harvesting dynamics during inference requires a balance between inference accuracy, latency, and energy overhead. Recent works on compression mostly focus on time and memory, but often ignore energy dynamics or significantly reduce the accuracy of pre-trained DNNs. Existing energy-adaptive inference works modify the architecture of pre-trained models and have significant memory overhead. Thus, energy-adaptive and accurate inference of pre-trained DNNs on batteryless devices with extreme memory constraints is more challenging than traditional microcontrollers. We combat these issues by proposing FreeML, a framework to optimize pre-trained DNN models for memory-efficient and energy-adaptive inference on batteryless systems. FreeML comprises (1) a novel compression technique to reduce the model footprint and runtime memory requirements simultaneously, making them executable on extremely memory-constrained batteryless platforms; and (2) the first early exit mechanism that uses a single exit branch for all exit points to terminate inference at any time, making models energy-adaptive with minimal memory overhead. Our experiments showed that FreeML reduces the model sizes by up to $95 times$, supports adaptive inference with a $2.03-19.65 times$ less memory overhead, and provides significant time and energy benefits with only a negligible accuracy drop compared to the state-of-the-art.
Read more5/20/2024