MILAN: Milli-Annotations for Lidar Semantic Segmentation

0
🔎
Sign in to get full access
Overview
- Annotating lidar point clouds for autonomous driving is an expensive and time-consuming task.
- This work demonstrates that recent self-supervised lidar scan representations can significantly reduce annotation costs.
- The method has two main steps:
- Selecting highly informative lidar scans to annotate using self-supervised representations.
- Leveraging the same self-supervised representations to cluster points in the selected scans, requiring only a single click per cluster for annotation.
Plain English Explanation
Annotating lidar point clouds is a crucial but laborious process for training autonomous driving systems. This research shows that using self-supervised representations of lidar data can greatly reduce the amount of annotation required.
The first step is to use the self-supervised representations to identify the most informative lidar scans to annotate. This targeted approach leads to better results than randomly selecting scans to annotate. In fact, it performs on par with state-of-the-art active learning methods, which are designed to select the most useful data for annotation.
The second step is to use the same self-supervised representations to automatically group the points in the selected scans into clusters. The annotator then only needs to classify each cluster with a single click, rather than labeling every individual point. This reduces the annotation burden by a factor of 1,000, while still achieving results comparable to fully annotating every point.
Technical Explanation
The researchers leveraged recent advancements in self-supervised representation learning for lidar data to streamline the annotation process.
In the first step, they showed that training a network on a small subset of lidar scans selected using the self-supervised representations outperforms training on randomly selected scans. This "informed" selection strategy matches the performance of state-of-the-art active learning methods, which are designed to identify the most informative data for annotation.
In the second step, the researchers used the same self-supervised representations to automatically cluster the points in the selected lidar scans. Annotators then only needed to classify each cluster with a single click, rather than labeling every individual point. This clustering approach reduced the annotation burden by a factor of 1,000 while still achieving results comparable to fully annotating every point.
Critical Analysis
The paper demonstrates the power of self-supervised representation learning to streamline the expensive and labor-intensive task of annotating lidar data for autonomous driving. However, it is important to note that the experiments were conducted on a single dataset, and the generalization of these findings to other datasets or real-world scenarios may require further investigation.
Additionally, the paper does not explore the potential biases or limitations that may arise from the self-supervised representations or the clustering approach. As with any machine learning system, there is a risk of amplifying or introducing new biases, which could have implications for the fairness and robustness of the resulting autonomous driving models.
Further research could also investigate the scalability of this approach, as the benefits may diminish as the dataset size or complexity increases. Exploring ways to make the self-supervised representation learning and clustering more robust and adaptable would be valuable.
Conclusion
This research showcases how advancements in self-supervised representation learning can dramatically reduce the cost and effort required for annotating lidar data for autonomous driving. By leveraging these self-supervised representations to select informative scans and cluster points, the annotation burden can be reduced by a factor of 1,000 while still achieving performance on par with fully annotated datasets.
This work has the potential to accelerate the development of autonomous driving systems by making the data annotation process more efficient and scalable. As the field of machine learning continues to evolve, techniques like these that can reduce the reliance on expensive, manually-curated datasets will play an increasingly important role in driving progress.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
MILAN: Milli-Annotations for Lidar Semantic Segmentation
Nermin Samet, Gilles Puy, Oriane Sim'eoni, Renaud Marlet
Annotating lidar point clouds for autonomous driving is a notoriously expensive and time-consuming task. In this work, we show that the quality of recent self-supervised lidar scan representations allows a great reduction of the annotation cost. Our method has two main steps. First, we show that self-supervised representations allow a simple and direct selection of highly informative lidar scans to annotate: training a network on these selected scans leads to much better results than a random selection of scans and, more interestingly, to results on par with selections made by SOTA active learning methods. In a second step, we leverage the same self-supervised representations to cluster points in our selected scans. Asking the annotator to classify each cluster, with a single click per cluster, then permits us to close the gap with fully-annotated training sets, while only requiring one thousandth of the point labels.
Read more7/23/2024

0
Foundation Model assisted Weakly Supervised LiDAR Semantic Segmentation
Yilong Chen, Zongyi Xu, xiaoshui Huang, Ruicheng Zhang, Xinqi Jiang, Xinbo Gao
Weakly supervised LiDAR semantic segmentation has made significant strides with limited labeled data. However, most existing methods focus on the network training under weak supervision, while efficient annotation strategies remain largely unexplored. To tackle this gap, we implement LiDAR semantic segmentation using scatter image annotation, effectively integrating an efficient annotation strategy with network training. Specifically, we propose employing scatter images to annotate LiDAR point clouds, combining a pre-trained optical flow estimation network with a foundation image segmentation model to rapidly propagate manual annotations into dense labels for both images and point clouds. Moreover, we propose ScatterNet, a network that includes three pivotal strategies to reduce the performance gap caused by such annotations. Firstly, it utilizes dense semantic labels as supervision for the image branch, alleviating the modality imbalance between point clouds and images. Secondly, an intermediate fusion branch is proposed to obtain multimodal texture and structural features. Lastly, a perception consistency loss is introduced to determine which information needs to be fused and which needs to be discarded during the fusion process. Extensive experiments on the nuScenes and SemanticKITTI datasets have demonstrated that our method requires less than 0.02% of the labeled points to achieve over 95% of the performance of fully-supervised methods. Notably, our labeled points are only 5% of those used in the most advanced weakly supervised methods.
Read more8/13/2024
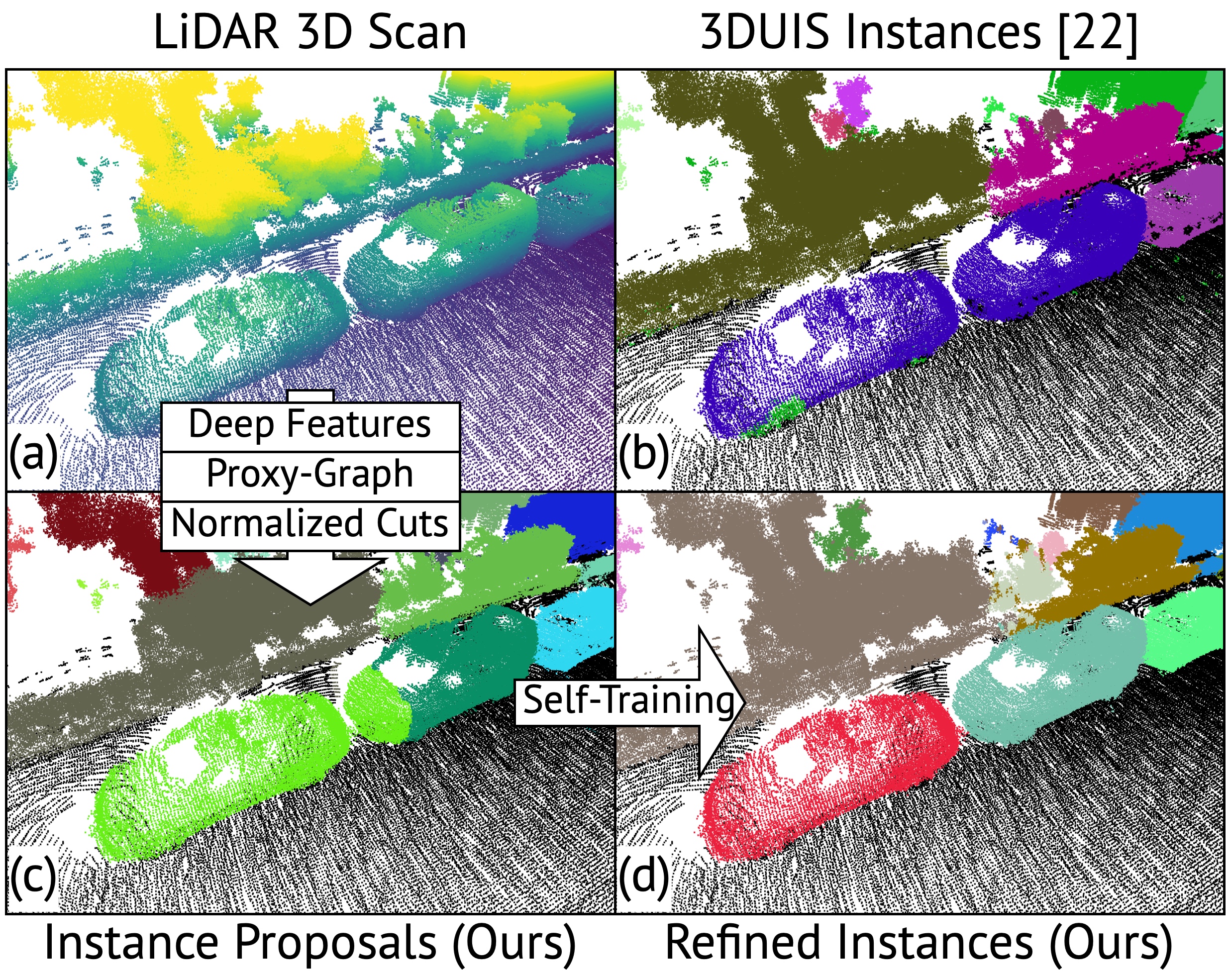
0
AutoInst: Automatic Instance-Based Segmentation of LiDAR 3D Scans
Cedric Perauer, Laurenz Adrian Heidrich, Haifan Zhang, Matthias Nie{ss}ner, Anastasiia Kornilova, Alexey Artemov
Recently, progress in acquisition equipment such as LiDAR sensors has enabled sensing increasingly spacious outdoor 3D environments. Making sense of such 3D acquisitions requires fine-grained scene understanding, such as constructing instance-based 3D scene segmentations. Commonly, a neural network is trained for this task; however, this requires access to a large, densely annotated dataset, which is widely known to be challenging to obtain. To address this issue, in this work we propose to predict instance segmentations for 3D scenes in an unsupervised way, without relying on ground-truth annotations. To this end, we construct a learning framework consisting of two components: (1) a pseudo-annotation scheme for generating initial unsupervised pseudo-labels; and (2) a self-training algorithm for instance segmentation to fit robust, accurate instances from initial noisy proposals. To enable generating 3D instance mask proposals, we construct a weighted proxy-graph by connecting 3D points with edges integrating multi-modal image- and point-based self-supervised features, and perform graph-cuts to isolate individual pseudo-instances. We then build on a state-of-the-art point-based architecture and train a 3D instance segmentation model, resulting in significant refinement of initial proposals. To scale to arbitrary complexity 3D scenes, we design our algorithm to operate on local 3D point chunks and construct a merging step to generate scene-level instance segmentations. Experiments on the challenging SemanticKITTI benchmark demonstrate the potential of our approach, where it attains 13.3% higher Average Precision and 9.1% higher F1 score compared to the best-performing baseline. The code will be made publicly available at https://github.com/artonson/autoinst.
Read more8/30/2024

0
Bayesian Self-Training for Semi-Supervised 3D Segmentation
Ozan Unal, Christos Sakaridis, Luc Van Gool
3D segmentation is a core problem in computer vision and, similarly to many other dense prediction tasks, it requires large amounts of annotated data for adequate training. However, densely labeling 3D point clouds to employ fully-supervised training remains too labor intensive and expensive. Semi-supervised training provides a more practical alternative, where only a small set of labeled data is given, accompanied by a larger unlabeled set. This area thus studies the effective use of unlabeled data to reduce the performance gap that arises due to the lack of annotations. In this work, inspired by Bayesian deep learning, we first propose a Bayesian self-training framework for semi-supervised 3D semantic segmentation. Employing stochastic inference, we generate an initial set of pseudo-labels and then filter these based on estimated point-wise uncertainty. By constructing a heuristic $n$-partite matching algorithm, we extend the method to semi-supervised 3D instance segmentation, and finally, with the same building blocks, to dense 3D visual grounding. We demonstrate state-of-the-art results for our semi-supervised method on SemanticKITTI and ScribbleKITTI for 3D semantic segmentation and on ScanNet and S3DIS for 3D instance segmentation. We further achieve substantial improvements in dense 3D visual grounding over supervised-only baselines on ScanRefer. Our project page is available at ouenal.github.io/bst/.
Read more9/14/2024