MIMII-Gen: Generative Modeling Approach for Simulated Evaluation of Anomalous Sound Detection System

0
🔎
Sign in to get full access
Overview
- Developing robust anomaly detection systems for machine sounds is challenging due to insufficient recordings and scarcity of anomalies.
- To address this, the researchers propose a novel approach using a latent diffusion-based model and an encoder-decoder framework to generate diverse anomalies in machine sounds.
- The approach utilizes the Flan-T5 model to encode captions derived from audio file metadata, enabling conditional generation through a U-Net architecture.
- The generated audio signals are evaluated using the Fréchet Audio Distance (FAD) score and other metrics, demonstrating that the approach surpasses existing models in generating reliable machine audio that closely resembles actual abnormal conditions.
- The evaluation of the anomaly detection system using the generated data revealed a strong correlation, validating the effectiveness of the generated data.
Plain English Explanation
Detecting when machine sounds are abnormal or problematic is important for maintaining equipment and avoiding breakdowns. However, developing and testing anomaly detection systems is challenging because there are often not enough examples of abnormal sounds to train the systems on.
To address this, the researchers came up with a new way to generate a variety of simulated abnormal machine sounds. They used a machine learning technique called a "latent diffusion model" combined with an "encoder-decoder framework." This allowed them to take information about the normal sounds, like captions describing the audio, and use that to create new, realistic-sounding abnormal audio samples.
The researchers tested the quality of the generated sounds using technical metrics, and found their approach outperformed existing methods. They also showed that using the generated data to train an anomaly detection system led to results very close to using real abnormal sounds. This suggests their generated data could be very useful for developing and evaluating these types of systems, even when real abnormal sounds are scarce.
Technical Explanation
The researchers tackle the challenge of insufficient real-world recordings of abnormal machine sounds and the scarcity of anomalies, which hinders the development and validation of robust anomaly detection systems.
To address these limitations, the team proposes a novel approach that leverages a latent diffusion-based model integrated with an encoder-decoder framework. This allows for the conditional generation of diverse anomalies in machine sounds. The key aspects of their method include:
-
Flan-T5 Encoding: The researchers use the Flan-T5 model to encode captions derived from audio file metadata. This enables the conditional generation of audio signals through a carefully designed U-Net architecture.
-
Latent Space Generation: The approach generates audio signals directly within the EnCodec latent space, ensuring high contextual relevance and quality of the generated sounds.
-
Evaluation Metrics: The team objectively evaluates the quality of the generated sounds using the Fréchet Audio Distance (FAD) score and other relevant metrics. Their results show the generated data outperforms existing models in terms of reliability and similarity to actual abnormal conditions.
-
Anomaly Detection System Evaluation: The researchers evaluate the anomaly detection system using the generated data, revealing a strong correlation, with the area under the curve (AUC) score differing by only 4.8% from the original. This validates the effectiveness of the generated data for training and testing anomaly detection systems.
Critical Analysis
The researchers acknowledge the significant challenges in developing robust anomaly detection systems for machine sounds due to the scarcity of real-world abnormal examples. Their proposed solution to generate diverse anomalies using a latent diffusion-based model is a creative and promising approach.
One potential limitation is the reliance on the Flan-T5 model for encoding audio metadata, as the performance may be dependent on the quality and coverage of the training data used for this model. Additionally, while the researchers demonstrate the effectiveness of their generated data for evaluating anomaly detection systems, it would be valuable to further explore the generalizability of their approach across a wider range of machine sound datasets and anomaly types.
Furthermore, the researchers could consider investigating the use of other generative models, such as GANs or variational autoencoders, to potentially capture more nuanced patterns in the abnormal machine sounds. Exploring ways to directly model the anomalies, rather than relying solely on conditional generation, may also lead to further improvements in the quality and diversity of the generated data.
Overall, the researchers have presented a compelling approach to address a significant challenge in the field of machine sound anomaly detection. Their work highlights the potential of generative modeling techniques to enhance the evaluation and robustness of these critical systems.
Conclusion
The researchers have developed a novel approach to generate diverse anomalies in machine sounds using a latent diffusion-based model and an encoder-decoder framework. By leveraging the Flan-T5 model to encode audio metadata and a carefully designed U-Net architecture, their method is able to produce high-quality, contextually relevant synthetic abnormal sounds.
The evaluation of the generated data demonstrates its superiority over existing models in terms of reliability and similarity to actual abnormal conditions. Importantly, the researchers have shown that using this generated data to train and test anomaly detection systems leads to results very close to using real abnormal sounds, validating the effectiveness of their approach.
These findings have significant implications for the development and robustness of anomaly detection systems across a variety of machine sound applications. By addressing the challenge of insufficient real-world abnormal samples, the researchers' work paves the way for more comprehensive and reliable anomaly detection, ultimately improving the maintenance and performance of critical machinery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
MIMII-Gen: Generative Modeling Approach for Simulated Evaluation of Anomalous Sound Detection System
Harsh Purohit, Tomoya Nishida, Kota Dohi, Takashi Endo, Yohei Kawaguchi
Insufficient recordings and the scarcity of anomalies present significant challenges in developing and validating robust anomaly detection systems for machine sounds. To address these limitations, we propose a novel approach for generating diverse anomalies in machine sound using a latent diffusion-based model that integrates an encoder-decoder framework. Our method utilizes the Flan-T5 model to encode captions derived from audio file metadata, enabling conditional generation through a carefully designed U-Net architecture. This approach aids our model in generating audio signals within the EnCodec latent space, ensuring high contextual relevance and quality. We objectively evaluated the quality of our generated sounds using the Fr'echet Audio Distance (FAD) score and other metrics, demonstrating that our approach surpasses existing models in generating reliable machine audio that closely resembles actual abnormal conditions. The evaluation of the anomaly detection system using our generated data revealed a strong correlation, with the area under the curve (AUC) score differing by 4.8% from the original, validating the effectiveness of our generated data. These results demonstrate the potential of our approach to enhance the evaluation and robustness of anomaly detection systems across varied and previously unseen conditions. Audio samples can be found at url{https://hpworkhub.github.io/MIMII-Gen.github.io/}.
Read more9/30/2024

0
FakeSound: Deepfake General Audio Detection
Zeyu Xie, Baihan Li, Xuenan Xu, Zheng Liang, Kai Yu, Mengyue Wu
With the advancement of audio generation, generative models can produce highly realistic audios. However, the proliferation of deepfake general audio can pose negative consequences. Therefore, we propose a new task, deepfake general audio detection, which aims to identify whether audio content is manipulated and to locate deepfake regions. Leveraging an automated manipulation pipeline, a dataset named FakeSound for deepfake general audio detection is proposed, and samples can be viewed on website https://FakeSoundData.github.io. The average binary accuracy of humans on all test sets is consistently below 0.6, which indicates the difficulty humans face in discerning deepfake audio and affirms the efficacy of the FakeSound dataset. A deepfake detection model utilizing a general audio pre-trained model is proposed as a benchmark system. Experimental results demonstrate that the performance of the proposed model surpasses the state-of-the-art in deepfake speech detection and human testers.
Read more6/13/2024

0
Targeted Augmented Data for Audio Deepfake Detection
Marcella Astrid, Enjie Ghorbel, Djamila Aouada
The availability of highly convincing audio deepfake generators highlights the need for designing robust audio deepfake detectors. Existing works often rely solely on real and fake data available in the training set, which may lead to overfitting, thereby reducing the robustness to unseen manipulations. To enhance the generalization capabilities of audio deepfake detectors, we propose a novel augmentation method for generating audio pseudo-fakes targeting the decision boundary of the model. Inspired by adversarial attacks, we perturb original real data to synthesize pseudo-fakes with ambiguous prediction probabilities. Comprehensive experiments on two well-known architectures demonstrate that the proposed augmentation contributes to improving the generalization capabilities of these architectures.
Read more7/11/2024
0
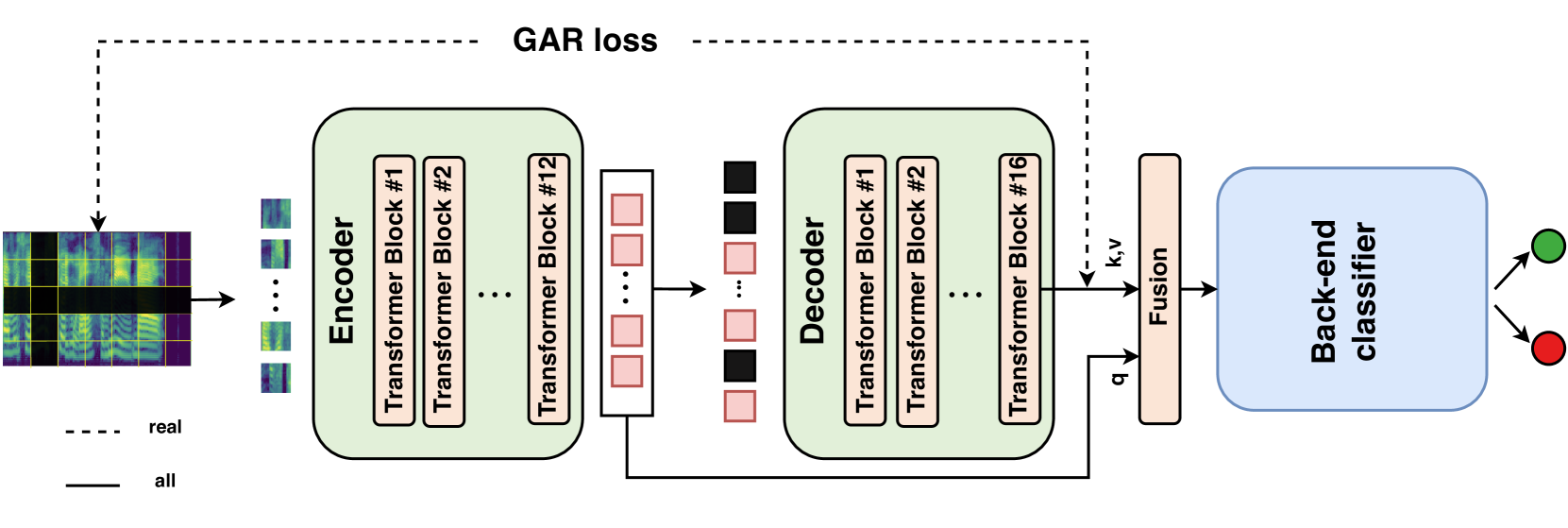
Genuine-Focused Learning using Mask AutoEncoder for Generalized Fake Audio Detection
Xiaopeng Wang, Ruibo Fu, Zhengqi Wen, Zhiyong Wang, Yuankun Xie, Yukun Liu, Jianhua Tao, Xuefei Liu, Yongwei Li, Xin Qi, Yi Lu, Shuchen Shi
The generalization of Fake Audio Detection (FAD) is critical due to the emergence of new spoofing techniques. Traditional FAD methods often focus solely on distinguishing between genuine and known spoofed audio. We propose a Genuine-Focused Learning (GFL) framework guided, aiming for highly generalized FAD, called GFL-FAD. This method incorporates a Counterfactual Reasoning Enhanced Representation (CRER) based on audio reconstruction using the Mask AutoEncoder (MAE) architecture to accurately model genuine audio features. To reduce the influence of spoofed audio during training, we introduce a genuine audio reconstruction loss, maintaining the focus on learning genuine data features. In addition, content-related bottleneck (BN) features are extracted from the MAE to supplement the knowledge of the original audio. These BN features are adaptively fused with CRER to further improve robustness. Our method achieves state-of-the-art performance with an EER of 0.25% on ASVspoof2019 LA.
Read more6/11/2024