MInD: Improving Multimodal Sentiment Analysis via Multimodal Information Disentanglement

0
📊
Sign in to get full access
Overview
- Researchers propose a new method called Multi-modal Information Disentanglement (MInD) for multi-modal sentiment analysis.
- Previous work focused on advanced fusion techniques, but the inherent differences between modalities like text, audio, and video remain a challenge.
- MInD aims to address this by decomposing multi-modal inputs into modality-invariant and modality-specific components.
- This disentangled representation allows for simpler fusion and improved performance on benchmark tasks.
Plain English Explanation
The paper introduces a new approach called MInD to address a key challenge in multi-modal sentiment analysis. Previous methods have tried complicated techniques to combine information from different sources like text, audio, and video. However, the fundamental differences between these modalities make it difficult to effectively fuse the data.
The MInD method takes a different approach. It breaks down the multi-modal inputs into two key components: one that is shared across all modalities, and one that is specific to each individual modality. This "disentanglement" allows the system to more easily combine the relevant information from each source, leading to better performance on tasks like emotion recognition and humor detection.
The key insight is that by separating the shared and unique aspects of each modality, the model can focus on what's most important for the task at hand, rather than getting bogged down in irrelevant differences between the data sources. This simpler fusion process outperforms more complex alternatives on standard benchmarks.
Technical Explanation
The MInD method tackles the challenge of learning effective joint representations for multi-modal sentiment analysis. Previous work has explored advanced fusion techniques, but the inherent heterogeneity between modalities like text, audio, and video remains a core issue.
MInD decomposes the multi-modal inputs into modality-invariant and modality-specific components using a shared encoder and multiple private encoders. This disentangled representation allows for a simpler fusion process compared to alternative methods, while still fully exploiting the multi-modal information.
Furthermore, MInD explicitly trains generated noise in an adversarial manner to isolate uninformative aspects of the data. This helps improve the quality of the learned representations.
Experiments on emotion recognition and humor detection tasks demonstrate the effectiveness of MInD compared to previous approaches.
Critical Analysis
The paper makes a compelling case for the MInD method and its advantages over prior work. However, there are a few potential areas for further exploration:
-
Generalizability: While the experiments show strong performance on the tested datasets, it would be valuable to evaluate MInD on a wider range of multi-modal sentiment analysis tasks to assess its broader applicability.
-
Interpretability: The paper does not provide much insight into what the modality-invariant and modality-specific components actually represent. Exploring the interpretability of these disentangled representations could lead to additional insights.
-
Real-world Deployment: The authors mention plans to release the code, which will be important for enabling further research and potential real-world applications. Practical considerations around deployment, such as computational cost and robustness to noisy or missing data, could be investigated.
Overall, the MInD approach represents a promising step forward in addressing the challenges of multi-modal sentiment analysis. The disentangled representation learning technique could have broader implications for other multi-modal learning problems as well.
Conclusion
The paper introduces a novel Multi-modal Information Disentanglement (MInD) method to address the challenge of learning effective joint representations for multi-modal sentiment analysis. By decomposing the multi-modal inputs into modality-invariant and modality-specific components, MInD enables a simpler fusion process that outperforms previous sophisticated techniques on benchmark tasks.
This disentangled representation learning approach could have significant implications for a wide range of multi-modal learning applications, from emotion recognition to humor detection. Further research to explore the generalizability, interpretability, and real-world deployment of MInD could lead to valuable advancements in the field of multi-modal sentiment analysis and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
MInD: Improving Multimodal Sentiment Analysis via Multimodal Information Disentanglement
Weichen Dai, Xingyu Li, Zeyu Wang, Pengbo Hu, Ji Qi, Jianlin Peng, Yi Zhou
Learning effective joint representations has been a central task in multi-modal sentiment analysis. Previous works addressing this task focus on exploring sophisticated fusion techniques to enhance performance. However, the inherent heterogeneity of distinct modalities remains a core problem that brings challenges in fusing and coordinating the multi-modal signals at both the representational level and the informational level, impeding the full exploitation of multi-modal information. To address this problem, we propose the Multi-modal Information Disentanglement (MInD) method, which decomposes the multi-modal inputs into modality-invariant and modality-specific components through a shared encoder and multiple private encoders. Furthermore, by explicitly training generated noise in an adversarial manner, MInD is able to isolate uninformativeness, thus improves the learned representations. Therefore, the proposed disentangled decomposition allows for a fusion process that is simpler than alternative methods and results in improved performance. Experimental evaluations conducted on representative benchmark datasets demonstrate MInD's effectiveness in both multi-modal emotion recognition and multi-modal humor detection tasks. Code will be released upon acceptance of the paper.
Read more8/20/2024

0
Robust Temporal-Invariant Learning in Multimodal Disentanglement
Guoyang Xu, Junqi Xue, Yuxin Liu, Zirui Wang, Min Zhang, Zhenxi Song, Zhiguo Zhang
Multimodal sentiment analysis aims to learn representations from different modalities to identify human emotions. However, existing works often neglect the frame-level redundancy inherent in continuous time series, resulting in incomplete modality representations with noise. To address this issue, we propose temporal-invariant learning for the first time, which constrains the distributional variations over time steps to effectively capture long-term temporal dynamics, thus enhancing the quality of the representations and the robustness of the model. To fully exploit the rich semantic information in textual knowledge, we propose a semantic-guided fusion module. By evaluating the correlations between different modalities, this module facilitates cross-modal interactions gated by modality-invariant representations. Furthermore, we introduce a modality discriminator to disentangle modality-invariant and modality-specific subspaces. Experimental results on two public datasets demonstrate the superiority of our model. Our code is available at https://github.com/X-G-Y/SATI.
Read more9/12/2024
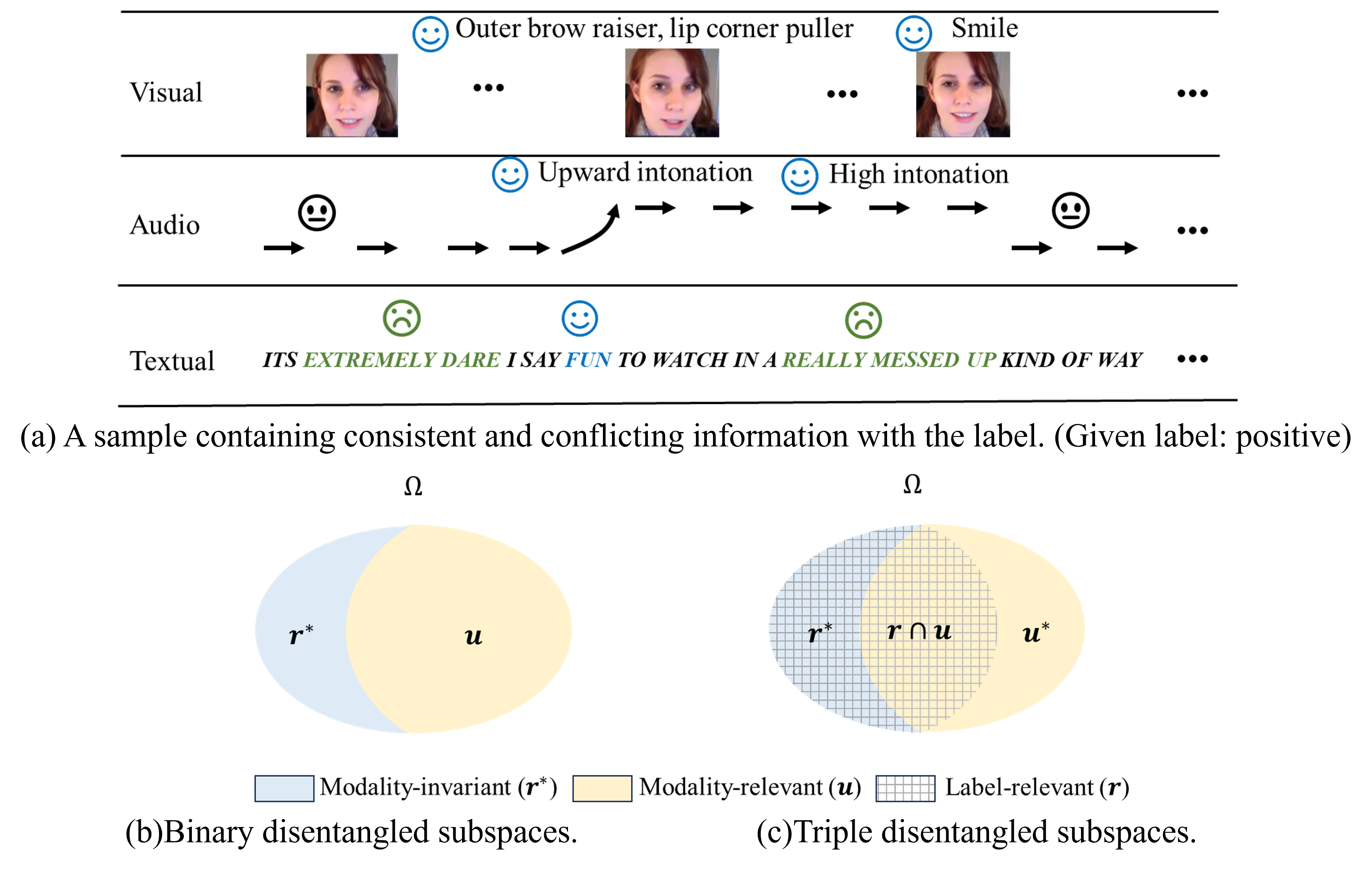
0
Triple Disentangled Representation Learning for Multimodal Affective Analysis
Ying Zhou, Xuefeng Liang, Han Chen, Yin Zhao, Xin Chen, Lida Yu
Multimodal learning has exhibited a significant advantage in affective analysis tasks owing to the comprehensive information of various modalities, particularly the complementary information. Thus, many emerging studies focus on disentangling the modality-invariant and modality-specific representations from input data and then fusing them for prediction. However, our study shows that modality-specific representations may contain information that is irrelevant or conflicting with the tasks, which downgrades the effectiveness of learned multimodal representations. We revisit the disentanglement issue, and propose a novel triple disentanglement approach, TriDiRA, which disentangles the modality-invariant, effective modality-specific and ineffective modality-specific representations from input data. By fusing only the modality-invariant and effective modality-specific representations, TriDiRA can significantly alleviate the impact of irrelevant and conflicting information across modalities during model training. Extensive experiments conducted on four benchmark datasets demonstrate the effectiveness and generalization of our triple disentanglement, which outperforms SOTA methods.
Read more4/9/2024
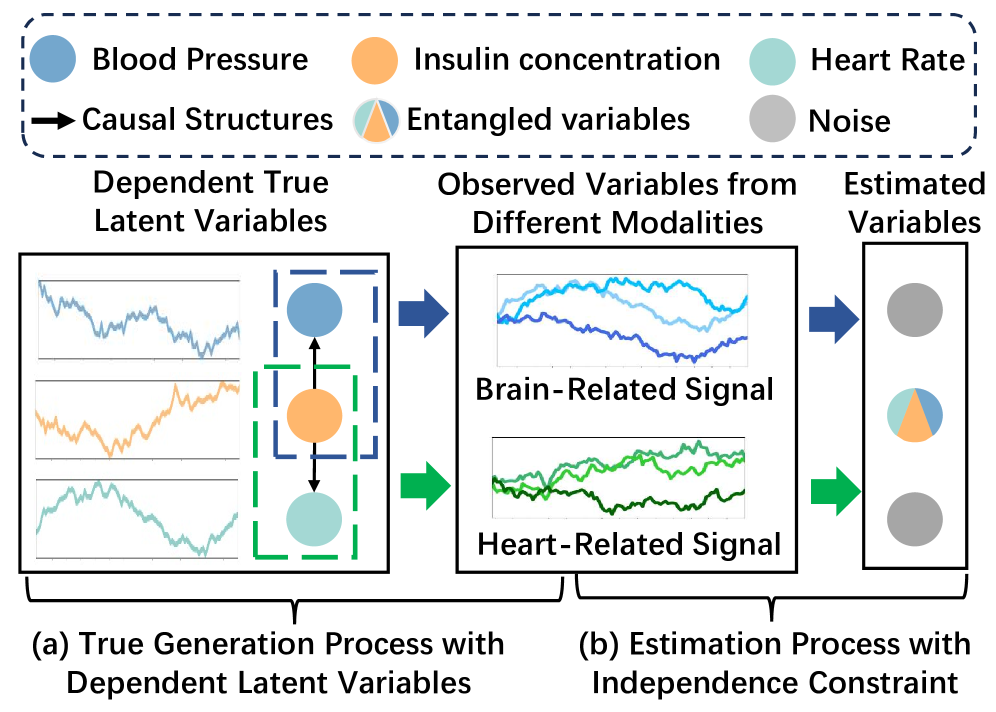
0
From Orthogonality to Dependency: Learning Disentangled Representation for Multi-Modal Time-Series Sensing Signals
Ruichu Cai, Zhifang Jiang, Zijian Li, Weilin Chen, Xuexin Chen, Zhifeng Hao, Yifan Shen, Guangyi Chen, Kun Zhang
Existing methods for multi-modal time series representation learning aim to disentangle the modality-shared and modality-specific latent variables. Although achieving notable performances on downstream tasks, they usually assume an orthogonal latent space. However, the modality-specific and modality-shared latent variables might be dependent on real-world scenarios. Therefore, we propose a general generation process, where the modality-shared and modality-specific latent variables are dependent, and further develop a textbf{M}ulti-modtextbf{A}l textbf{TE}mporal Disentanglement (textbf{MATE}) model. Specifically, our textbf{MATE} model is built on a temporally variational inference architecture with the modality-shared and modality-specific prior networks for the disentanglement of latent variables. Furthermore, we establish identifiability results to show that the extracted representation is disentangled. More specifically, we first achieve the subspace identifiability for modality-shared and modality-specific latent variables by leveraging the pairing of multi-modal data. Then we establish the component-wise identifiability of modality-specific latent variables by employing sufficient changes of historical latent variables. Extensive experimental studies on multi-modal sensors, human activity recognition, and healthcare datasets show a general improvement in different downstream tasks, highlighting the effectiveness of our method in real-world scenarios.
Read more5/28/2024