Minimax Optimality of Score-based Diffusion Models: Beyond the Density Lower Bound Assumptions

0

Sign in to get full access
Overview
- The research paper analyzes the theoretical properties of score-based diffusion models, a type of generative model.
- It shows that these models can achieve minimax optimality, a desirable statistical property, without needing to make assumptions about the density lower bound.
- The paper provides new insights into the capabilities and limitations of score-based diffusion models.
Plain English Explanation
Score-based diffusion models are a class of machine learning models that can generate new data (like images or text) by learning from existing data. These models have shown impressive capabilities in generating high-quality and diverse samples.
The key idea behind score-based diffusion models is to add noise to the data in a controlled way, and then learn how to "undo" that noise to generate new samples. This process involves learning a "score function" that tells the model how to step backwards through the noising process.
Prior work had shown that score-based diffusion models can achieve a statistical property called "minimax optimality", but this required making certain assumptions about the underlying data distribution, such as a lower bound on the density.
This new research paper demonstrates that score-based diffusion models can actually achieve minimax optimality
These insights could help guide the further development and application of score-based diffusion models, for example in areas like generating high-quality synthetic data or solving complex optimization problems.
Technical Explanation
The key technical contribution of the paper is to show that score-based diffusion models can achieve minimax optimality - a desirable statistical property that means the model performs as well as the best possible model for a given task - without needing to make assumptions about the density lower bound of the data distribution.
Prior work had shown that score-based diffusion models could achieve minimax optimality, but this required assuming the data distribution had a lower bound on its density. This density lower bound assumption is quite restrictive and may not hold in many real-world scenarios.
The authors derive new theoretical results that demonstrate score-based diffusion models can still achieve minimax optimality without this density lower bound assumption. They do this by taking a fresh look at the mathematical foundations of these models and leveraging tools from high-dimensional probability theory.
Importantly, the authors also characterize the limitations of score-based diffusion models in terms of minimax optimality. They show there are certain cases, such as when the data distribution has "heavy tails", where these models may not be able to achieve the minimax optimal rate.
Overall, this work provides a more nuanced understanding of the theoretical properties of score-based diffusion models, which could help guide their future development and application in areas like generative modeling and optimization.
Critical Analysis
The paper provides a rigorous theoretical analysis of score-based diffusion models, but there are a few potential limitations and areas for further research:
-
The analysis is focused on asymptotic minimax optimality, which may not fully capture the practical performance of these models in finite-sample regimes. Further empirical evaluation would be valuable.
-
The paper does not consider the impact of architectural choices, optimization techniques, or other practical considerations that can affect the real-world performance of score-based diffusion models.
-
While the authors characterize limitations in terms of heavy-tailed distributions, there may be other data distributions or modeling scenarios where score-based diffusion models struggle to achieve minimax optimality.
-
The theoretical results rely on several technical assumptions, such as the smoothness of the score function. Relaxing these assumptions could lead to a better understanding of the model's capabilities and limitations.
Overall, this paper represents an important step forward in the theoretical understanding of score-based diffusion models. However, continued research is needed to fully elucidate their strengths, weaknesses, and the factors that influence their practical performance.
Conclusion
This research paper makes significant contributions to the theoretical understanding of score-based diffusion models, a powerful class of generative models. The key insight is that these models can achieve minimax optimality - a desirable statistical property - without needing to make restrictive assumptions about the underlying data distribution.
By providing a more nuanced characterization of the theoretical capabilities and limitations of score-based diffusion models, this work lays the groundwork for further advancements in generative modeling and optimization. The findings could help guide the development of more robust and widely applicable diffusion-based models, with potential impacts across a range of domains.
Overall, this paper represents an important step forward in the theoretical foundations of score-based diffusion models, and highlights the value of rigorous mathematical analysis in advancing the state of the art in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Minimax Optimality of Score-based Diffusion Models: Beyond the Density Lower Bound Assumptions
Kaihong Zhang, Caitlyn H. Yin, Feng Liang, Jingbo Liu
We study the asymptotic error of score-based diffusion model sampling in large-sample scenarios from a non-parametric statistics perspective. We show that a kernel-based score estimator achieves an optimal mean square error of $widetilde{O}left(n^{-1} t^{-frac{d+2}{2}}(t^{frac{d}{2}} vee 1)right)$ for the score function of $p_0*mathcal{N}(0,tboldsymbol{I}_d)$, where $n$ and $d$ represent the sample size and the dimension, $t$ is bounded above and below by polynomials of $n$, and $p_0$ is an arbitrary sub-Gaussian distribution. As a consequence, this yields an $widetilde{O}left(n^{-1/2} t^{-frac{d}{4}}right)$ upper bound for the total variation error of the distribution of the sample generated by the diffusion model under a mere sub-Gaussian assumption. If in addition, $p_0$ belongs to the nonparametric family of the $beta$-Sobolev space with $betale 2$, by adopting an early stopping strategy, we obtain that the diffusion model is nearly (up to log factors) minimax optimal. This removes the crucial lower bound assumption on $p_0$ in previous proofs of the minimax optimality of the diffusion model for nonparametric families.
Read more7/25/2024
🧠
0
From optimal score matching to optimal sampling
Zehao Dou, Subhodh Kotekal, Zhehao Xu, Harrison H. Zhou
The recent, impressive advances in algorithmic generation of high-fidelity image, audio, and video are largely due to great successes in score-based diffusion models. A key implementing step is score matching, that is, the estimation of the score function of the forward diffusion process from training data. As shown in earlier literature, the total variation distance between the law of a sample generated from the trained diffusion model and the ground truth distribution can be controlled by the score matching risk. Despite the widespread use of score-based diffusion models, basic theoretical questions concerning exact optimal statistical rates for score estimation and its application to density estimation remain open. We establish the sharp minimax rate of score estimation for smooth, compactly supported densities. Formally, given (n) i.i.d. samples from an unknown (alpha)-H{o}lder density (f) supported on ([-1, 1]), we prove the minimax rate of estimating the score function of the diffused distribution (f * mathcal{N}(0, t)) with respect to the score matching loss is (frac{1}{nt^2} wedge frac{1}{nt^{3/2}} wedge (t^{alpha-1} + n^{-2(alpha-1)/(2alpha+1)})) for all (alpha > 0) and (t ge 0). As a consequence, it is shown the law (hat{f}) of a sample generated from the diffusion model achieves the sharp minimax rate (bE(dTV(hat{f}, f)^2) lesssim n^{-2alpha/(2alpha+1)}) for all (alpha > 0) without any extraneous logarithmic terms which are prevalent in the literature, and without the need for early stopping which has been required for all existing procedures to the best of our knowledge.
Read more9/12/2024
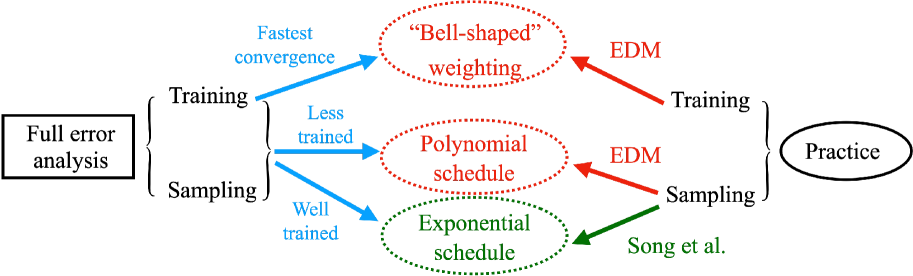
0
Evaluating the design space of diffusion-based generative models
Yuqing Wang, Ye He, Molei Tao
Most existing theoretical investigations of the accuracy of diffusion models, albeit significant, assume the score function has been approximated to a certain accuracy, and then use this a priori bound to control the error of generation. This article instead provides a first quantitative understanding of the whole generation process, i.e., both training and sampling. More precisely, it conducts a non-asymptotic convergence analysis of denoising score matching under gradient descent. In addition, a refined sampling error analysis for variance exploding models is also provided. The combination of these two results yields a full error analysis, which elucidates (again, but this time theoretically) how to design the training and sampling processes for effective generation. For instance, our theory implies a preference toward noise distribution and loss weighting in training that qualitatively agree with the ones used in [Karras et al. 2022]. It also provides perspectives on the choices of time and variance schedules in sampling: when the score is well trained, the design in [Song et al. 2020] is more preferable, but when it is less trained, the design in [Karras et al. 2022] becomes more preferable.
Read more9/10/2024
🗣️
0
On diffusion-based generative models and their error bounds: The log-concave case with full convergence estimates
Stefano Bruno, Ying Zhang, Dong-Young Lim, Omer Deniz Akyildiz, Sotirios Sabanis
We provide full theoretical guarantees for the convergence behaviour of diffusion-based generative models under the assumption of strongly log-concave data distributions while our approximating class of functions used for score estimation is made of Lipschitz continuous functions. We demonstrate via a motivating example, sampling from a Gaussian distribution with unknown mean, the powerfulness of our approach. In this case, explicit estimates are provided for the associated optimization problem, i.e. score approximation, while these are combined with the corresponding sampling estimates. As a result, we obtain the best known upper bound estimates in terms of key quantities of interest, such as the dimension and rates of convergence, for the Wasserstein-2 distance between the data distribution (Gaussian with unknown mean) and our sampling algorithm. Beyond the motivating example and in order to allow for the use of a diverse range of stochastic optimizers, we present our results using an $L^2$-accurate score estimation assumption, which crucially is formed under an expectation with respect to the stochastic optimizer and our novel auxiliary process that uses only known information. This approach yields the best known convergence rate for our sampling algorithm.
Read more4/23/2024