Mining Frequent Structures in Conceptual Models

0

Sign in to get full access
Overview
- This paper explores techniques for mining frequent structures in conceptual models, which are representations of real-world systems or processes.
- The authors propose a novel algorithm for efficiently identifying recurring patterns in conceptual models, which can provide valuable insights into the underlying structure and design of these models.
- The algorithm is evaluated on a large dataset of conceptual models, demonstrating its effectiveness in identifying meaningful patterns and its potential applications in areas such as model reuse, model quality assessment, and model-driven software development.
Plain English Explanation
Conceptual models are like diagrams or blueprints that represent how different parts of a system or process work together. These models can be quite complex, with many interconnected elements. The researchers in this paper wanted to find common patterns or structures that appear across multiple conceptual models.
Imagine you have a bunch of floor plans for different buildings. Even though the buildings may be designed for different purposes, you might notice that certain room layouts or architectural features show up in multiple plans. The researchers' algorithm is designed to identify these kinds of recurring patterns in conceptual models, similar to finding common elements across different building plans.
By identifying frequent structures in conceptual models, the researchers hope to provide insights that could be useful for reusing existing models, assessing model quality, and automating some aspects of model-driven software development. The patterns they find could highlight common design principles or best practices that modelers can apply to create more effective conceptual models.
Technical Explanation
The core of the researchers' approach is a novel algorithm for mining frequent subgraphs in a collection of conceptual models. The algorithm, called FLEXIS, uses a series of optimizations to efficiently identify frequently occurring substructures within the conceptual models.
The key steps of the FLEXIS algorithm are:
- Representing each conceptual model as a graph, where the nodes correspond to model elements (e.g., entities, relationships) and the edges represent the connections between them.
- Identifying all the maximal frequent subgraphs within the collection of model graphs. These are the largest recurring substructures that appear in multiple models.
- Applying several pruning and optimization techniques to make the subgraph mining process more efficient, such as exploiting the hierarchical nature of conceptual models and leveraging the anti-monotonic property of frequent subgraph mining.
The researchers evaluate FLEXIS on a large dataset of over 5,000 conceptual models from various domains, including business process models, database schemas, and software design models. The results demonstrate that FLEXIS can efficiently identify meaningful frequent subgraphs, which the researchers then analyze to gain insights about common design patterns and best practices in conceptual modeling.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the algorithm is designed to identify only maximal frequent subgraphs, which means it may miss some smaller, nested patterns that could also be of interest. Additionally, the current implementation of FLEXIS is limited to undirected, unlabeled graphs, whereas many conceptual models have richer semantics with directed edges and labeled nodes.
The researchers also note that the interpretation and evaluation of the mined frequent subgraphs requires significant domain knowledge and human judgment. While the algorithm can identify statistically significant patterns, determining which of these patterns are truly meaningful and valuable for modelers remains a challenge.
One area for further research could be extending the FLEXIS algorithm to handle more expressive conceptual modeling languages, such as those used in object-oriented software design or graph-based knowledge representation. Additionally, incorporating user feedback and interactive exploration of the mined patterns could help make the analysis more intuitive and practical for modelers.
Conclusion
This paper presents a novel approach for mining frequent structures in conceptual models, which can provide valuable insights into common design patterns and best practices in conceptual modeling. The proposed FLEXIS algorithm demonstrates the feasibility of efficiently identifying recurring substructures across large collections of conceptual models, with potential applications in areas such as model reuse, model quality assessment, and model-driven software development. While the current implementation has some limitations, the researchers' work lays the foundation for further advancements in this important area of conceptual modeling research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mining Frequent Structures in Conceptual Models
Mattia Fumagalli, Tiago Prince Sales, Pedro Paulo F. Barcelos, Giovanni Micale, Vadim Zaytsev, Diego Calvanese, Giancarlo Guizzardi
The problem of using structured methods to represent knowledge is well-known in conceptual modeling and has been studied for many years. It has been proven that adopting modeling patterns represents an effective structural method. Patterns are, indeed, generalizable recurrent structures that can be exploited as solutions to design problems. They aid in understanding and improving the process of creating models. The undeniable value of using patterns in conceptual modeling was demonstrated in several experimental studies. However, discovering patterns in conceptual models is widely recognized as a highly complex task and a systematic solution to pattern identification is currently lacking. In this paper, we propose a general approach to the problem of discovering frequent structures, as they occur in conceptual modeling languages. As proof of concept for our scientific contribution, we provide an implementation of the approach, by focusing on UML class diagrams, in particular OntoUML models. This implementation comprises an exploratory tool, which, through the combination of a frequent subgraph mining algorithm and graph manipulation techniques, can process multiple conceptual models and discover recurrent structures according to multiple criteria. The primary objective is to offer a support facility for language engineers. This can be employed to leverage both good and bad modeling practices, to evolve and maintain the conceptual modeling language, and to promote the reuse of encoded experience in designing better models with the given language.
Read more6/12/2024
🌀
0
Modeling Relational Patterns for Logical Query Answering over Knowledge Graphs
Yunjie He, Mojtaba Nayyeri, Bo Xiong, Yuqicheng Zhu, Evgeny Kharlamov, Steffen Staab
Answering first-order logical (FOL) queries over knowledge graphs (KG) remains a challenging task mainly due to KG incompleteness. Query embedding approaches this problem by computing the low-dimensional vector representations of entities, relations, and logical queries. KGs exhibit relational patterns such as symmetry and composition and modeling the patterns can further enhance the performance of query embedding models. However, the role of such patterns in answering FOL queries by query embedding models has not been yet studied in the literature. In this paper, we fill in this research gap and empower FOL queries reasoning with pattern inference by introducing an inductive bias that allows for learning relation patterns. To this end, we develop a novel query embedding method, RoConE, that defines query regions as geometric cones and algebraic query operators by rotations in complex space. RoConE combines the advantages of Cone as a well-specified geometric representation for query embedding, and also the rotation operator as a powerful algebraic operation for pattern inference. Our experimental results on several benchmark datasets confirm the advantage of relational patterns for enhancing logical query answering task.
Read more7/18/2024

0
Learning Discrete Concepts in Latent Hierarchical Models
Lingjing Kong, Guangyi Chen, Biwei Huang, Eric P. Xing, Yuejie Chi, Kun Zhang
Learning concepts from natural high-dimensional data (e.g., images) holds potential in building human-aligned and interpretable machine learning models. Despite its encouraging prospect, formalization and theoretical insights into this crucial task are still lacking. In this work, we formalize concepts as discrete latent causal variables that are related via a hierarchical causal model that encodes different abstraction levels of concepts embedded in high-dimensional data (e.g., a dog breed and its eye shapes in natural images). We formulate conditions to facilitate the identification of the proposed causal model, which reveals when learning such concepts from unsupervised data is possible. Our conditions permit complex causal hierarchical structures beyond latent trees and multi-level directed acyclic graphs in prior work and can handle high-dimensional, continuous observed variables, which is well-suited for unstructured data modalities such as images. We substantiate our theoretical claims with synthetic data experiments. Further, we discuss our theory's implications for understanding the underlying mechanisms of latent diffusion models and provide corresponding empirical evidence for our theoretical insights.
Read more6/4/2024
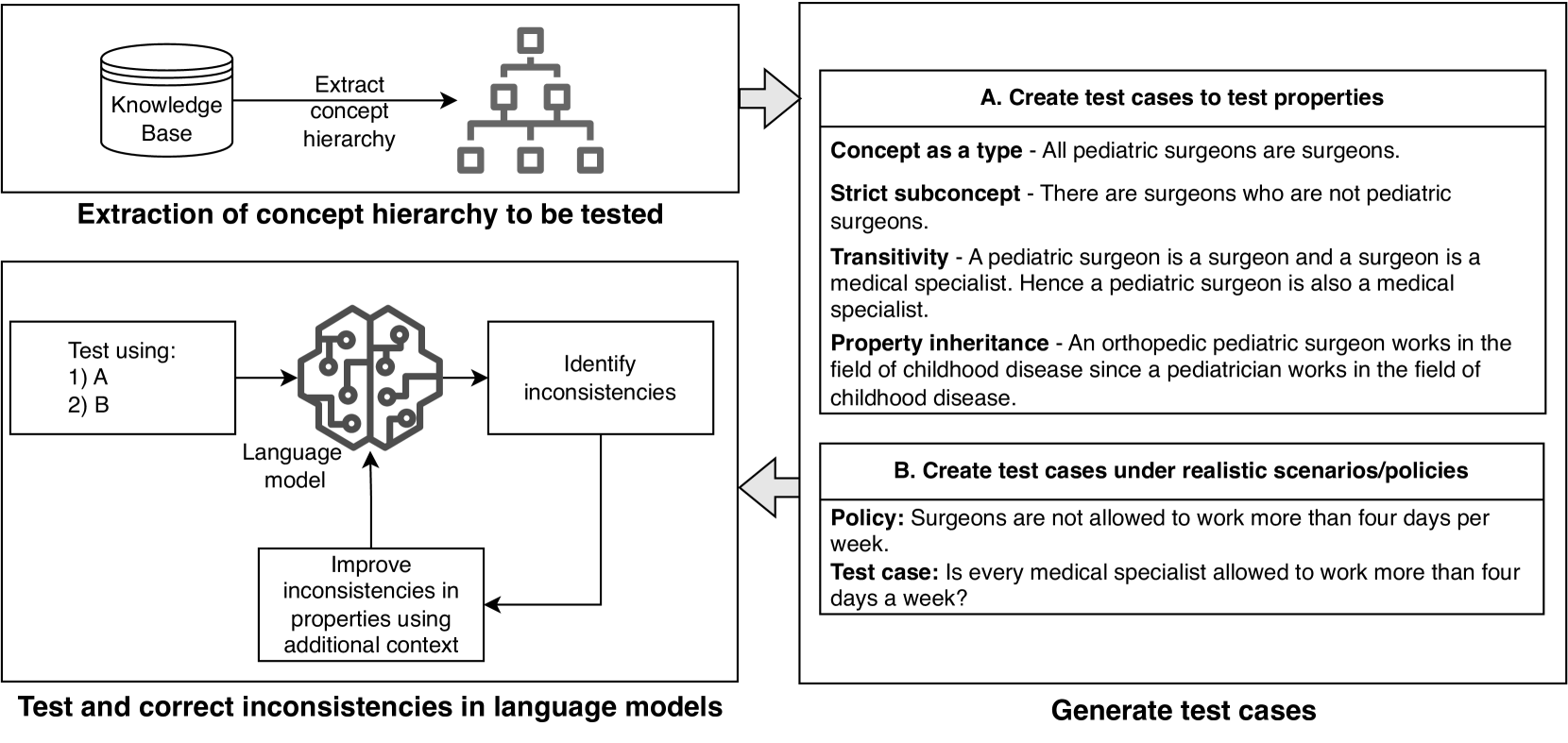
0
Reasoning about concepts with LLMs: Inconsistencies abound
Rosario Uceda-Sosa, Karthikeyan Natesan Ramamurthy, Maria Chang, Moninder Singh
The ability to summarize and organize knowledge into abstract concepts is key to learning and reasoning. Many industrial applications rely on the consistent and systematic use of concepts, especially when dealing with decision-critical knowledge. However, we demonstrate that, when methodically questioned, large language models (LLMs) often display and demonstrate significant inconsistencies in their knowledge. Computationally, the basic aspects of the conceptualization of a given domain can be represented as Is-A hierarchies in a knowledge graph (KG) or ontology, together with a few properties or axioms that enable straightforward reasoning. We show that even simple ontologies can be used to reveal conceptual inconsistencies across several LLMs. We also propose strategies that domain experts can use to evaluate and improve the coverage of key domain concepts in LLMs of various sizes. In particular, we have been able to significantly enhance the performance of LLMs of various sizes with openly available weights using simple knowledge-graph (KG) based prompting strategies.
Read more5/31/2024