Learning Discrete Concepts in Latent Hierarchical Models

0

Sign in to get full access
Overview
- This paper explores how to learn discrete concepts in latent hierarchical models, which are a type of machine learning model that can capture complex, structured relationships in data.
- The authors propose a new approach to discover and represent these discrete concepts in a more interpretable way, which could be useful for tasks like language understanding or image recognition.
- The key ideas involve using a combination of unsupervised and supervised learning techniques to discover and refine these discrete concepts in the latent representations of the model.
Plain English Explanation
The paper is about a new way to build machine learning models that can understand and represent complex, structured information in a more interpretable way. These models, called "latent hierarchical models", are designed to discover hidden patterns and concepts in data, similar to how the human brain works.
The main challenge is that these models often learn very abstract, continuous representations that can be hard for humans to interpret. The researchers in this paper propose a method to instead learn more discrete, distinct concepts that are easier to understand. This could be useful for applications like language understanding or image recognition, where being able to explain the model's reasoning is important.
The key idea is to use a combination of unsupervised learning, to discover the underlying concepts in an open-ended way, and supervised learning, to refine and organize those concepts in a more structured way. This allows the model to both discover relevant concepts on its own, and then shape those concepts to be more aligned with human understanding.
Overall, this work aims to make complex machine learning models more transparent and interpretable, which could lead to better human-AI collaboration and trust. It builds on prior research in causal representation learning and discovering latent concepts, showing how to apply these ideas to structured, hierarchical data models.
Technical Explanation
The paper proposes a new method for learning discrete, interpretable concepts within the context of latent hierarchical models. These models have a multi-layered structure that allows them to capture complex, structured relationships in data, but this complexity can also make the internal representations difficult to interpret.
The key contribution is a two-stage training approach that combines unsupervised and supervised learning. First, an unsupervised module discovers a set of discrete latent concepts that can explain the observed data. This uses techniques like vector quantization to cluster the continuous latent representations into distinct concepts.
Second, a supervised module then takes these discovered concepts and further refines them to align with task-specific objectives. This allows the model to shape the discrete concepts to be more relevant and interpretable for the target application, drawing on ideas from causal representation learning and latent variable discovery.
Experiments on both language and image datasets demonstrate the effectiveness of this approach at learning more interpretable, hierarchical concept representations compared to standard latent variable models. The authors also provide analyses showing how the discovered concepts align with human intuitions and can be leveraged for downstream tasks.
Critical Analysis
The paper presents a compelling approach for learning more interpretable representations in complex latent hierarchical models. The two-stage training process of unsupervised concept discovery followed by supervised refinement seems like an effective way to balance the flexibility of open-ended concept learning with the guidance of task-specific objectives.
However, one potential limitation is that the method still relies on some degree of human supervision in the second stage. While this allows the model to align the concepts with human understanding, it may limit the model's ability to discover novel or unexpected concepts that diverge from typical human intuitions. An interesting direction for future work could be to explore more fully unsupervised approaches to hierarchical concept learning.
Additionally, the paper focuses primarily on evaluating the quality and interpretability of the learned representations, but does not extensively explore the downstream task performance or real-world applications of this approach. Further research is needed to understand how these interpretable concepts can be leveraged to improve model robustness, transferability, or other practical benefits.
Overall, this work represents an important step towards building more transparent and explainable machine learning models, which is a crucial challenge for the broader adoption and trust in these technologies. The principles of combining unsupervised and supervised learning to discover and refine interpretable concepts could have wide-ranging implications across many AI application domains.
Conclusion
This paper introduces a new method for learning discrete, interpretable concepts within latent hierarchical models. By combining unsupervised discovery of concepts with supervised refinement, the approach can capture complex, structured relationships in data while producing representations that are more aligned with human understanding.
The key contributions include the two-stage training process, the use of vector quantization to discover discrete concepts, and the integration of causal and interpretability principles. Experiments demonstrate the effectiveness of this approach on both language and image data, suggesting broad applicability.
While the paper focuses primarily on the quality and interpretability of the learned representations, further research is needed to fully explore the downstream benefits and real-world applications of this work. Nonetheless, this research represents an important step towards building more transparent and trustworthy AI systems that can better collaborate with and be understood by humans.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Discrete Concepts in Latent Hierarchical Models
Lingjing Kong, Guangyi Chen, Biwei Huang, Eric P. Xing, Yuejie Chi, Kun Zhang
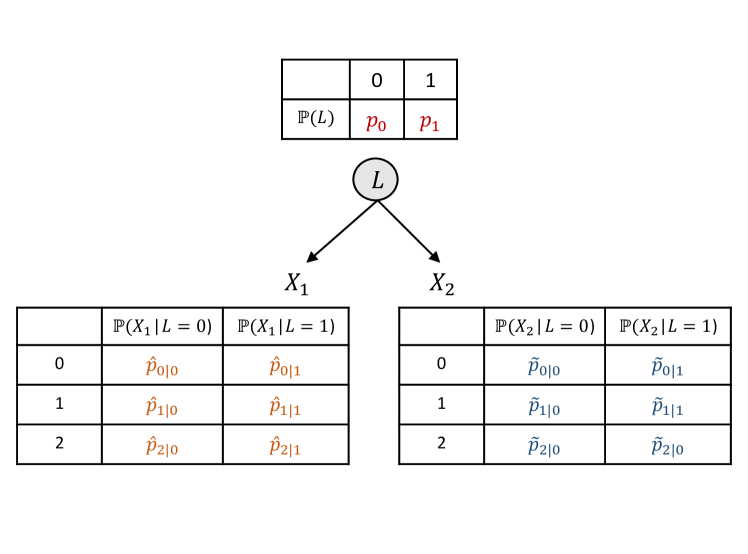
Learning concepts from natural high-dimensional data (e.g., images) holds potential in building human-aligned and interpretable machine learning models. Despite its encouraging prospect, formalization and theoretical insights into this crucial task are still lacking. In this work, we formalize concepts as discrete latent causal variables that are related via a hierarchical causal model that encodes different abstraction levels of concepts embedded in high-dimensional data (e.g., a dog breed and its eye shapes in natural images). We formulate conditions to facilitate the identification of the proposed causal model, which reveals when learning such concepts from unsupervised data is possible. Our conditions permit complex causal hierarchical structures beyond latent trees and multi-level directed acyclic graphs in prior work and can handle high-dimensional, continuous observed variables, which is well-suited for unstructured data modalities such as images. We substantiate our theoretical claims with synthetic data experiments. Further, we discuss our theory's implications for understanding the underlying mechanisms of latent diffusion models and provide corresponding empirical evidence for our theoretical insights.
Read more6/4/2024

3
The Geometry of Categorical and Hierarchical Concepts in Large Language Models
Kiho Park, Yo Joong Choe, Yibo Jiang, Victor Veitch
Understanding how semantic meaning is encoded in the representation spaces of large language models is a fundamental problem in interpretability. In this paper, we study the two foundational questions in this area. First, how are categorical concepts, such as {'mammal', 'bird', 'reptile', 'fish'}, represented? Second, how are hierarchical relations between concepts encoded? For example, how is the fact that 'dog' is a kind of 'mammal' encoded? We show how to extend the linear representation hypothesis to answer these questions. We find a remarkably simple structure: simple categorical concepts are represented as simplices, hierarchically related concepts are orthogonal in a sense we make precise, and (in consequence) complex concepts are represented as polytopes constructed from direct sums of simplices, reflecting the hierarchical structure. We validate these theoretical results on the Gemma large language model, estimating representations for 957 hierarchically related concepts using data from WordNet.
Read more6/4/2024
0
Learning Discrete Latent Variable Structures with Tensor Rank Conditions
Zhengming Chen, Ruichu Cai, Feng Xie, Jie Qiao, Anpeng Wu, Zijian Li, Zhifeng Hao, Kun Zhang
Unobserved discrete data are ubiquitous in many scientific disciplines, and how to learn the causal structure of these latent variables is crucial for uncovering data patterns. Most studies focus on the linear latent variable model or impose strict constraints on latent structures, which fail to address cases in discrete data involving non-linear relationships or complex latent structures. To achieve this, we explore a tensor rank condition on contingency tables for an observed variable set $mathbf{X}_p$, showing that the rank is determined by the minimum support of a specific conditional set (not necessary in $mathbf{X}_p$) that d-separates all variables in $mathbf{X}_p$. By this, one can locate the latent variable through probing the rank on different observed variables set, and further identify the latent causal structure under some structure assumptions. We present the corresponding identification algorithm and conduct simulated experiments to verify the effectiveness of our method. In general, our results elegantly extend the identification boundary for causal discovery with discrete latent variables and expand the application scope of causal discovery with latent variables.
Read more6/12/2024
0
Causal Representation Learning from Multiple Distributions: A General Setting
Kun Zhang, Shaoan Xie, Ignavier Ng, Yujia Zheng
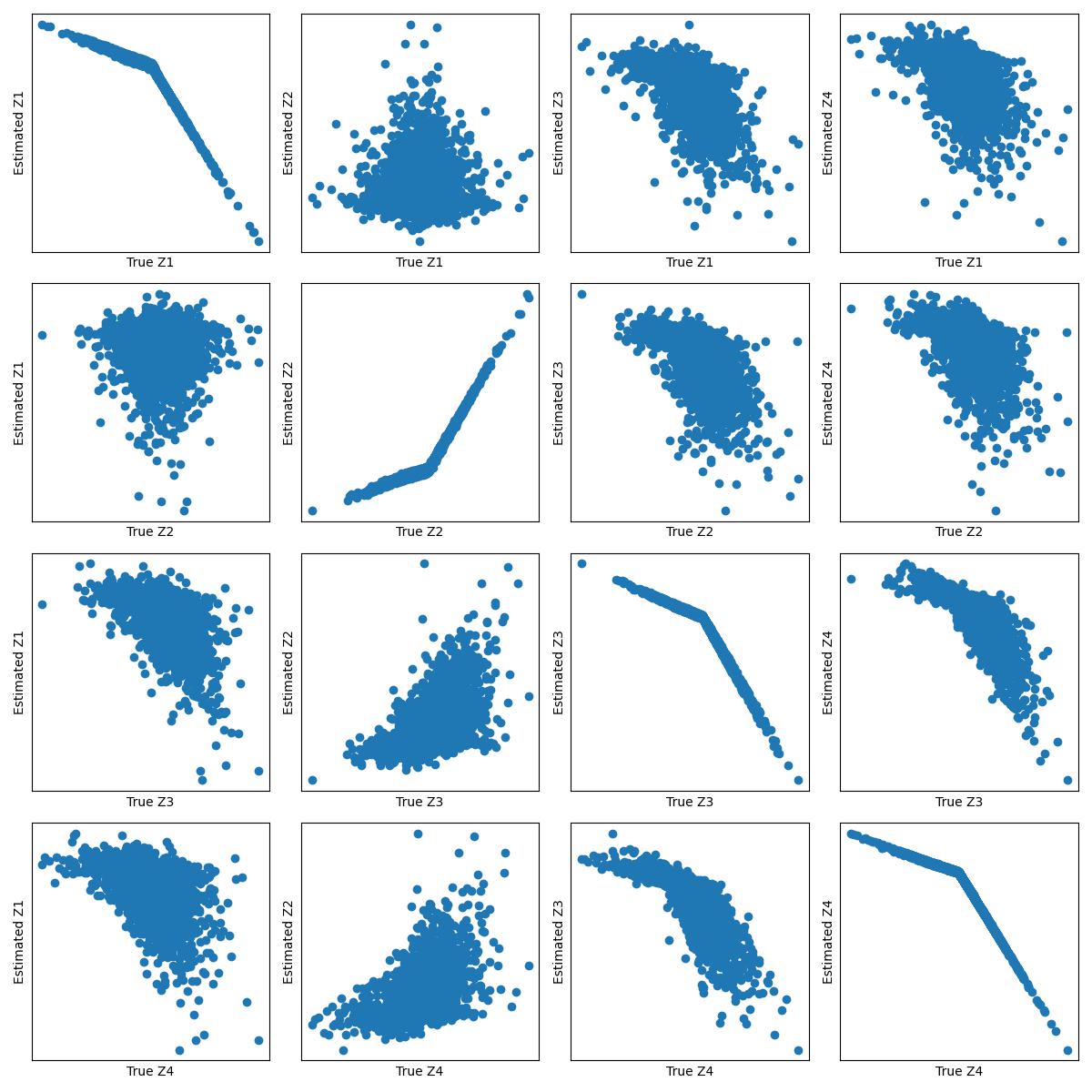
In many problems, the measured variables (e.g., image pixels) are just mathematical functions of the latent causal variables (e.g., the underlying concepts or objects). For the purpose of making predictions in changing environments or making proper changes to the system, it is helpful to recover the latent causal variables $Z_i$ and their causal relations represented by graph $mathcal{G}_Z$. This problem has recently been known as causal representation learning. This paper is concerned with a general, completely nonparametric setting of causal representation learning from multiple distributions (arising from heterogeneous data or nonstationary time series), without assuming hard interventions behind distribution changes. We aim to develop general solutions in this fundamental case; as a by product, this helps see the unique benefit offered by other assumptions such as parametric causal models or hard interventions. We show that under the sparsity constraint on the recovered graph over the latent variables and suitable sufficient change conditions on the causal influences, interestingly, one can recover the moralized graph of the underlying directed acyclic graph, and the recovered latent variables and their relations are related to the underlying causal model in a specific, nontrivial way. In some cases, most latent variables can even be recovered up to component-wise transformations. Experimental results verify our theoretical claims.
Read more8/13/2024