MINT: Boosting Audio-Language Model via Multi-Target Pre-Training and Instruction Tuning

0
📈
Sign in to get full access
Overview
- This paper presents MINT, a novel audio-language pre-training (ALP) framework that aims to improve the cross-modal alignment and generalization capabilities of audio-language models.
- The key challenges addressed are the modality gap between audio and language inputs, as well as the need for developing generic audio-language models that can perform well on diverse tasks.
- To address these challenges, MINT leverages the strengths of frozen pre-trained audio encoders and large language models (LLMs), and introduces a trainable module called Bridge-Net to enhance cross-modality alignment and task-specific instruction following.
Plain English Explanation
MINT is a new way of training audio-language models to make them better at understanding and generating language based on audio inputs. Audio and language are quite different, so it can be hard to get these models to work well across both modalities.
MINT tackles this by using pre-trained models that are already good at processing audio and language separately. It then adds a special "bridge" component that helps the model align the audio and language parts more effectively. This allows the model to learn better representations that work for both audio and text.
Additionally, MINT trains the model to follow specific instructions for different tasks, like answering questions or generating text based on audio. This makes the model more flexible and able to adapt to a variety of real-world applications, even when faced with new tasks it hasn't seen before.
Technical Explanation
The paper introduces the MINT framework, which consists of two key components:
-
Leveraging Frozen Pre-trained Models: MINT uses pre-trained audio encoders and large language models (LLMs) as a foundation, taking advantage of their strong performance in their respective modalities. This allows MINT to build upon well-established model capabilities rather than starting from scratch.
-
Bridge-Net: MINT introduces a trainable module called Bridge-Net that acts as a "bridge" between the audio and language representations. Bridge-Net enhances the cross-modal alignment and the model's ability to follow task-specific instructions. It is trained through a multi-target pre-training approach and further boosted by integrating a frozen LLM with instruction tuning.
The multi-target pre-training in MINT involves jointly optimizing the model for audio-text understanding and generation tasks, which helps the model learn more generic and transferable representations. The instruction tuning then fine-tunes the model to be adept at following specific task instructions, enabling it to adapt to a wide range of audio-language applications.
Experimental results demonstrate that MINT outperforms previous state-of-the-art models on various audio-language understanding and generation tasks, including in zero-shot scenarios where the model is tested on new tasks it hasn't seen before.
Critical Analysis
The paper presents a comprehensive and well-designed approach to improving audio-language pre-training, addressing key challenges in this domain. The authors provide a thorough technical explanation of the MINT framework and its components, which seems well-grounded in existing research.
One potential area for further exploration is the impact of the specific pre-trained models used as the foundation for MINT. The performance gains may be heavily dependent on the quality and capabilities of the audio encoders and LLMs employed. Investigating the sensitivity of MINT's performance to different pre-trained models could yield valuable insights.
Additionally, while the paper demonstrates MINT's strong performance on a range of tasks, it would be interesting to see more analysis on the model's limitations or failure cases. Understanding the types of audio-language scenarios where MINT struggles could guide future research directions and model improvements.
Conclusion
The MINT framework presented in this paper represents a significant advancement in audio-language pre-training. By leveraging the strengths of frozen pre-trained models and introducing the Bridge-Net module, MINT is able to achieve superior performance on both audio-text understanding and generation tasks, even in zero-shot settings.
This research highlights the importance of cross-modal alignment and task-specific instruction following in developing generic and adaptable audio-language models. The insights and techniques employed in MINT could have far-reaching implications for a wide range of applications, from voice assistants and language learning to multimodal content generation and understanding.
As the field of audio-language AI continues to evolve, the MINT framework provides a compelling and innovative approach to address the challenges of this rapidly advancing domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
MINT: Boosting Audio-Language Model via Multi-Target Pre-Training and Instruction Tuning
Hang Zhao, Yifei Xin, Zhesong Yu, Bilei Zhu, Lu Lu, Zejun Ma
In the realm of audio-language pre-training (ALP), the challenge of achieving cross-modal alignment is significant. Moreover, the integration of audio inputs with diverse distributions and task variations poses challenges in developing generic audio-language models. In this study, we present MINT, a novel ALP framework boosting audio-language models through multi-target pre-training and instruction tuning. MINT leverages the strength of frozen pre-trained audio encoders and large language models (LLM) to improve audio-language pre-training, enabling effective transferablility to both audio-text understanding and generation tasks. To address the modality gap, we introduce Bridge-Net, a trainable module that enhances cross-modality alignment and the model's ability to follow instructions for a variety of audio-text tasks. Bridge-Net is pivotal within MINT, initially enhancing audio-language representation learning through a multi-target pre-training approach. Subsequently, Bridge-Net further boosts audio-to-language generative learning by integrating a frozen language model with instruction tuning. This integration empowers MINT to extract features in a flexible and effective manner, specifically tailored to the provided instructions for diverse tasks. Experimental results demonstrate that MINT attains superior performance across various audio-language understanding and generation tasks, highlighting its robust generalization capabilities even in zero-shot scenarios.
Read more6/13/2024

0
MINT: a Multi-modal Image and Narrative Text Dubbing Dataset for Foley Audio Content Planning and Generation
Ruibo Fu, Shuchen Shi, Hongming Guo, Tao Wang, Chunyu Qiang, Zhengqi Wen, Jianhua Tao, Xin Qi, Yi Lu, Xiaopeng Wang, Zhiyong Wang, Yukun Liu, Xuefei Liu, Shuai Zhang, Guanjun Li
Foley audio, critical for enhancing the immersive experience in multimedia content, faces significant challenges in the AI-generated content (AIGC) landscape. Despite advancements in AIGC technologies for text and image generation, the foley audio dubbing remains rudimentary due to difficulties in cross-modal scene matching and content correlation. Current text-to-audio technology, which relies on detailed and acoustically relevant textual descriptions, falls short in practical video dubbing applications. Existing datasets like AudioSet, AudioCaps, Clotho, Sound-of-Story, and WavCaps do not fully meet the requirements for real-world foley audio dubbing task. To address this, we introduce the Multi-modal Image and Narrative Text Dubbing Dataset (MINT), designed to enhance mainstream dubbing tasks such as literary story audiobooks dubbing, image/silent video dubbing. Besides, to address the limitations of existing TTA technology in understanding and planning complex prompts, a Foley Audio Content Planning, Generation, and Alignment (CPGA) framework is proposed, which includes a content planning module leveraging large language models for complex multi-modal prompts comprehension. Additionally, the training process is optimized using Proximal Policy Optimization based reinforcement learning, significantly improving the alignment and auditory realism of generated foley audio. Experimental results demonstrate that our approach significantly advances the field of foley audio dubbing, providing robust solutions for the challenges of multi-modal dubbing. Even when utilizing the relatively lightweight GPT-2 model, our framework outperforms open-source multimodal large models such as LLaVA, DeepSeek-VL, and Moondream2. The dataset is available at https://github.com/borisfrb/MINT .
Read more6/18/2024
🤖
0
Enhancing Audio-Language Models through Self-Supervised Post-Training with Text-Audio Pairs
Anshuman Sinha, Camille Migozzi, Aubin Rey, Chao Zhang
Research on multi-modal contrastive learning strategies for audio and text has rapidly gained interest. Contrastively trained Audio-Language Models (ALMs), such as CLAP, which establish a unified representation across audio and language modalities, have enhanced the efficacy in various subsequent tasks by providing good text aligned audio encoders and vice versa. These improvements are evident in areas like zero-shot audio classification and audio retrieval, among others. However, the ability of these models to understand natural language and temporal relations is still a largely unexplored and open field for research. In this paper, we propose to equip the multi-modal ALMs with temporal understanding without loosing their inherent prior capabilities of audio-language tasks with a temporal instillation method TeminAL. We implement a two-stage training scheme TeminAL A $&$ B, where the model first learns to differentiate between multiple sounds in TeminAL A, followed by a phase that instills a sense of time, thereby enhancing its temporal understanding in TeminAL B. This approach results in an average performance gain of $5.28%$ in temporal understanding on the ESC-50 dataset, while the model remains competitive in zero-shot retrieval and classification tasks on the AudioCap/Clotho datasets. We also note the lack of proper evaluation techniques for contrastive ALMs and propose a strategy for evaluating ALMs in zero-shot settings. The general-purpose zero-shot model evaluation strategy ZSTE, is used to evaluate various prior models. ZSTE demonstrates a general strategy to evaluate all ZS contrastive models. The model trained with TeminAL successfully outperforms current models on most downstream tasks.
Read more8/20/2024
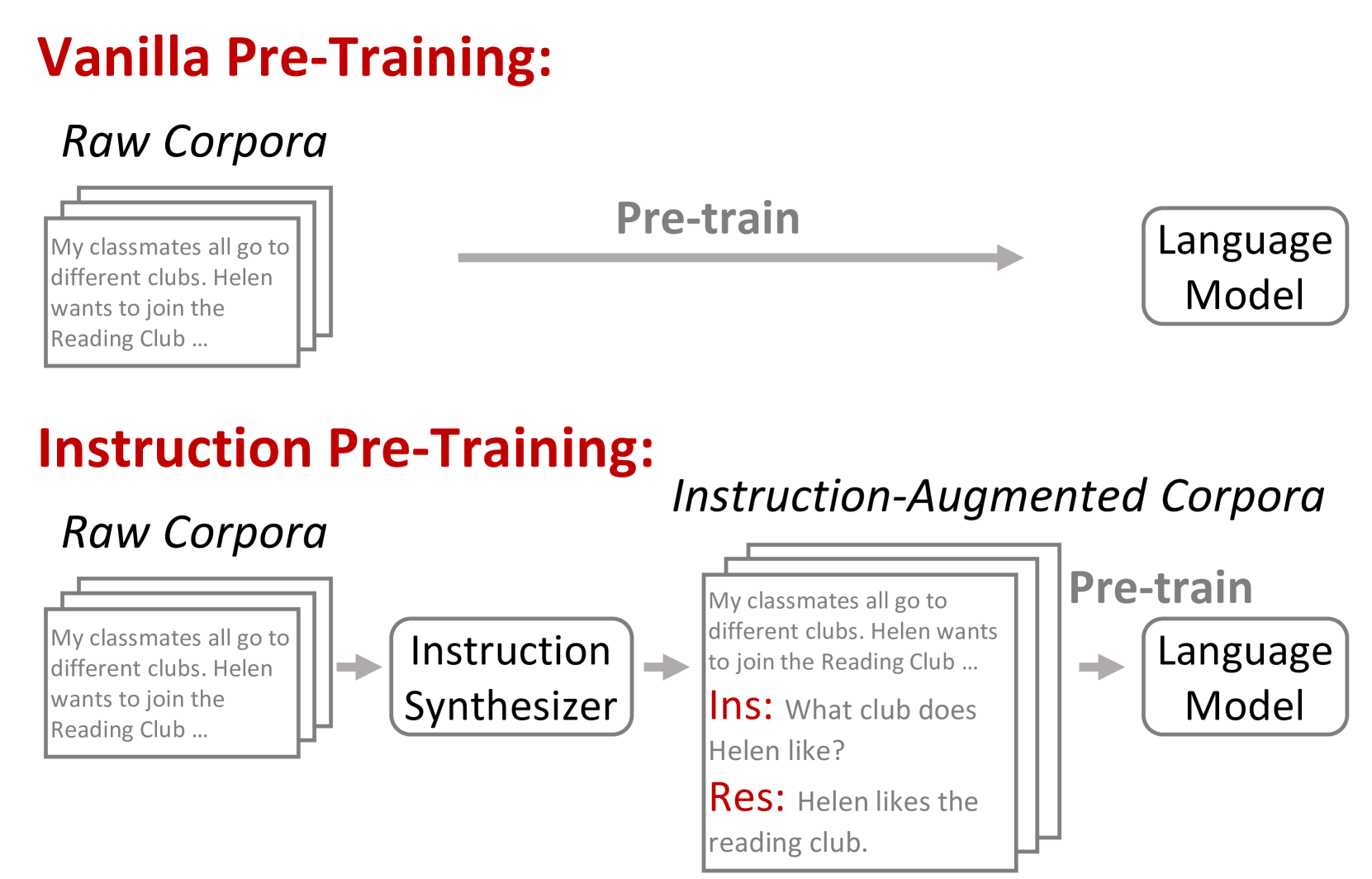
0
Instruction Pre-Training: Language Models are Supervised Multitask Learners
Daixuan Cheng, Yuxian Gu, Shaohan Huang, Junyu Bi, Minlie Huang, Furu Wei
Unsupervised multitask pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, as scaling it in the post-training stage trends towards better generalization. In this paper, we explore supervised multitask pre-training by proposing Instruction Pre-Training, a framework that scalably augments massive raw corpora with instruction-response pairs to pre-train LMs. The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models. In our experiments, we synthesize 200M instruction-response pairs covering 40+ task categories to verify the effectiveness of Instruction Pre-Training. In pre-training from scratch, Instruction Pre-Training not only consistently enhances pre-trained base models but also benefits more from further instruction tuning. In continual pre-training, Instruction Pre-Training enables Llama3-8B to be comparable to or even outperform Llama3-70B. Our model, code, and data are available at https://github.com/microsoft/LMOps.
Read more6/21/2024