Instruction Pre-Training: Language Models are Supervised Multitask Learners
2406.14491
0
0
Abstract
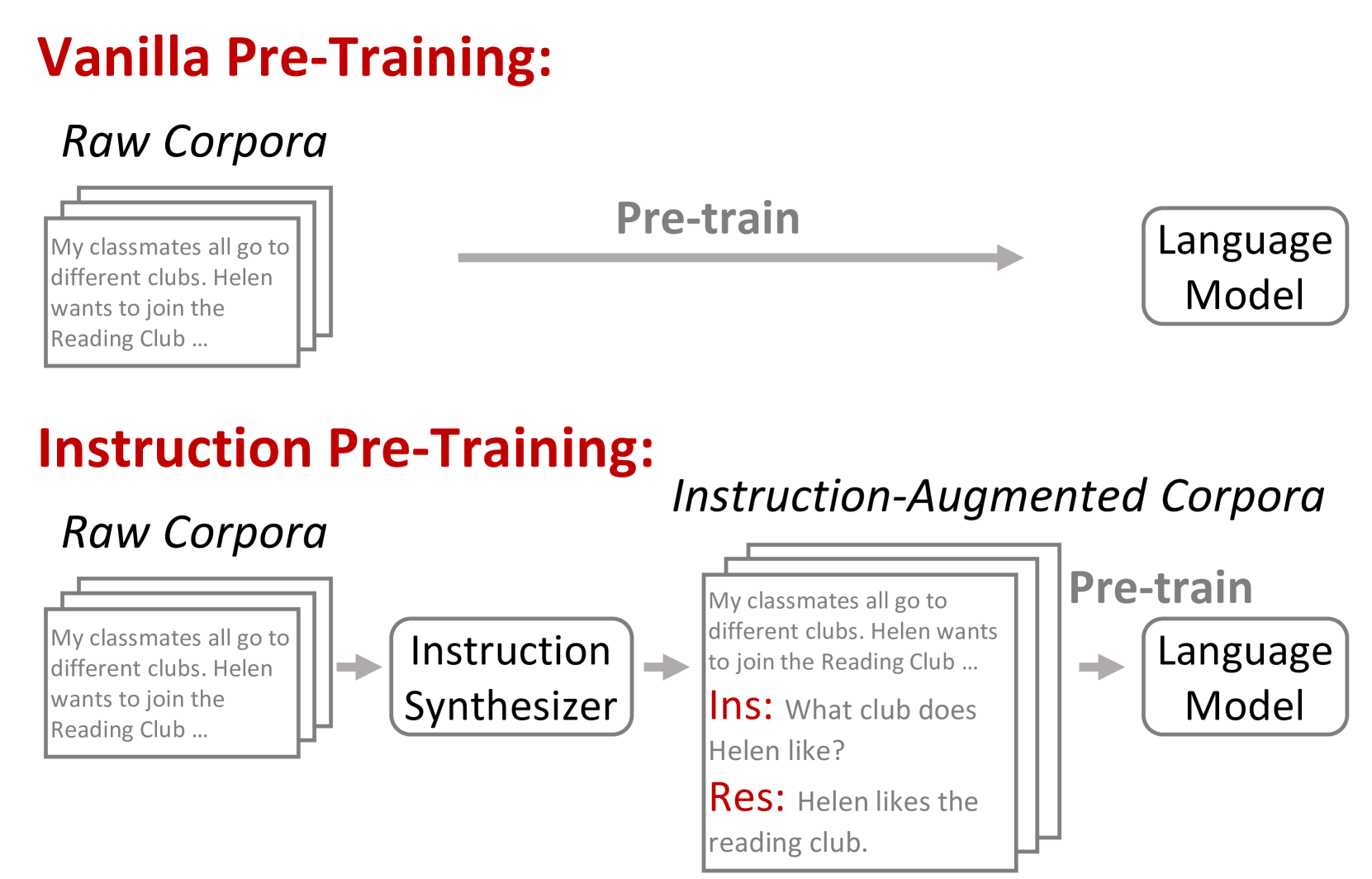
Unsupervised multitask pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, as scaling it in the post-training stage trends towards better generalization. In this paper, we explore supervised multitask pre-training by proposing Instruction Pre-Training, a framework that scalably augments massive raw corpora with instruction-response pairs to pre-train LMs. The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models. In our experiments, we synthesize 200M instruction-response pairs covering 40+ task categories to verify the effectiveness of Instruction Pre-Training. In pre-training from scratch, Instruction Pre-Training not only consistently enhances pre-trained base models but also benefits more from further instruction tuning. In continual pre-training, Instruction Pre-Training enables Llama3-8B to be comparable to or even outperform Llama3-70B. Our model, code, and data are available at https://github.com/microsoft/LMOps.
Create account to get full access
Instruction Pre-Training
Overview
- This paper explores the concept of "instruction pre-training" - the process of training language models to follow natural language instructions and perform a variety of tasks.
- The researchers find that language models pre-trained on instruction data can outperform models trained on traditional language modeling objectives, demonstrating strong task-agnostic capabilities.
- The paper provides insights into the potential benefits of instruction pre-training and its implications for the development of more capable and versatile language models.
Plain English Explanation
Instruction pre-training is a way to train language models, which are artificial intelligence systems that can understand and generate human language. Instead of training the models on traditional language modeling tasks, the researchers trained them on following natural language instructions and performing a wide range of tasks.
The key idea is that by exposing the language models to a diverse set of instructions and tasks during the pre-training phase, they can develop more flexible and capable skills. This allows them to better understand and follow instructions, and to apply their knowledge to a variety of new tasks, even ones they weren't explicitly trained on.
The researchers found that language models trained in this way can outperform models trained on more traditional language modeling objectives. This suggests that instruction pre-training is a powerful approach for developing language models that are more versatile and better able to assist humans with a broad range of tasks.
Technical Explanation
The paper introduces the concept of "instruction pre-training", where language models are trained on a large corpus of natural language instructions and the corresponding task completions. This is in contrast to traditional language model pre-training, which focuses on modeling the statistical patterns of language itself.
The researchers hypothesize that instruction pre-training can lead to language models with stronger task-agnostic capabilities, as they learn to understand and execute a diverse set of instructions during the pre-training phase. They evaluate this hypothesis by pre-training language models on instruction data and assessing their performance on a wide range of downstream tasks.
The paper presents the details of the instruction pre-training process, including the dataset construction and model architecture. The experiments demonstrate that instruction-tuned models outperform their language modeling counterparts on tasks such as question answering, text generation, and few-shot learning. The authors also draw connections to related work on pre-training visual-language models and instruction-following language models.
Critical Analysis
The paper provides a compelling case for the benefits of instruction pre-training, but also acknowledges some limitations and areas for further research. For example, the authors note that the instruction-tuned models may still struggle with tasks that require long-term reasoning or complex multi-step problem-solving, and suggest that combining instruction pre-training with other techniques, such as InstructionCP, may be a promising direction.
Additionally, while the paper demonstrates the effectiveness of instruction pre-training on a diverse range of tasks, it does not explore the model's ability to elicit translation ability or handle more open-ended, creative tasks. Further research in these areas could provide a more comprehensive understanding of the capabilities and limitations of instruction-tuned language models.
Conclusion
This paper presents a novel approach to pre-training language models, known as instruction pre-training. The key insight is that by training models to understand and execute a wide range of natural language instructions, they can develop more flexible and capable task-agnostic skills. The experimental results demonstrate the effectiveness of this approach, with instruction-tuned models outperforming traditional language models on a variety of downstream tasks.
The implications of this research are significant, as it suggests a path towards developing language models that can more effectively assist humans with a broad range of tasks and applications. While the current work has some limitations, the overall findings highlight the potential of instruction pre-training as a powerful technique for advancing the state-of-the-art in natural language processing and artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Instruction-tuned Language Models are Better Knowledge Learners
Zhengbao Jiang, Zhiqing Sun, Weijia Shi, Pedro Rodriguez, Chunting Zhou, Graham Neubig, Xi Victoria Lin, Wen-tau Yih, Srinivasan Iyer
0
0
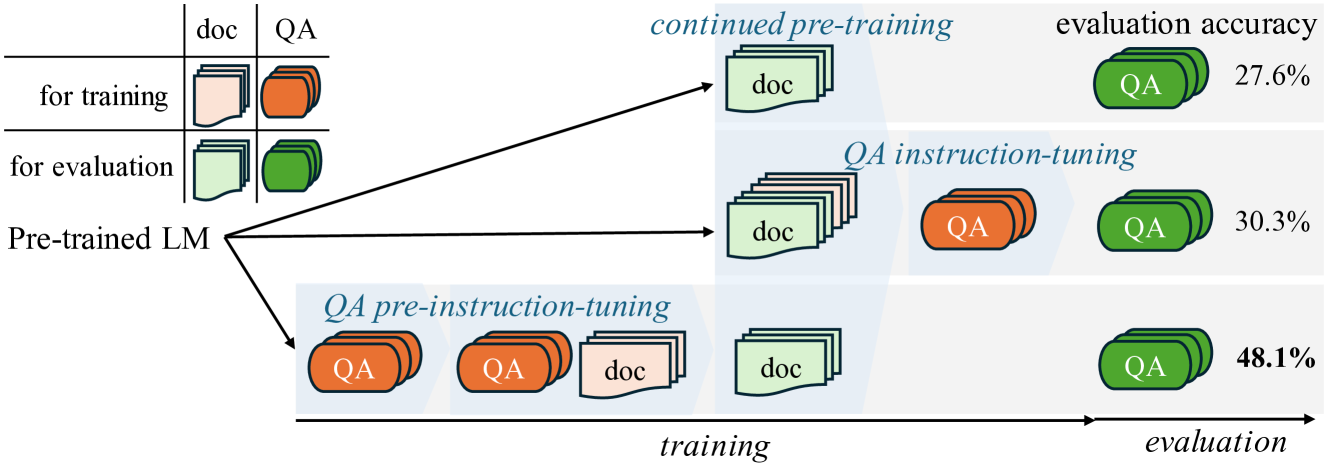
In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that pre-instruction-tuning significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.
5/28/2024

VILA: On Pre-training for Visual Language Models
Ji Lin, Hongxu Yin, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, Song Han
0
0
Visual language models (VLMs) rapidly progressed with the recent success of large language models. There have been growing efforts on visual instruction tuning to extend the LLM with visual inputs, but lacks an in-depth study of the visual language pre-training process, where the model learns to perform joint modeling on both modalities. In this work, we examine the design options for VLM pre-training by augmenting LLM towards VLM through step-by-step controllable comparisons. We introduce three main findings: (1) freezing LLMs during pre-training can achieve decent zero-shot performance, but lack in-context learning capability, which requires unfreezing the LLM; (2) interleaved pre-training data is beneficial whereas image-text pairs alone are not optimal; (3) re-blending text-only instruction data to image-text data during instruction fine-tuning not only remedies the degradation of text-only tasks, but also boosts VLM task accuracy. With an enhanced pre-training recipe we build VILA, a Visual Language model family that consistently outperforms the state-of-the-art models, e.g., LLaVA-1.5, across main benchmarks without bells and whistles. Multi-modal pre-training also helps unveil appealing properties of VILA, including multi-image reasoning, enhanced in-context learning, and better world knowledge.
5/20/2024

Towards Robust Instruction Tuning on Multimodal Large Language Models
Wei Han, Hui Chen, Soujanya Poria
0
0
Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
6/17/2024

InstructionCP: A fast approach to transfer Large Language Models into target language
Kuang-Ming Chen, Hung-yi Lee
0
0
The rapid development of large language models (LLMs) in recent years has largely focused on English, resulting in models that respond exclusively in English. To adapt these models to other languages, continual pre-training (CP) is often employed, followed by supervised fine-tuning (SFT) to maintain conversational abilities. However, CP and SFT can reduce a model's ability to filter harmful content. We propose Instruction Continual Pre-training (InsCP), which integrates instruction tags into the CP process to prevent loss of conversational proficiency while acquiring new languages. Our experiments demonstrate that InsCP retains conversational and Reinforcement Learning from Human Feedback (RLHF) abilities. Empirical evaluations on language alignment, reliability, and knowledge benchmarks confirm the efficacy of InsCP. Notably, this approach requires only 0.1 billion tokens of high-quality instruction-following data, thereby reducing resource consumption.
5/31/2024