MiPa: Mixed Patch Infrared-Visible Modality Agnostic Object Detection

0
🔎
Sign in to get full access
Overview
- This paper presents a novel approach called "anymodal learning" that allows a single model to handle multiple input modalities, such as visible and infrared/thermal images, without any additional inference overhead.
- The key innovation is a technique called "Mixed Patches (MiPa)" that enables the model to effectively leverage both modalities during training, while only requiring a single modality at inference time.
- The proposed method achieves competitive results on individual modality benchmarks and outperforms multimodal fusion approaches, making it a promising technique for applications where computational resources are limited.
Plain English Explanation
Imagine you have a security camera system that needs to work in both well-lit and dark environments. In a well-lit room, a regular visible-light camera would work well, but in a dark room, an infrared or thermal camera would be more useful. [https://aimodels.fyi/papers/arxiv/modality-translation-object-detection-adaptation-without-forgetting] Traditionally, you'd need two separate models - one for visible and one for infrared - which can be costly and complex to manage.
The researchers in this paper have developed a new approach called "anymodal learning" that allows a single model to handle both visible and infrared/thermal inputs. This is done using a technique called "Mixed Patches (MiPa)," which teaches the model to extract useful information from whichever modality is available, without needing to explicitly fuse the two.
[https://aimodels.fyi/papers/arxiv/implicit-multi-spectral-transformer-lightweight-effective-visible] The key advantage of this approach is that it maintains the model's performance on individual modalities, while only requiring a single modality during deployment. This can be very useful in situations where computational resources are limited, such as on edge devices or in low-power applications.
Technical Explanation
The researchers introduce the concept of "anymodal learning," which refers to a single model that can handle multiple input modalities, such as visible and infrared/thermal images. This is in contrast to traditional multimodal approaches that require fusing information from multiple specialized models.
To achieve this, the researchers propose a novel training technique called "Mixed Patches (MiPa)." During training, the model is presented with a mix of visible and infrared/thermal image patches, along with a patch-wise domain agnostic module that learns to find a common representation for both modalities. [https://aimodels.fyi/papers/arxiv/mma-unet-multi-modal-asymmetric-unet-architecture]
This approach allows the model to effectively leverage both modalities during training, without any additional inference overhead during testing. The researchers demonstrate that their anymodal model can achieve competitive results on individual modality benchmarks, and in some cases, even outperform multimodal fusion methods while only requiring a single modality at inference time.
[https://aimodels.fyi/papers/arxiv/equivariant-multi-modality-image-fusion] The proposed method is evaluated on three different visible-infrared object detection datasets, and the results show that the anymodal approach can balance the modalities effectively. Notably, the researchers' "MiPa" technique achieved the state-of-the-art performance on the LLVIP visible/infrared benchmark.
Critical Analysis
The researchers acknowledge that their anymodal approach may not always outperform specialized multimodal models, particularly in scenarios where the modalities provide highly complementary information. However, the ability to maintain competitive performance while only requiring a single modality at inference time can be a significant advantage in applications with limited computational resources.
One potential limitation of the study is the focus on object detection tasks, which may not fully capture the potential benefits of anymodal learning in other computer vision applications, such as semantic segmentation or image classification. [https://aimodels.fyi/papers/arxiv/unsupervised-visible-infrared-reid-via-pseudo-label] Further research could explore the effectiveness of the anymodal approach in a wider range of tasks and datasets.
Additionally, the researchers do not provide a detailed analysis of the model's performance under different levels of modality mismatch or domain shift. Understanding the robustness of the anymodal approach in such scenarios could be an important area for future work.
Conclusion
This paper introduces a novel concept called "anymodal learning" that enables a single model to effectively handle multiple input modalities, such as visible and infrared/thermal images, without any additional inference overhead. The key innovation is the "Mixed Patches (MiPa)" training technique, which allows the model to balance the modalities and achieve competitive results on individual modality benchmarks.
The anymodal approach presents a promising solution for applications where computational resources are limited, as it can leverage multiple modalities during training while only requiring a single modality at inference time. The researchers have demonstrated the effectiveness of their method on object detection tasks, and further exploration of its applicability to other computer vision problems could yield valuable insights for the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
MiPa: Mixed Patch Infrared-Visible Modality Agnostic Object Detection
Heitor R. Medeiros, David Latortue, Eric Granger, Marco Pedersoli
In real-world scenarios, using multiple modalities like visible (RGB) and infrared (IR) can greatly improve the performance of a predictive task such as object detection (OD). Multimodal learning is a common way to leverage these modalities, where multiple modality-specific encoders and a fusion module are used to improve performance. In this paper, we tackle a different way to employ RGB and IR modalities, where only one modality or the other is observed by a single shared vision encoder. This realistic setting requires a lower memory footprint and is more suitable for applications such as autonomous driving and surveillance, which commonly rely on RGB and IR data. However, when learning a single encoder on multiple modalities, one modality can dominate the other, producing uneven recognition results. This work investigates how to efficiently leverage RGB and IR modalities to train a common transformer-based OD vision encoder, while countering the effects of modality imbalance. For this, we introduce a novel training technique to Mix Patches (MiPa) from the two modalities, in conjunction with a patch-wise modality agnostic module, for learning a common representation of both modalities. Our experiments show that MiPa can learn a representation to reach competitive results on traditional RGB/IR benchmarks while only requiring a single modality during inference. Our code is available at: https://github.com/heitorrapela/MiPa.
Read more8/6/2024
🏷️
0
Visible-Infrared Person Re-Identification via Patch-Mixed Cross-Modality Learning
Zhihao Qian, Yutian Lin, Bo Du
Visible-infrared person re-identification (VI-ReID) aims to retrieve images of the same pedestrian from different modalities, where the challenges lie in the significant modality discrepancy. To alleviate the modality gap, recent methods generate intermediate images by GANs, grayscaling, or mixup strategies. However, these methods could introduce extra data distribution, and the semantic correspondence between the two modalities is not well learned. In this paper, we propose a Patch-Mixed Cross-Modality framework (PMCM), where two images of the same person from two modalities are split into patches and stitched into a new one for model learning. A part-alignment loss is introduced to regularize representation learning, and a patch-mixed modality learning loss is proposed to align between the modalities. In this way, the model learns to recognize a person through patches of different styles, thereby the modality semantic correspondence can be inferred. In addition, with the flexible image generation strategy, the patch-mixed images freely adjust the ratio of different modality patches, which could further alleviate the modality imbalance problem. On two VI-ReID datasets, we report new state-of-the-art performance with the proposed method.
Read more5/1/2024
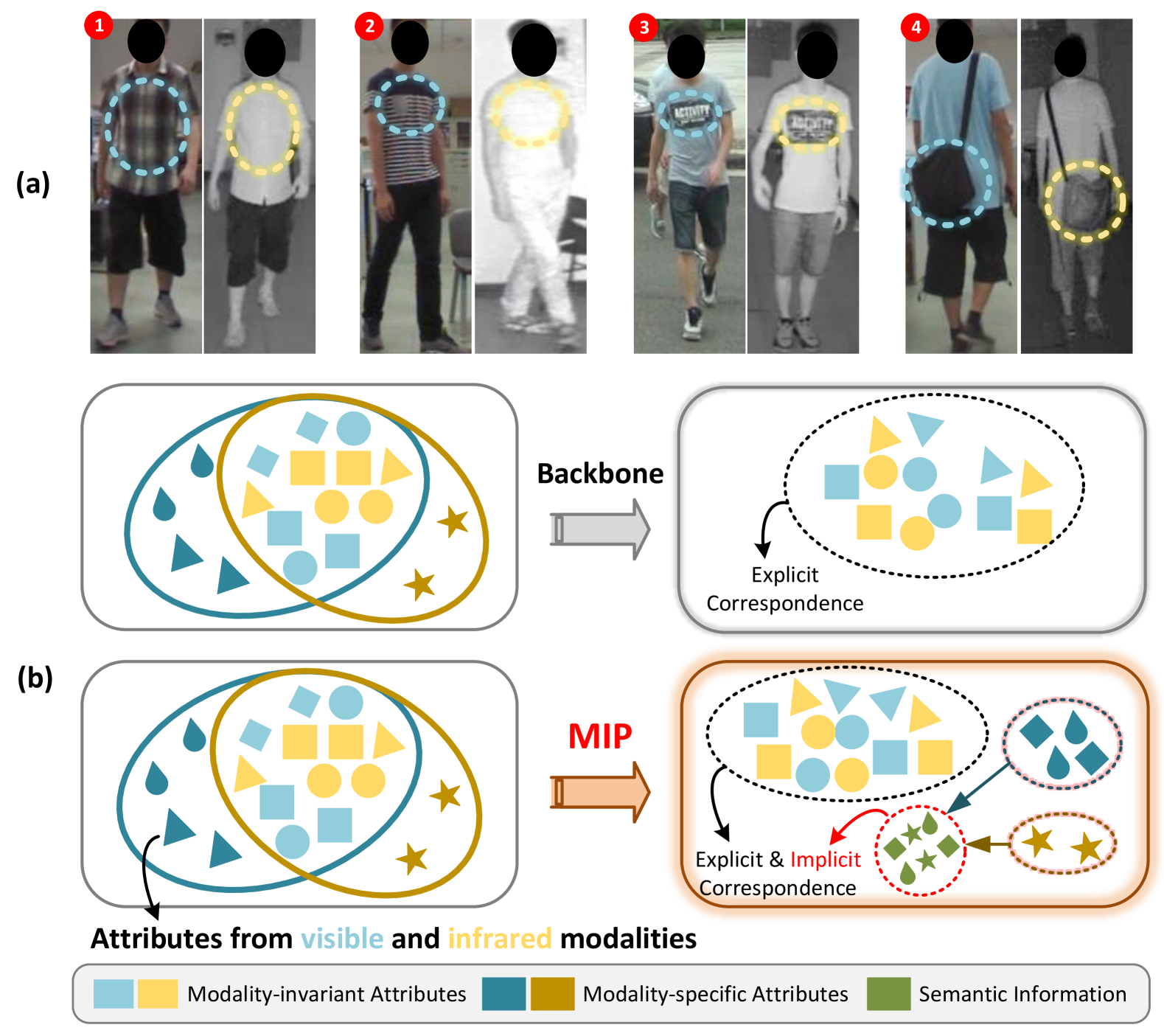
0
Enhancing Visible-Infrared Person Re-identification with Modality- and Instance-aware Visual Prompt Learning
Ruiqi Wu, Bingliang Jiao, Wenxuan Wang, Meng Liu, Peng Wang
The Visible-Infrared Person Re-identification (VI ReID) aims to match visible and infrared images of the same pedestrians across non-overlapped camera views. These two input modalities contain both invariant information, such as shape, and modality-specific details, such as color. An ideal model should utilize valuable information from both modalities during training for enhanced representational capability. However, the gap caused by modality-specific information poses substantial challenges for the VI ReID model to handle distinct modality inputs simultaneously. To address this, we introduce the Modality-aware and Instance-aware Visual Prompts (MIP) network in our work, designed to effectively utilize both invariant and specific information for identification. Specifically, our MIP model is built on the transformer architecture. In this model, we have designed a series of modality-specific prompts, which could enable our model to adapt to and make use of the specific information inherent in different modality inputs, thereby reducing the interference caused by the modality gap and achieving better identification. Besides, we also employ each pedestrian feature to construct a group of instance-specific prompts. These customized prompts are responsible for guiding our model to adapt to each pedestrian instance dynamically, thereby capturing identity-level discriminative clues for identification. Through extensive experiments on SYSU-MM01 and RegDB datasets, the effectiveness of both our designed modules is evaluated. Additionally, our proposed MIP performs better than most state-of-the-art methods.
Read more6/19/2024

0
Multimodal Object Detection via Probabilistic a priori Information Integration
Hafsa El Hafyani, Bastien Pasdeloup, Camille Yver, Pierre Romenteau
Multimodal object detection has shown promise in remote sensing. However, multimodal data frequently encounter the problem of low-quality, wherein the modalities lack strict cell-to-cell alignment, leading to mismatch between different modalities. In this paper, we investigate multimodal object detection where only one modality contains the target object and the others provide crucial contextual information. We propose to resolve the alignment problem by converting the contextual binary information into probability maps. We then propose an early fusion architecture that we validate with extensive experiments on the DOTA dataset.
Read more5/27/2024