Mirror: A Multiple-perspective Self-Reflection Method for Knowledge-rich Reasoning
2402.14963
0
0
Abstract
While Large language models (LLMs) have the capability to iteratively reflect on their own outputs, recent studies have observed their struggles with knowledge-rich problems without access to external resources. In addition to the inefficiency of LLMs in self-assessment, we also observe that LLMs struggle to revisit their predictions despite receiving explicit negative feedback. Therefore, We propose Mirror, a Multiple-perspective self-reflection method for knowledge-rich reasoning, to avoid getting stuck at a particular reflection iteration. Mirror enables LLMs to reflect from multiple-perspective clues, achieved through a heuristic interaction between a Navigator and a Reasoner. It guides agents toward diverse yet plausibly reliable reasoning trajectory without access to ground truth by encouraging (1) diversity of directions generated by Navigator and (2) agreement among strategically induced perturbations in responses generated by the Reasoner. The experiments on five reasoning datasets demonstrate that Mirror's superiority over several contemporary self-reflection approaches. Additionally, the ablation study studies clearly indicate that our strategies alleviate the aforementioned challenges.
Create account to get full access
Overview
- The paper introduces "Mirror," a novel self-reflection method for knowledge-rich reasoning in language models.
- Mirror allows language models to reason about a problem from multiple perspectives, aiming to improve their problem-solving abilities.
- The method involves the model engaging in a dialogue with itself, taking on different roles and viewpoints to analyze a problem more comprehensively.
Plain English Explanation
The paper presents a new technique called "Mirror" that helps AI language models become better at solving complex problems. Language models are AI systems trained on vast amounts of text data to understand and generate human-like language. However, they often struggle when faced with open-ended reasoning tasks that require deep understanding and the ability to consider multiple angles.
The Mirror method addresses this by having the language model engage in a dialogue with itself, taking on different perspectives and roles to analyze a problem more thoroughly. For example, the model might first approach a problem from an analytical point of view, then switch to a more creative mindset, and finally consider the ethical implications. By reflecting on the problem from these diverse angles, the language model can gain a richer and more nuanced understanding, leading to better problem-solving.
This self-reflection process is similar to how humans often talk through a problem out loud, exploring different viewpoints and ideas to arrive at a more comprehensive solution. The Mirror method aims to bring this human-like reflective thinking to language models, empowering them to tackle complex, knowledge-intensive tasks more effectively.
Technical Explanation
The Mirror method leverages the inherent language understanding and generation capabilities of large language models to facilitate a self-reflective reasoning process. During this process, the model takes on different roles or "personas" to analyze a problem from multiple perspectives.
The key steps of the Mirror method are:
- Problem Formulation: The initial problem statement is provided to the language model.
- Perspective-taking: The model generates a set of relevant perspectives or roles (e.g., analyst, creative, ethicist) that could offer valuable insights into the problem.
- Dialogue Generation: The model then engages in a dialogue with itself, switching between the different perspectives to explore the problem from various angles.
- Synthesis and Recommendation: Finally, the model synthesizes the insights gained from the reflective dialogue and provides a comprehensive solution or recommendation.
The authors demonstrate the effectiveness of the Mirror method through experiments on various knowledge-intensive tasks, such as scientific reasoning and ethical decision-making. The results show that the multi-perspective self-reflection process can lead to significant improvements in the language model's problem-solving abilities compared to standard approaches.
Critical Analysis
The Mirror method is a promising approach to enhancing the reasoning capabilities of language models, but it also has some potential limitations and areas for further research:
- Role Identification: The success of the Mirror method relies heavily on the model's ability to identify relevant perspectives or roles to explore. The paper does not provide a detailed mechanism for how this role selection process works, which could be an important area for future investigation.
- Coherence and Consistency: Maintaining a coherent and consistent dialogue between the different personas within the model could be challenging, especially for more complex or open-ended problems. Ensuring the model's self-reflections are logically consistent is an important consideration.
- Scalability and Computational Efficiency: Engaging in a multi-turn dialogue with itself may increase the computational demands on the language model, which could limit its practical applicability, especially for large-scale or time-sensitive problems.
Despite these potential limitations, the Mirror method represents a significant step forward in enhancing the reasoning capabilities of language models. By incorporating self-reflective processes, the model can move beyond simply generating relevant information to truly understanding and reasoning about complex, knowledge-rich problems.
Conclusion
The Mirror method introduced in this paper is a novel approach to improving the problem-solving abilities of language models. By enabling the model to engage in a self-reflective dialogue, considering multiple perspectives and roles, the method can lead to more comprehensive and insightful solutions to knowledge-intensive tasks.
While the Mirror method has some potential limitations that warrant further research, it demonstrates the value of incorporating human-like reflective thinking into AI systems. As language models continue to advance, techniques like Mirror could play a crucial role in developing AI systems that can tackle complex, real-world problems with greater depth and nuance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

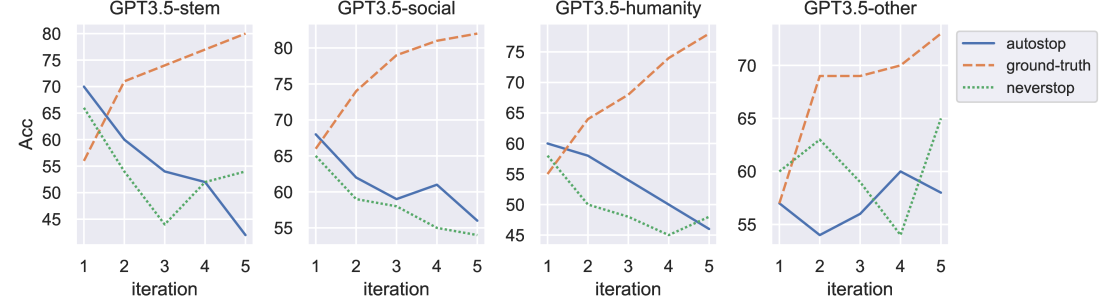
When Hindsight is Not 20/20: Testing Limits on Reflective Thinking in Large Language Models
Yanhong Li, Chenghao Yang, Allyson Ettinger
0
0
Recent studies suggest that self-reflective prompting can significantly enhance the reasoning capabilities of Large Language Models (LLMs). However, the use of external feedback as a stop criterion raises doubts about the true extent of LLMs' ability to emulate human-like self-reflection. In this paper, we set out to clarify these capabilities under a more stringent evaluation setting in which we disallow any kind of external feedback. Our findings under this setting show a split: while self-reflection enhances performance in TruthfulQA, it adversely affects results in HotpotQA. We conduct follow-up analyses to clarify the contributing factors in these patterns, and find that the influence of self-reflection is impacted both by reliability of accuracy in models' initial responses, and by overall question difficulty: specifically, self-reflection shows the most benefit when models are less likely to be correct initially, and when overall question difficulty is higher. We also find that self-reflection reduces tendency toward majority voting. Based on our findings, we propose guidelines for decisions on when to implement self-reflection. We release the codebase for reproducing our experiments at https://github.com/yanhong-lbh/LLM-SelfReflection-Eval.
4/16/2024
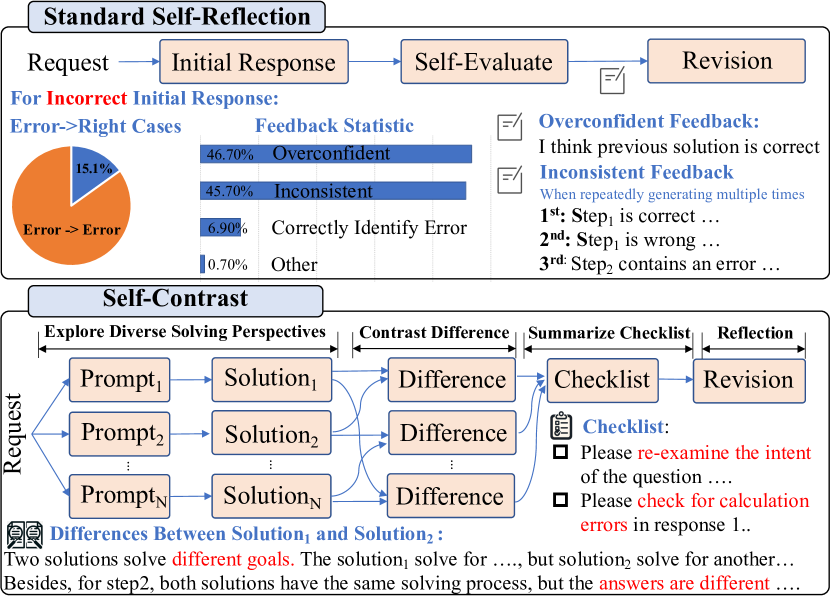
Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives
Wenqi Zhang, Yongliang Shen, Linjuan Wu, Qiuying Peng, Jun Wang, Yueting Zhuang, Weiming Lu
0
0
The reflection capacity of Large Language Model (LLM) has garnered extensive attention. A post-hoc prompting strategy, e.g., reflexion and self-refine, refines LLM's response based on self-evaluated or external feedback. However, recent research indicates without external feedback, LLM's intrinsic reflection is unstable. Our investigation unveils that the key bottleneck is the quality of the self-evaluated feedback. We find LLMs often exhibit overconfidence or high randomness when self-evaluate, offering stubborn or inconsistent feedback, which causes poor reflection. To remedy this, we advocate Self-Contrast: It adaptively explores diverse solving perspectives tailored to the request, contrasts the differences, and summarizes these discrepancies into a checklist which could be used to re-examine and eliminate discrepancies. Our method endows LLM with diverse perspectives to alleviate stubborn biases. Moreover, their discrepancies indicate potential errors or inherent uncertainties that LLM often overlooks. Reflecting upon these can catalyze more accurate and stable reflection. Experiments conducted on a series of reasoning and translation tasks with different LLMs serve to underscore the effectiveness and generality of our strategy.
6/10/2024
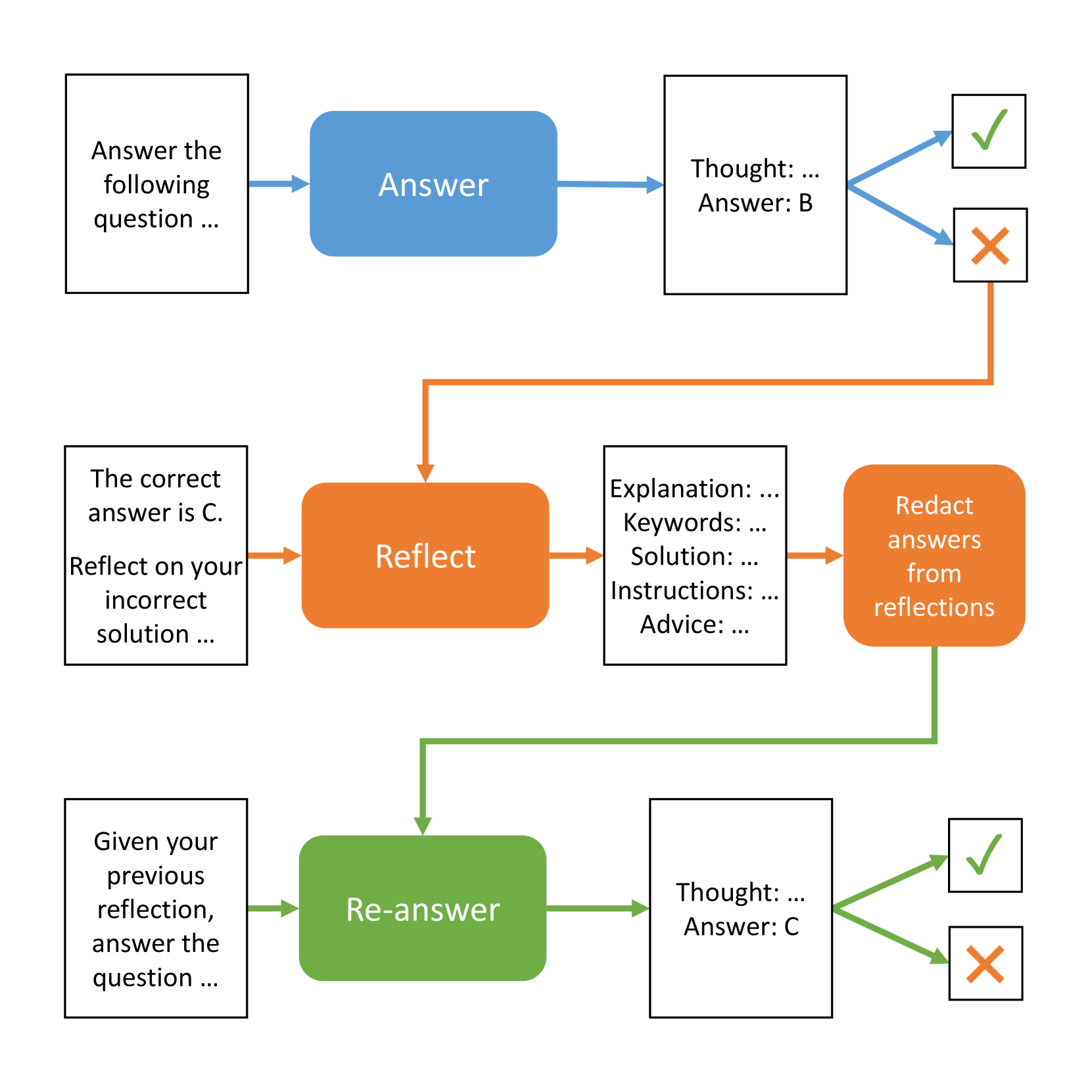
Self-Reflection in LLM Agents: Effects on Problem-Solving Performance
Matthew Renze, Erhan Guven
0
0
In this study, we investigated the effects of self-reflection in large language models (LLMs) on problem-solving performance. We instructed nine popular LLMs to answer a series of multiple-choice questions to provide a performance baseline. For each incorrectly answered question, we instructed eight types of self-reflecting LLM agents to reflect on their mistakes and provide themselves with guidance to improve problem-solving. Then, using this guidance, each self-reflecting agent attempted to re-answer the same questions. Our results indicate that LLM agents are able to significantly improve their problem-solving performance through self-reflection ($p < 0.001$). In addition, we compared the various types of self-reflection to determine their individual contribution to performance. All code and data are available on GitHub at https://github.com/matthewrenze/self-reflection
5/14/2024
💬
METAREFLECTION: Learning Instructions for Language Agents using Past Reflections
Priyanshu Gupta, Shashank Kirtania, Ananya Singha, Sumit Gulwani, Arjun Radhakrishna, Sherry Shi, Gustavo Soares
0
0
Despite the popularity of Large Language Models (LLMs), crafting specific prompts for LLMs to perform particular tasks remains challenging. Users often engage in multiple conversational turns with an LLM-based agent to accomplish their intended task. Recent studies have demonstrated that linguistic feedback, in the form of self-reflections generated by the model, can work as reinforcement during these conversations, thus enabling quicker convergence to the desired outcome. Motivated by these findings, we introduce METAREFLECTION, a novel technique that learns general prompt instructions for a specific domain from individual self-reflections gathered during a training phase. We evaluate our technique in two domains: Infrastructure as Code (IAC) vulnerability detection and question-answering (QA) using REACT and COT. Our results demonstrate a notable improvement, with METARELECTION outperforming GPT-4 by 16.82% (IAC), 31.33% (COT), and 15.42% (REACT), underscoring the potential of METAREFLECTION as a viable method for enhancing the efficiency of LLMs.
5/24/2024