METAREFLECTION: Learning Instructions for Language Agents using Past Reflections
2405.13009
0
0
💬
Abstract
Despite the popularity of Large Language Models (LLMs), crafting specific prompts for LLMs to perform particular tasks remains challenging. Users often engage in multiple conversational turns with an LLM-based agent to accomplish their intended task. Recent studies have demonstrated that linguistic feedback, in the form of self-reflections generated by the model, can work as reinforcement during these conversations, thus enabling quicker convergence to the desired outcome. Motivated by these findings, we introduce METAREFLECTION, a novel technique that learns general prompt instructions for a specific domain from individual self-reflections gathered during a training phase. We evaluate our technique in two domains: Infrastructure as Code (IAC) vulnerability detection and question-answering (QA) using REACT and COT. Our results demonstrate a notable improvement, with METARELECTION outperforming GPT-4 by 16.82% (IAC), 31.33% (COT), and 15.42% (REACT), underscoring the potential of METAREFLECTION as a viable method for enhancing the efficiency of LLMs.
Create account to get full access
Overview
- Large Language Models (LLMs) are increasingly popular, but crafting specific prompts for them to perform particular tasks remains challenging
- Users often engage in multiple conversational turns with an LLM-based agent to accomplish their intended task
- Recent studies have shown that linguistic feedback, in the form of self-reflections generated by the model, can work as reinforcement during these conversations, enabling quicker convergence to the desired outcome
- Motivated by these findings, the researchers introduce METAREFLECTION, a novel technique that learns general prompt instructions for a specific domain from individual self-reflections gathered during a training phase
Plain English Explanation
Despite the growing use of Large Language Models (LLMs), it can still be tricky for people to get these models to perform specific tasks they want. Often, users have to go back and forth with an LLM-based agent a few times before the agent understands what the user is trying to do.
Recent research has found that when the LLM can provide its own thoughts and reflections during these conversations, it can actually help the user and the agent work together more efficiently to reach the desired outcome. This is known as linguistic feedback and self-reflection.
Inspired by these findings, the researchers developed a new technique called METAREFLECTION. METAREFLECTION tries to learn general instructions for how to complete specific tasks, based on the self-reflections that the LLM provides during a training phase. The idea is that these general instructions can then help the LLM be more effective at the task in the future, without needing as much back-and-forth with the user.
The researchers tested METAREFLECTION in two different domains: identifying vulnerabilities in code (Infrastructure as Code, or IAC) and answering questions (Question Answering, or QA). Their results showed that METAREFLECTION outperformed the powerful GPT-4 model by a significant margin in both tasks, suggesting it could be a valuable way to make LLMs more efficient and effective.
Technical Explanation
The researchers introduce a novel technique called METAREFLECTION that aims to learn general prompt instructions for a specific domain from the self-reflections generated by an LLM during a training phase.
In their experiments, the team evaluated METAREFLECTION in two domains: Infrastructure as Code (IAC) vulnerability detection and Question Answering (QA) using the REACT and COT datasets. For IAC, they compared METAREFLECTION's performance to GPT-4, while for QA, they compared it to GPT-4 and RE2LLM, another model that leverages self-reflection.
The results show that METAREFLECTION outperformed GPT-4 by 16.82% on the IAC task, 31.33% on the COT QA task, and 15.42% on the REACT QA task. This demonstrates the potential of METAREFLECTION as a viable method for enhancing the efficiency of LLMs in completing specific tasks.
Critical Analysis
The paper presents an interesting approach to improving the performance of LLMs on specific tasks by leveraging the model's own self-reflections during a training phase. The authors provide a thorough evaluation of METAREFLECTION against strong baselines like GPT-4 and RE2LLM, which lends credibility to their findings.
However, the paper does not delve deeply into the limitations or potential drawbacks of the METAREFLECTION technique. For example, it's unclear how well the approach would generalize to tasks beyond the two domains tested, or how sensitive the performance might be to the quality and quantity of self-reflections gathered during training.
Additionally, the paper does not discuss potential issues around LLMs learning self-restraint or biases that may be introduced during the self-reflection training process. These are important considerations that warrant further exploration.
Overall, the research presented in this paper is a promising step forward in enhancing the capabilities of LLMs, but there is still room for deeper analysis and investigation into the broader implications and limitations of the METAREFLECTION approach.
Conclusion
The researchers have introduced a novel technique called METAREFLECTION that leverages the self-reflections generated by LLMs during a training phase to learn general prompt instructions for specific tasks. Their experiments demonstrate that METAREFLECTION can significantly outperform powerful models like GPT-4 on tasks like Infrastructure as Code vulnerability detection and Question Answering.
These findings suggest that incorporating self-reflection mechanisms into LLM training could be a valuable way to improve the efficiency and effectiveness of these models, particularly when it comes to accomplishing targeted objectives. As LLMs continue to advance and become more widely adopted, techniques like METAREFLECTION may play an important role in unlocking their full potential across a variety of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
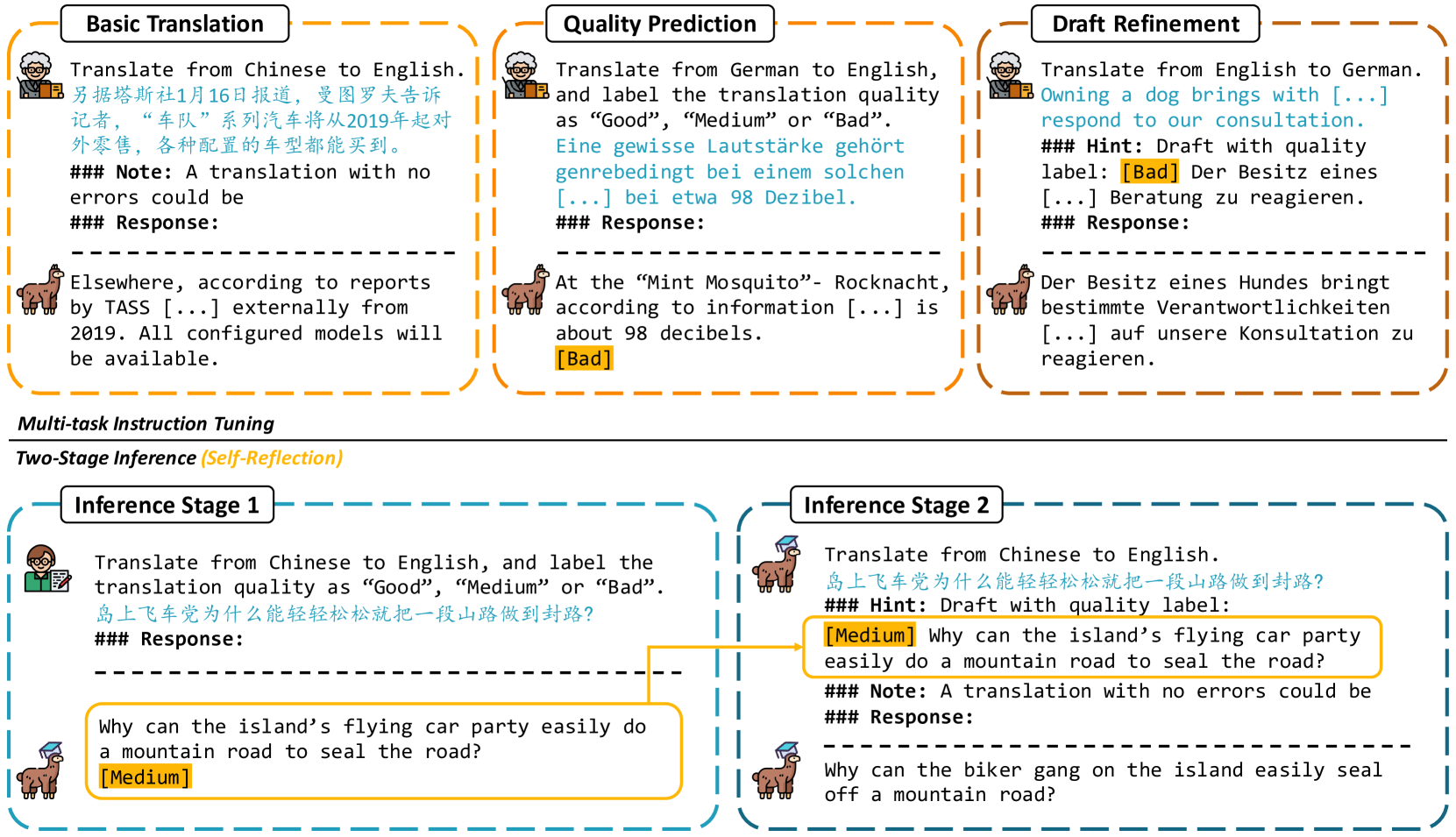
TasTe: Teaching Large Language Models to Translate through Self-Reflection
Yutong Wang, Jiali Zeng, Xuebo Liu, Fandong Meng, Jie Zhou, Min Zhang
0
0
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.
6/13/2024

When Hindsight is Not 20/20: Testing Limits on Reflective Thinking in Large Language Models
Yanhong Li, Chenghao Yang, Allyson Ettinger
0
0
Recent studies suggest that self-reflective prompting can significantly enhance the reasoning capabilities of Large Language Models (LLMs). However, the use of external feedback as a stop criterion raises doubts about the true extent of LLMs' ability to emulate human-like self-reflection. In this paper, we set out to clarify these capabilities under a more stringent evaluation setting in which we disallow any kind of external feedback. Our findings under this setting show a split: while self-reflection enhances performance in TruthfulQA, it adversely affects results in HotpotQA. We conduct follow-up analyses to clarify the contributing factors in these patterns, and find that the influence of self-reflection is impacted both by reliability of accuracy in models' initial responses, and by overall question difficulty: specifically, self-reflection shows the most benefit when models are less likely to be correct initially, and when overall question difficulty is higher. We also find that self-reflection reduces tendency toward majority voting. Based on our findings, we propose guidelines for decisions on when to implement self-reflection. We release the codebase for reproducing our experiments at https://github.com/yanhong-lbh/LLM-SelfReflection-Eval.
4/16/2024

Self-Reflection Outcome is Sensitive to Prompt Construction
Fengyuan Liu, Nouar AlDahoul, Gregory Eady, Yasir Zaki, Bedoor AlShebli, Talal Rahwan
0
0
Large language models (LLMs) demonstrate impressive zero-shot and few-shot reasoning capabilities. Some propose that such capabilities can be improved through self-reflection, i.e., letting LLMs reflect on their own output to identify and correct mistakes in the initial responses. However, despite some evidence showing the benefits of self-reflection, recent studies offer mixed results. Here, we aim to reconcile these conflicting findings by first demonstrating that the outcome of self-reflection is sensitive to prompt wording; e.g., LLMs are more likely to conclude that it has made a mistake when explicitly prompted to find mistakes. Consequently, idiosyncrasies in reflection prompts may lead LLMs to change correct responses unnecessarily. We show that most prompts used in the self-reflection literature are prone to this bias. We then propose different ways of constructing prompts that are conservative in identifying mistakes and show that self-reflection using such prompts results in higher accuracy. Our findings highlight the importance of prompt engineering in self-reflection tasks. We release our code at https://github.com/Michael98Liu/mixture-of-prompts.
6/18/2024

Reflection-Reinforced Self-Training for Language Agents
Zi-Yi Dou, Cheng-Fu Yang, Xueqing Wu, Kai-Wei Chang, Nanyun Peng
0
0
Self-training can potentially improve the performance of language agents without relying on demonstrations from humans or stronger models. The general process involves generating samples from a model, evaluating their quality, and updating the model by training on high-quality samples. However, self-training can face limitations because achieving good performance requires a good amount of high-quality samples, yet relying solely on model sampling for obtaining such samples can be inefficient. In addition, these methods often disregard low-quality samples, failing to leverage them effectively. To address these limitations, we present Reflection-Reinforced Self-Training (Re-ReST), which leverages a reflection model to refine low-quality samples and subsequently uses these improved samples to augment self-training. The reflection model takes both the model output and feedback from an external environment (e.g., unit test results in code generation) as inputs and produces improved samples as outputs. By employing this technique, we effectively enhance the quality of inferior samples, and enrich the self-training dataset with higher-quality samples efficiently. We perform extensive experiments on open-source language agents across tasks, including multi-hop question answering, sequential decision-making, code generation, visual question answering, and text-to-image generation. Results demonstrate improvements over self-training baselines across settings. Moreover, ablation studies confirm the reflection model's efficiency in generating quality self-training samples and its compatibility with self-consistency decoding.
6/4/2024