MirrorCalib: Utilizing Human Pose Information for Mirror-based Virtual Camera Calibration
2311.02791
0
0
➖
Abstract
In this paper, we present the novel task of estimating the extrinsic parameters of a virtual camera relative to a real camera in exercise videos with a mirror. This task poses a significant challenge in scenarios where the views from the real and mirrored cameras have no overlap or share salient features. To address this issue, prior knowledge of a human body and 2D joint locations are utilized to estimate the camera extrinsic parameters when a person is in front of a mirror. We devise a modified eight-point algorithm to obtain an initial estimation from 2D joint locations. The 2D joint locations are then refined subject to human body constraints. Finally, a RANSAC algorithm is employed to remove outliers by comparing their epipolar distances to a predetermined threshold. MirrorCalib achieves a rotation error of 1.82{deg} and a translation error of 69.51 mm on a collected real-world dataset, which outperforms the state-of-art method.
Create account to get full access
Overview
- This paper presents a novel task of estimating the extrinsic parameters of a virtual camera relative to a real camera in exercise videos with a mirror.
- The key challenge is that the views from the real and mirrored cameras have no overlap or share salient features.
- To address this, the paper utilizes prior knowledge of the human body and 2D joint locations to estimate the camera extrinsic parameters when a person is in front of a mirror.
Plain English Explanation
In this paper, the researchers tackle the problem of figuring out the position and orientation of a virtual camera compared to a real camera when filming exercise videos in front of a mirror. This is a tricky task because the views from the real camera and the mirrored camera have no common features that the camera can use to align them.
To solve this, the researchers use what they already know about the human body and the locations of joints (like elbows, knees, etc.) in 2D to estimate the camera's position and orientation. They do this by first using a modified algorithm to get an initial guess, then refining that guess based on the constraints of the human body. Finally, they use a technique called RANSAC to remove any outliers or bad data points.
The end result is a system called MirrorCalib that can figure out the camera parameters with pretty good accuracy, outperforming previous methods. This could be useful for things like exercise video analysis or virtual/augmented reality applications that involve mirrors.
Technical Explanation
The paper presents a novel approach to estimating the extrinsic parameters (position and orientation) of a virtual camera relative to a real camera in exercise videos captured in front of a mirror. This is a challenging task because the views from the real and mirrored cameras have no overlap or shared salient features, making it difficult to align them using traditional computer vision techniques.
To address this, the researchers leverage prior knowledge of the human body and the 2D locations of joints (like elbows, knees, etc.) to estimate the camera extrinsic parameters. They start by using a modified eight-point algorithm to get an initial estimation from the 2D joint locations. Then, they refine this estimation by enforcing constraints based on the known structure of the human body.
Finally, the researchers employ a RANSAC algorithm to remove any outliers by comparing the epipolar distances (a measure of how well the 2D joint locations fit the estimated camera parameters) to a predetermined threshold. This helps to ensure the robustness of the final camera parameter estimates.
The proposed MirrorCalib system achieves strong performance, with a rotation error of 1.82 degrees and a translation error of 69.51 mm on a real-world dataset. This outperforms the state-of-the-art methods, which struggle in these mirror-based scenarios where the camera views have no overlap.
Critical Analysis
The paper presents a novel and practical solution to the problem of camera calibration in the presence of mirrors, which is an important task for applications like exercise video analysis and virtual/augmented reality. The key strength of the approach is its ability to leverage prior knowledge about the human body to compensate for the lack of shared features between the real and mirrored camera views.
However, one potential limitation is that the method relies on the availability of accurate 2D joint locations, which may not always be easy to obtain, especially in challenging real-world conditions. Additionally, the paper does not explore the robustness of the approach to noisy or incomplete joint data.
Further research could also investigate the performance of the MirrorCalib system in more diverse scenarios, such as multiple people in the frame, occlusions, or different types of mirrors. Extending the approach to handle dynamic camera setups or even learn the camera parameters from monocular video could also be fruitful avenues for future work.
Conclusion
This paper presents a novel approach to the problem of estimating the extrinsic parameters of a virtual camera relative to a real camera in exercise videos captured in front of a mirror. By leveraging prior knowledge of the human body and 2D joint locations, the proposed MirrorCalib system can effectively calibrate the camera parameters even in scenarios where the real and mirrored camera views have no overlap.
The strong performance of MirrorCalib on a real-world dataset suggests that this technique could be a valuable tool for a variety of applications, including exercise video analysis, virtual/augmented reality, and beyond. Further research to address the identified limitations and explore more diverse scenarios could help expand the reach and applicability of this innovative approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Mirror-Aware Neural Humans
Daniel Ajisafe, James Tang, Shih-Yang Su, Bastian Wandt, Helge Rhodin
0
0
Human motion capture either requires multi-camera systems or is unreliable when using single-view input due to depth ambiguities. Meanwhile, mirrors are readily available in urban environments and form an affordable alternative by recording two views with only a single camera. However, the mirror setting poses the additional challenge of handling occlusions of real and mirror image. Going beyond existing mirror approaches for 3D human pose estimation, we utilize mirrors for learning a complete body model, including shape and dense appearance. Our main contributions are extending articulated neural radiance fields to include a notion of a mirror, making it sample-efficient over potential occlusion regions. Together, our contributions realize a consumer-level 3D motion capture system that starts from off-the-shelf 2D poses by automatically calibrating the camera, estimating mirror orientation, and subsequently lifting 2D keypoint detections to 3D skeleton pose that is used to condition the mirror-aware NeRF. We empirically demonstrate the benefit of learning a body model and accounting for occlusion in challenging mirror scenes.
5/17/2024

CasCalib: Cascaded Calibration for Motion Capture from Sparse Unsynchronized Cameras
James Tang, Shashwat Suri, Daniel Ajisafe, Bastian Wandt, Helge Rhodin
0
0
It is now possible to estimate 3D human pose from monocular images with off-the-shelf 3D pose estimators. However, many practical applications require fine-grained absolute pose information for which multi-view cues and camera calibration are necessary. Such multi-view recordings are laborious because they require manual calibration, and are expensive when using dedicated hardware. Our goal is full automation, which includes temporal synchronization, as well as intrinsic and extrinsic camera calibration. This is done by using persons in the scene as the calibration objects. Existing methods either address only synchronization or calibration, assume one of the former as input, or have significant limitations. A common limitation is that they only consider single persons, which eases correspondence finding. We attain this generality by partitioning the high-dimensional time and calibration space into a cascade of subspaces and introduce tailored algorithms to optimize each efficiently and robustly. The outcome is an easy-to-use, flexible, and robust motion capture toolbox that we release to enable scientific applications, which we demonstrate on diverse multi-view benchmarks. Project website: https://github.com/jamestang1998/CasCalib.
5/14/2024
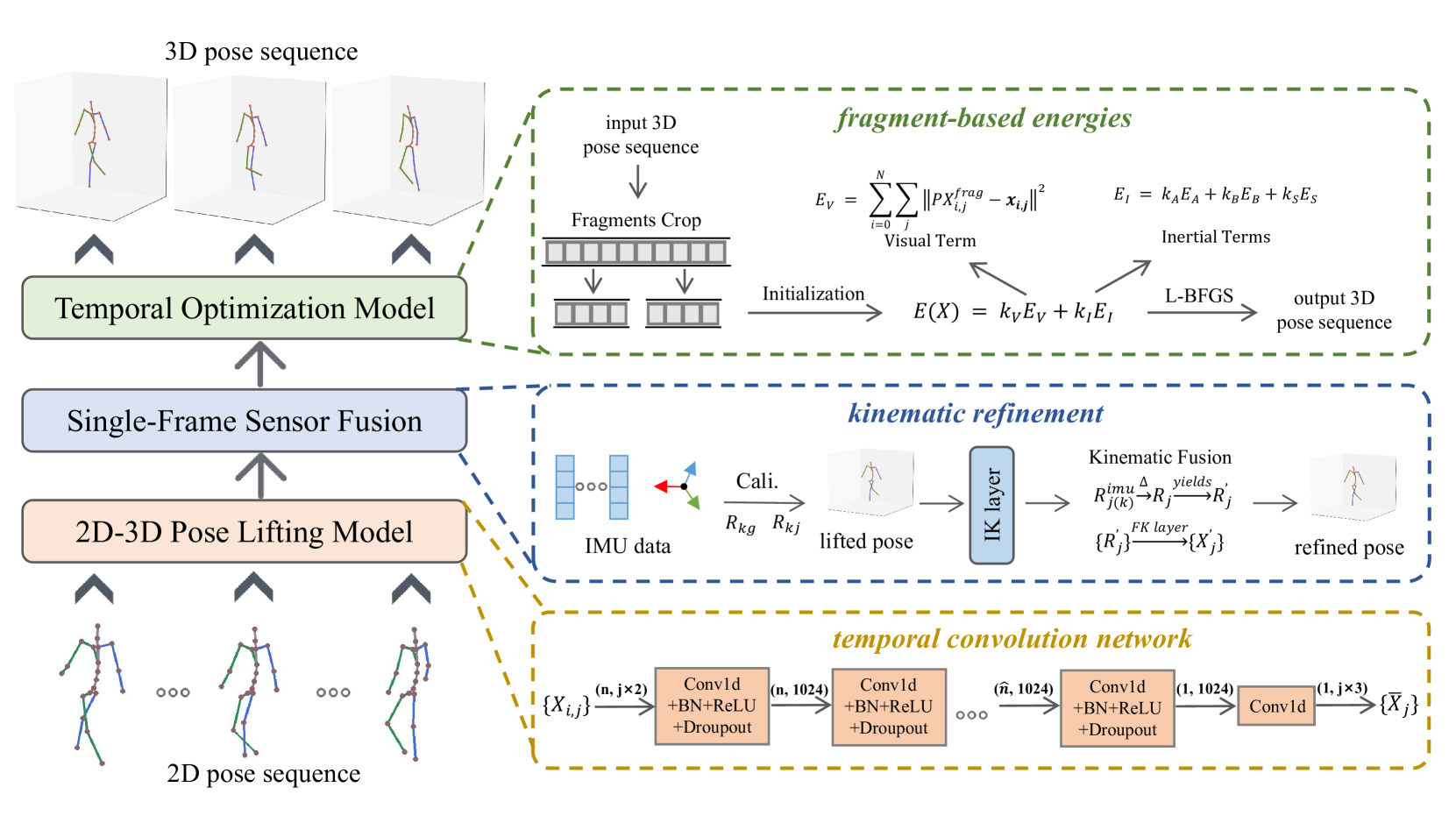
Hybrid 3D Human Pose Estimation with Monocular Video and Sparse IMUs
Yiming Bao, Xu Zhao, Dahong Qian
0
0
Temporal 3D human pose estimation from monocular videos is a challenging task in human-centered computer vision due to the depth ambiguity of 2D-to-3D lifting. To improve accuracy and address occlusion issues, inertial sensor has been introduced to provide complementary source of information. However, it remains challenging to integrate heterogeneous sensor data for producing physically rational 3D human poses. In this paper, we propose a novel framework, Real-time Optimization and Fusion (RTOF), to address this issue. We first incorporate sparse inertial orientations into a parametric human skeleton to refine 3D poses in kinematics. The poses are then optimized by energy functions built on both visual and inertial observations to reduce the temporal jitters. Our framework outputs smooth and biomechanically plausible human motion. Comprehensive experiments with ablation studies demonstrate its rationality and efficiency. On Total Capture dataset, the pose estimation error is significantly decreased compared to the baseline method.
4/30/2024
🏷️
3D Human Pose Perception from Egocentric Stereo Videos
Hiroyasu Akada, Jian Wang, Vladislav Golyanik, Christian Theobalt
0
0
While head-mounted devices are becoming more compact, they provide egocentric views with significant self-occlusions of the device user. Hence, existing methods often fail to accurately estimate complex 3D poses from egocentric views. In this work, we propose a new transformer-based framework to improve egocentric stereo 3D human pose estimation, which leverages the scene information and temporal context of egocentric stereo videos. Specifically, we utilize 1) depth features from our 3D scene reconstruction module with uniformly sampled windows of egocentric stereo frames, and 2) human joint queries enhanced by temporal features of the video inputs. Our method is able to accurately estimate human poses even in challenging scenarios, such as crouching and sitting. Furthermore, we introduce two new benchmark datasets, i.e., UnrealEgo2 and UnrealEgo-RW (RealWorld). The proposed datasets offer a much larger number of egocentric stereo views with a wider variety of human motions than the existing datasets, allowing comprehensive evaluation of existing and upcoming methods. Our extensive experiments show that the proposed approach significantly outperforms previous methods. We will release UnrealEgo2, UnrealEgo-RW, and trained models on our project page.
5/16/2024