CasCalib: Cascaded Calibration for Motion Capture from Sparse Unsynchronized Cameras
2405.06845
0
0

Abstract
It is now possible to estimate 3D human pose from monocular images with off-the-shelf 3D pose estimators. However, many practical applications require fine-grained absolute pose information for which multi-view cues and camera calibration are necessary. Such multi-view recordings are laborious because they require manual calibration, and are expensive when using dedicated hardware. Our goal is full automation, which includes temporal synchronization, as well as intrinsic and extrinsic camera calibration. This is done by using persons in the scene as the calibration objects. Existing methods either address only synchronization or calibration, assume one of the former as input, or have significant limitations. A common limitation is that they only consider single persons, which eases correspondence finding. We attain this generality by partitioning the high-dimensional time and calibration space into a cascade of subspaces and introduce tailored algorithms to optimize each efficiently and robustly. The outcome is an easy-to-use, flexible, and robust motion capture toolbox that we release to enable scientific applications, which we demonstrate on diverse multi-view benchmarks. Project website: https://github.com/jamestang1998/CasCalib.
Create account to get full access
Overview
- The paper presents CasCalib, a novel approach for motion capture from sparse, unsynchronized cameras.
- CasCalib addresses the challenges of camera calibration and temporal synchronization, which are crucial for accurate 3D pose estimation from multi-view video.
- The method uses a cascaded calibration process to jointly optimize camera parameters and temporal offsets, enabling robust 3D reconstruction from unsynchronized cameras.
Plain English Explanation
CasCalib is a technique that helps capture the movement and pose of people in 3D using a set of cameras that are not perfectly synchronized or calibrated. Typically, for accurate 3D pose estimation, the cameras need to be carefully calibrated and their timestamps need to be perfectly aligned. However, this can be a tedious and complex process, especially when working with a large number of cameras.
CasCalib addresses this challenge by using a "cascaded" approach. Instead of calibrating and synchronizing the cameras all at once, it breaks the process into smaller, more manageable steps. First, it roughly calibrates the cameras and estimates their temporal offsets. Then, it refines these estimates through an iterative process, gradually improving the accuracy of the 3D pose reconstruction.
This approach is particularly useful when working with sparse, unsynchronized cameras, such as those that might be set up in a large space or complex environment. By avoiding the need for precise manual calibration and synchronization, CasCalib makes it easier and more practical to set up motion capture systems in a wide range of real-world scenarios.
Technical Explanation
The CasCalib method consists of three main stages:
-
Initial Calibration: In this stage, CasCalib uses a set of 3D reference points (such as a calibration object) to roughly estimate the camera parameters and temporal offsets. This provides an initial starting point for the optimization process.
-
Cascaded Optimization: CasCalib then employs an iterative optimization algorithm to jointly refine the camera parameters and temporal offsets. By alternating between optimizing the camera parameters and the temporal offsets, the method is able to converge to a more accurate solution.
-
3D Pose Estimation: Once the cameras are calibrated and synchronized, CasCalib can use the multi-view video data to reconstruct the 3D poses of people in the scene. This is accomplished by triangulating the 2D keypoints detected in each camera view, taking into account the estimated camera parameters and temporal offsets.
The key innovation of CasCalib is its ability to handle sparse, unsynchronized camera setups. Unlike traditional motion capture systems that rely on dense, synchronized camera arrays, CasCalib can work with a smaller number of cameras that may not be perfectly aligned in time. This makes it a more practical and flexible solution for real-world applications, such as hybrid 3D human pose estimation or multi-person 3D pose estimation from unlabeled data.
Critical Analysis
The paper provides a thorough evaluation of the CasCalib method, demonstrating its effectiveness on both synthetic and real-world datasets. The authors show that CasCalib outperforms traditional calibration techniques, particularly in scenarios with sparse and unsynchronized camera setups.
However, the paper does not address some potential limitations of the approach. For example, the method assumes that the cameras are stationary and that the temporal offsets remain constant over time. In dynamic environments or with moving cameras, the performance of CasCalib may degrade. Additionally, the paper does not explore the scalability of the method to large-scale camera arrays or its robustness to noise and occlusions.
Further research could investigate ways to extend CasCalib to handle more complex camera setups, such as ultra-inertial motion capture systems that integrate additional sensor data. Additionally, exploring the integration of unified diffusion frameworks for scene-aware human motion could potentially enhance the overall accuracy and robustness of the motion capture pipeline.
Conclusion
The CasCalib method presented in this paper provides a novel approach to motion capture from sparse, unsynchronized cameras. By addressing the challenges of camera calibration and temporal synchronization, CasCalib enables robust 3D pose estimation in a wide range of real-world scenarios. The cascaded optimization process and the ability to handle sparse camera setups make CasCalib a promising solution for practical motion capture applications, with potential for further improvements and extensions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
MirrorCalib: Utilizing Human Pose Information for Mirror-based Virtual Camera Calibration
Longyun Liao, Rong Zheng, Andrew Mitchell
0
0
In this paper, we present the novel task of estimating the extrinsic parameters of a virtual camera relative to a real camera in exercise videos with a mirror. This task poses a significant challenge in scenarios where the views from the real and mirrored cameras have no overlap or share salient features. To address this issue, prior knowledge of a human body and 2D joint locations are utilized to estimate the camera extrinsic parameters when a person is in front of a mirror. We devise a modified eight-point algorithm to obtain an initial estimation from 2D joint locations. The 2D joint locations are then refined subject to human body constraints. Finally, a RANSAC algorithm is employed to remove outliers by comparing their epipolar distances to a predetermined threshold. MirrorCalib achieves a rotation error of 1.82{deg} and a translation error of 69.51 mm on a collected real-world dataset, which outperforms the state-of-art method.
5/21/2024
SelfPose3d: Self-Supervised Multi-Person Multi-View 3d Pose Estimation
Vinkle Srivastav, Keqi Chen, Nicolas Padoy
0
0
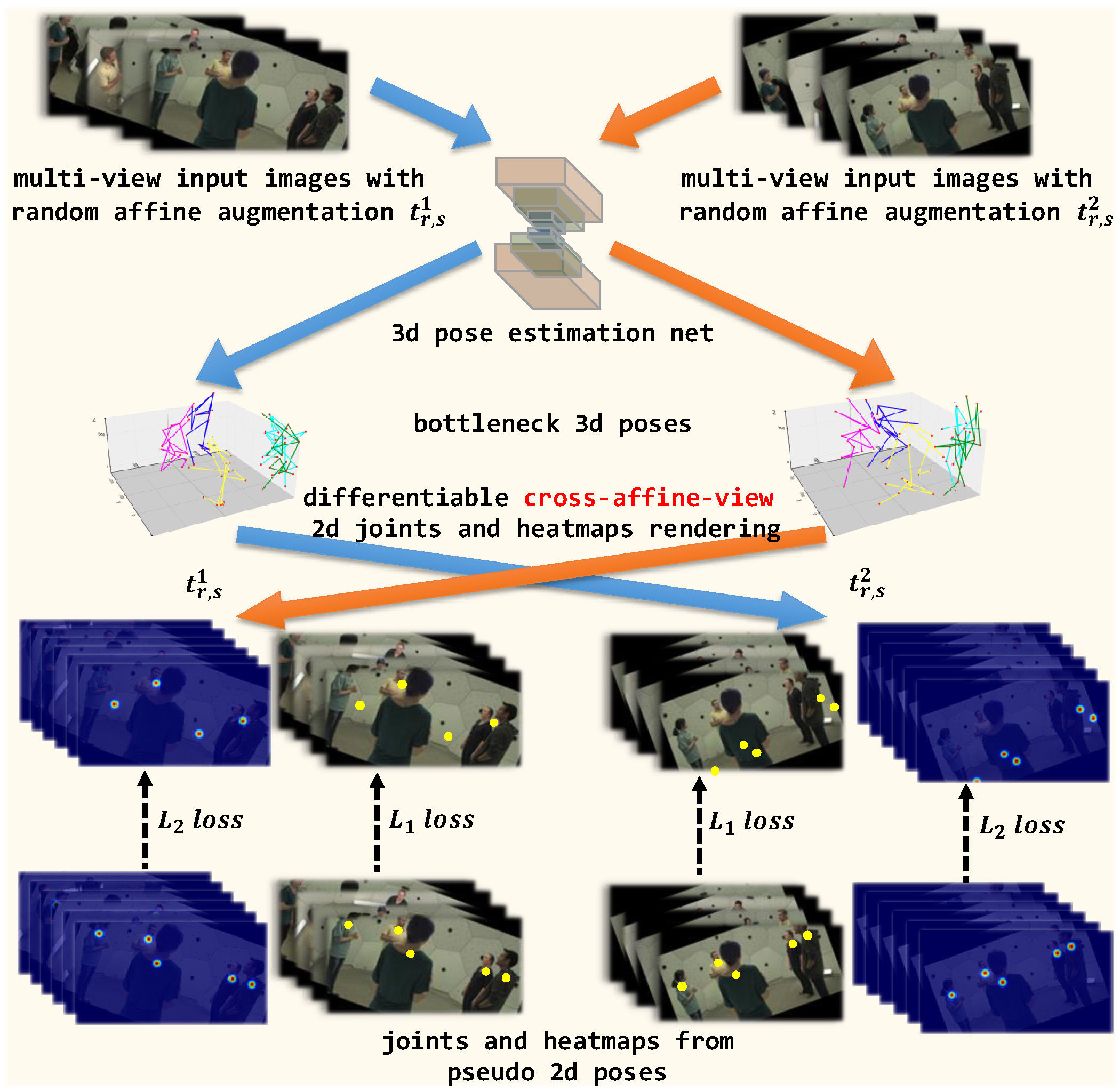
We present a new self-supervised approach, SelfPose3d, for estimating 3d poses of multiple persons from multiple camera views. Unlike current state-of-the-art fully-supervised methods, our approach does not require any 2d or 3d ground-truth poses and uses only the multi-view input images from a calibrated camera setup and 2d pseudo poses generated from an off-the-shelf 2d human pose estimator. We propose two self-supervised learning objectives: self-supervised person localization in 3d space and self-supervised 3d pose estimation. We achieve self-supervised 3d person localization by training the model on synthetically generated 3d points, serving as 3d person root positions, and on the projected root-heatmaps in all the views. We then model the 3d poses of all the localized persons with a bottleneck representation, map them onto all views obtaining 2d joints, and render them using 2d Gaussian heatmaps in an end-to-end differentiable manner. Afterwards, we use the corresponding 2d joints and heatmaps from the pseudo 2d poses for learning. To alleviate the intrinsic inaccuracy of the pseudo labels, we propose an adaptive supervision attention mechanism to guide the self-supervision. Our experiments and analysis on three public benchmark datasets, including Panoptic, Shelf, and Campus, show the effectiveness of our approach, which is comparable to fully-supervised methods. Code: https://github.com/CAMMA-public/SelfPose3D. Video demo: https://youtu.be/GAqhmUIr2E8.
6/11/2024
Hybrid 3D Human Pose Estimation with Monocular Video and Sparse IMUs
Yiming Bao, Xu Zhao, Dahong Qian
0
0
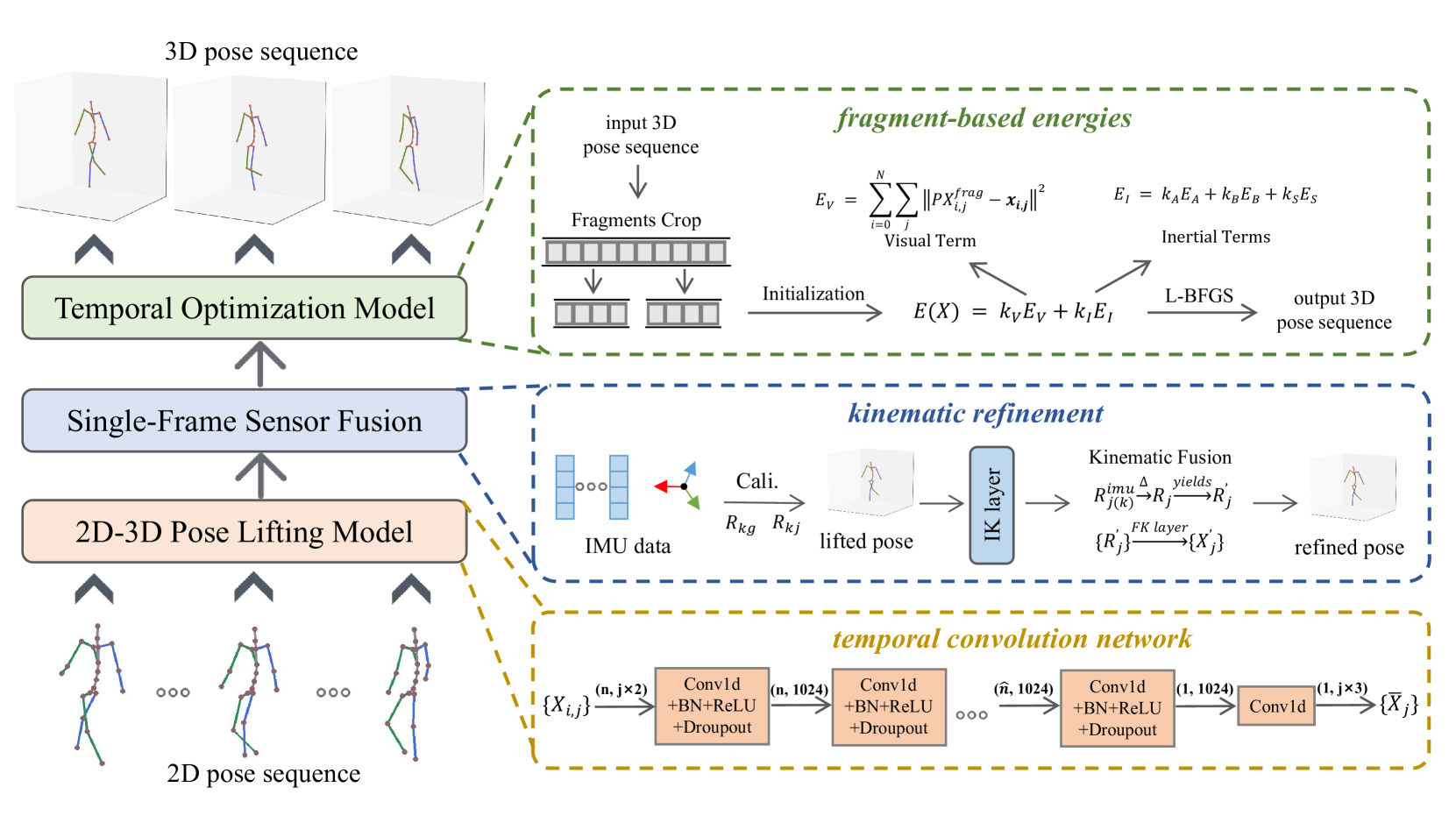
Temporal 3D human pose estimation from monocular videos is a challenging task in human-centered computer vision due to the depth ambiguity of 2D-to-3D lifting. To improve accuracy and address occlusion issues, inertial sensor has been introduced to provide complementary source of information. However, it remains challenging to integrate heterogeneous sensor data for producing physically rational 3D human poses. In this paper, we propose a novel framework, Real-time Optimization and Fusion (RTOF), to address this issue. We first incorporate sparse inertial orientations into a parametric human skeleton to refine 3D poses in kinematics. The poses are then optimized by energy functions built on both visual and inertial observations to reduce the temporal jitters. Our framework outputs smooth and biomechanically plausible human motion. Comprehensive experiments with ablation studies demonstrate its rationality and efficiency. On Total Capture dataset, the pose estimation error is significantly decreased compared to the baseline method.
4/30/2024
📊
Multi-person 3D pose estimation from unlabelled data
Daniel Rodriguez-Criado, Pilar Bachiller, George Vogiatzis, Luis J. Manso
0
0
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
4/10/2024