Hybrid 3D Human Pose Estimation with Monocular Video and Sparse IMUs
2404.17837
0
0
Abstract
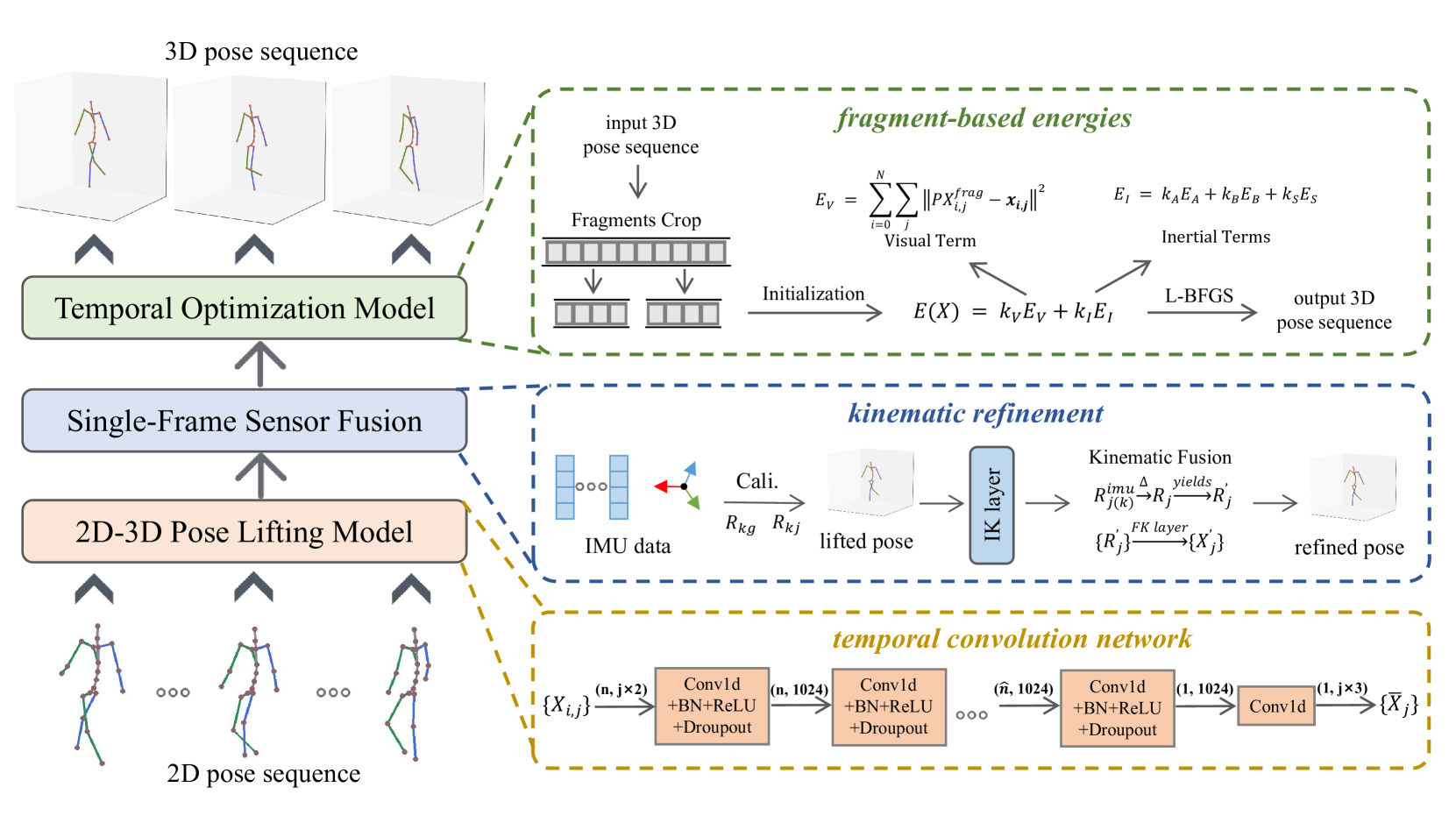
Temporal 3D human pose estimation from monocular videos is a challenging task in human-centered computer vision due to the depth ambiguity of 2D-to-3D lifting. To improve accuracy and address occlusion issues, inertial sensor has been introduced to provide complementary source of information. However, it remains challenging to integrate heterogeneous sensor data for producing physically rational 3D human poses. In this paper, we propose a novel framework, Real-time Optimization and Fusion (RTOF), to address this issue. We first incorporate sparse inertial orientations into a parametric human skeleton to refine 3D poses in kinematics. The poses are then optimized by energy functions built on both visual and inertial observations to reduce the temporal jitters. Our framework outputs smooth and biomechanically plausible human motion. Comprehensive experiments with ablation studies demonstrate its rationality and efficiency. On Total Capture dataset, the pose estimation error is significantly decreased compared to the baseline method.
Create account to get full access
Overview
- This paper presents a hybrid approach for estimating the 3D human pose from a monocular video and sparse inertial measurement units (IMUs).
- The proposed method combines the strengths of vision-based and sensor-based techniques to achieve accurate and robust 3D human pose estimation.
- The system leverages the temporal information from the video and the direct 3D measurements from the IMUs to estimate the 3D human pose more accurately than using either modality alone.
Plain English Explanation
The paper describes a new way to estimate the 3D position and orientation of a person's body parts from a single video camera and a few small motion sensors worn on the body. Estimating 3D human pose is an important task for applications like computer animation, virtual reality, and human-computer interaction.
Traditional vision-based methods use the video alone to infer the 3D pose, but this can be challenging due to depth ambiguities and occlusions. Sensor-based methods that use wearable motion sensors can directly measure the 3D orientation of body parts, but they require a full set of sensors which can be impractical.
The key idea in this paper is to combine the strengths of both approaches. By using a few strategically placed motion sensors along with the video, the method can leverage the temporal continuity from the video and the direct 3D measurements from the sensors. This hybrid approach improves the accuracy and robustness of the 3D pose estimation compared to using either modality alone.
The paper presents the technical details of the proposed system and demonstrates its effectiveness through experiments on benchmark datasets. The results show that the hybrid approach outperforms state-of-the-art vision-based and sensor-based methods, making it a promising solution for real-world 3D human pose estimation tasks.
Technical Explanation
The paper proposes a hybrid 3D human pose estimation system that combines monocular video and sparse inertial measurement units (IMUs). The key components of the system are:
-
Video-based Pose Estimation: The method uses a vision-based 3D pose estimator to extract 2D joint locations from the input video frames. This provides the temporal information about the person's movement.
-
IMU-based Pose Estimation: The sparse set of IMUs worn by the person directly measure the 3D orientation of the corresponding body parts. This provides the direct 3D measurements to complement the vision-based estimates.
-
Hybrid Optimization: The system jointly optimizes the video-based and IMU-based pose estimates to obtain the final 3D human pose. This leverages the strengths of both modalities to achieve more accurate and robust results.
The paper also presents a novel uncertainty-aware 3D human pose estimation framework that models the inherent uncertainties in the 3D pose estimates. This allows the system to reason about the reliability of the estimates and further improve the overall performance.
The proposed method is extensively evaluated on benchmark datasets for 3D human pose estimation and camera-IMU calibration. The results demonstrate that the hybrid approach outperforms state-of-the-art vision-based and sensor-based methods, establishing a new state-of-the-art for 3D human pose estimation from monocular video and sparse IMUs.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed hybrid 3D human pose estimation system. The authors acknowledge the limitations of their approach, such as the requirement for a calibrated camera-IMU setup and the need for a sparse set of IMUs to be worn by the subject.
One potential concern is the reliance on the performance of the underlying vision-based and sensor-based pose estimation models. If these individual components have significant errors, the hybrid optimization may not be able to fully compensate for them. Further research could explore ways to make the hybrid system more robust to such errors in the input modalities.
Additionally, the paper does not discuss the computational complexity of the proposed method or its real-time performance. This information would be valuable for understanding the practical applicability of the system, especially for applications that require low-latency pose estimation.
Overall, the paper presents a compelling approach that leverages the complementary strengths of vision and inertial sensing for accurate and robust 3D human pose estimation. The results demonstrate the effectiveness of the hybrid technique and suggest promising directions for further research in this area.
Conclusion
This paper introduces a hybrid 3D human pose estimation system that combines monocular video and sparse inertial measurement units (IMUs). The key innovation is the joint optimization of video-based and IMU-based pose estimates to exploit the temporal information from the video and the direct 3D measurements from the sensors.
The results show that this hybrid approach outperforms state-of-the-art vision-based and sensor-based methods, establishing a new benchmark for 3D human pose estimation from monocular video and sparse IMUs. The system's ability to reason about the inherent uncertainties in the pose estimates further enhances its robustness and reliability.
The proposed method has the potential to enable more accurate and practical 3D human pose estimation for a wide range of applications, such as computer animation, virtual reality, and human-computer interaction. Future research could explore ways to further improve the system's robustness and computational efficiency, as well as its extensibility to larger, more complex datasets and real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
3D Human Pose Perception from Egocentric Stereo Videos
Hiroyasu Akada, Jian Wang, Vladislav Golyanik, Christian Theobalt
0
0
While head-mounted devices are becoming more compact, they provide egocentric views with significant self-occlusions of the device user. Hence, existing methods often fail to accurately estimate complex 3D poses from egocentric views. In this work, we propose a new transformer-based framework to improve egocentric stereo 3D human pose estimation, which leverages the scene information and temporal context of egocentric stereo videos. Specifically, we utilize 1) depth features from our 3D scene reconstruction module with uniformly sampled windows of egocentric stereo frames, and 2) human joint queries enhanced by temporal features of the video inputs. Our method is able to accurately estimate human poses even in challenging scenarios, such as crouching and sitting. Furthermore, we introduce two new benchmark datasets, i.e., UnrealEgo2 and UnrealEgo-RW (RealWorld). The proposed datasets offer a much larger number of egocentric stereo views with a wider variety of human motions than the existing datasets, allowing comprehensive evaluation of existing and upcoming methods. Our extensive experiments show that the proposed approach significantly outperforms previous methods. We will release UnrealEgo2, UnrealEgo-RW, and trained models on our project page.
5/16/2024
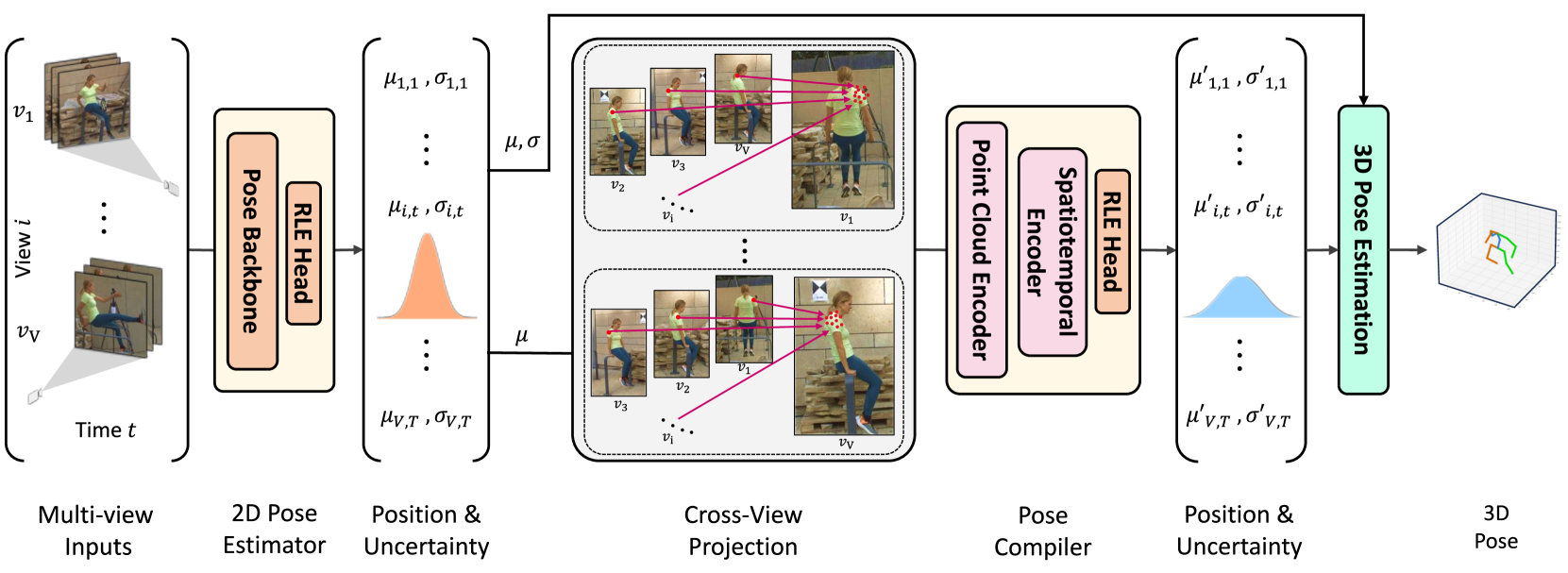
UPose3D: Uncertainty-Aware 3D Human Pose Estimation with Cross-View and Temporal Cues
Vandad Davoodnia, Saeed Ghorbani, Marc-Andr'e Carbonneau, Alexandre Messier, Ali Etemad
0
0
We introduce UPose3D, a novel approach for multi-view 3D human pose estimation, addressing challenges in accuracy and scalability. Our method advances existing pose estimation frameworks by improving robustness and flexibility without requiring direct 3D annotations. At the core of our method, a pose compiler module refines predictions from a 2D keypoints estimator that operates on a single image by leveraging temporal and cross-view information. Our novel cross-view fusion strategy is scalable to any number of cameras, while our synthetic data generation strategy ensures generalization across diverse actors, scenes, and viewpoints. Finally, UPose3D leverages the prediction uncertainty of both the 2D keypoint estimator and the pose compiler module. This provides robustness to outliers and noisy data, resulting in state-of-the-art performance in out-of-distribution settings. In addition, for in-distribution settings, UPose3D yields a performance rivaling methods that rely on 3D annotated data, while being the state-of-the-art among methods relying only on 2D supervision.
5/16/2024
🔍
Improving the Robustness of 3D Human Pose Estimation: A Benchmark and Learning from Noisy Input
Trung-Hieu Hoang, Mona Zehni, Huy Phan, Duc Minh Vo, Minh N. Do
0
0
Despite the promising performance of current 3D human pose estimation techniques, understanding and enhancing their generalization on challenging in-the-wild videos remain an open problem. In this work, we focus on the robustness of 2D-to-3D pose lifters. To this end, we develop two benchmark datasets, namely Human3.6M-C and HumanEva-I-C, to examine the robustness of video-based 3D pose lifters to a wide range of common video corruptions including temporary occlusion, motion blur, and pixel-level noise. We observe the poor generalization of state-of-the-art 3D pose lifters in the presence of corruption and establish two techniques to tackle this issue. First, we introduce Temporal Additive Gaussian Noise (TAGN) as a simple yet effective 2D input pose data augmentation. Additionally, to incorporate the confidence scores output by the 2D pose detectors, we design a confidence-aware convolution (CA-Conv) block. Extensively tested on corrupted videos, the proposed strategies consistently boost the robustness of 3D pose lifters and serve as new baselines for future research.
4/17/2024
👀
Reconstructing Human Pose from Inertial Measurements: A Generative Model-based Compressive Sensing Approach
Nguyen Quang Hieu, Dinh Thai Hoang, Diep N. Nguyen, Mohammad Abu Alsheikh
0
0
The ability to sense, localize, and estimate the 3D position and orientation of the human body is critical in virtual reality (VR) and extended reality (XR) applications. This becomes more important and challenging with the deployment of VR/XR applications over the next generation of wireless systems such as 5G and beyond. In this paper, we propose a novel framework that can reconstruct the 3D human body pose of the user given sparse measurements from Inertial Measurement Unit (IMU) sensors over a noisy wireless environment. Specifically, our framework enables reliable transmission of compressed IMU signals through noisy wireless channels and effective recovery of such signals at the receiver, e.g., an edge server. This task is very challenging due to the constraints of transmit power, recovery accuracy, and recovery latency. To address these challenges, we first develop a deep generative model at the receiver to recover the data from linear measurements of IMU signals. The linear measurements of the IMU signals are obtained by a linear projection with a measurement matrix based on the compressive sensing theory. The key to the success of our framework lies in the novel design of the measurement matrix at the transmitter, which can not only satisfy power constraints for the IMU devices but also obtain a highly accurate recovery for the IMU signals at the receiver. This can be achieved by extending the set-restricted eigenvalue condition of the measurement matrix and combining it with an upper bound for the power transmission constraint. Our framework can achieve robust performance for recovering 3D human poses from noisy compressed IMU signals. Additionally, our pre-trained deep generative model achieves signal reconstruction accuracy comparable to an optimization-based approach, i.e., Lasso, but is an order of magnitude faster.
5/14/2024