Missed Causes and Ambiguous Effects: Counterfactuals Pose Challenges for Interpreting Neural Networks

0

Sign in to get full access
Overview
- Examines the challenges of using counterfactual analysis to interpret neural networks
- Highlights limitations of current approaches in capturing "missed causes" and "ambiguous effects"
- Emphasizes the need for more robust causal models and counterfactual reasoning to better understand neural network decisions
Plain English Explanation
Counterfactual analysis is a powerful tool for understanding how machine learning models, like neural networks, make decisions. By exploring "what-if" scenarios, counterfactuals can reveal the underlying factors that influence a model's output.
However, this paper argues that current counterfactual approaches have significant limitations when it comes to interpreting neural networks. The authors highlight two key challenges:
-
Missed Causes: Neural networks can pick up on subtle patterns in data that may not be obvious to humans. Counterfactuals often fail to capture these "missed causes" that influence the model's behavior.
-
Ambiguous Effects: The complex, non-linear nature of neural networks can lead to counterfactuals having ambiguous or unexpected effects on the model's output. It can be difficult to determine the precise causal relationship between inputs and outputs.
To address these issues, the authors suggest that we need more sophisticated causal models and counterfactual reasoning techniques. By better understanding the underlying causal structure of neural networks, we can develop more reliable and interpretable AI systems.
Technical Explanation
The paper explores the use of counterfactual analysis as a tool for interpreting neural networks. Counterfactuals are "what-if" scenarios that allow us to examine how a model's output would change if certain inputs were modified.
The authors argue that current counterfactual approaches have significant limitations when it comes to neural networks. One key issue is the problem of "missed causes" - neural networks can pick up on subtle patterns in data that may not be obvious to humans. Counterfactuals often fail to capture these underlying factors that influence the model's behavior.
Another challenge is "ambiguous effects" - the complex, non-linear nature of neural networks can lead to counterfactuals having unexpected or difficult-to-interpret effects on the model's output. It can be hard to determine the precise causal relationship between inputs and outputs.
To address these limitations, the authors suggest that we need more sophisticated causal models and counterfactual reasoning techniques. By better understanding the underlying causal structure of neural networks, we can develop more reliable and interpretable AI systems.
Critical Analysis
The paper raises important concerns about the limitations of current counterfactual approaches for interpreting neural networks. The authors highlight valid points about the challenges of capturing "missed causes" and dealing with "ambiguous effects".
However, the paper could have provided more concrete examples or case studies to illustrate these issues. Additionally, while the authors suggest the need for more sophisticated causal models and counterfactual reasoning, they do not offer specific solutions or directions for future research.
It would have been helpful for the paper to explore potential avenues for addressing these challenges, such as incorporating domain knowledge, using causal discovery algorithms, or exploring alternative counterfactual generation techniques. This could have provided a more comprehensive and actionable roadmap for improving the interpretability of neural networks.
Conclusion
This paper highlights significant limitations in the use of counterfactual analysis for interpreting neural networks. The authors identify key issues such as "missed causes" and "ambiguous effects" that undermine the effectiveness of current counterfactual approaches.
To address these challenges, the authors suggest the need for more robust causal models and counterfactual reasoning techniques. By better understanding the underlying causal structure of neural networks, researchers can develop more reliable and interpretable AI systems that can more transparently explain their decision-making processes.
This research underscores the importance of continued efforts to improve the interpretability of neural networks, which is crucial for building trust and accountability in AI applications across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Missed Causes and Ambiguous Effects: Counterfactuals Pose Challenges for Interpreting Neural Networks
Aaron Mueller
Interpretability research takes counterfactual theories of causality for granted. Most causal methods rely on counterfactual interventions to inputs or the activations of particular model components, followed by observations of the change in models' output logits or behaviors. While this yields more faithful evidence than correlational methods, counterfactuals nonetheless have key problems that bias our findings in specific and predictable ways. Specifically, (i) counterfactual theories do not effectively capture multiple independently sufficient causes of the same effect, which leads us to miss certain causes entirely; and (ii) counterfactual dependencies in neural networks are generally not transitive, which complicates methods for extracting and interpreting causal graphs from neural networks. We discuss the implications of these challenges for interpretability researchers and propose concrete suggestions for future work.
Read more7/8/2024

0
Using LLMs for Explaining Sets of Counterfactual Examples to Final Users
Arturo Fredes, Jordi Vitria
Causality is vital for understanding true cause-and-effect relationships between variables within predictive models, rather than relying on mere correlations, making it highly relevant in the field of Explainable AI. In an automated decision-making scenario, causal inference methods can analyze the underlying data-generation process, enabling explanations of a model's decision by manipulating features and creating counterfactual examples. These counterfactuals explore hypothetical scenarios where a minimal number of factors are altered, providing end-users with valuable information on how to change their situation. However, interpreting a set of multiple counterfactuals can be challenging for end-users who are not used to analyzing raw data records. In our work, we propose a novel multi-step pipeline that uses counterfactuals to generate natural language explanations of actions that will lead to a change in outcome in classifiers of tabular data using LLMs. This pipeline is designed to guide the LLM through smaller tasks that mimic human reasoning when explaining a decision based on counterfactual cases. We conducted various experiments using a public dataset and proposed a method of closed-loop evaluation to assess the coherence of the final explanation with the counterfactuals, as well as the quality of the content. Results are promising, although further experiments with other datasets and human evaluations should be carried out.
Read more8/28/2024
0
Cause and Effect: Can Large Language Models Truly Understand Causality?
Swagata Ashwani, Kshiteesh Hegde, Nishith Reddy Mannuru, Mayank Jindal, Dushyant Singh Sengar, Krishna Chaitanya Rao Kathala, Dishant Banga, Vinija Jain, Aman Chadha
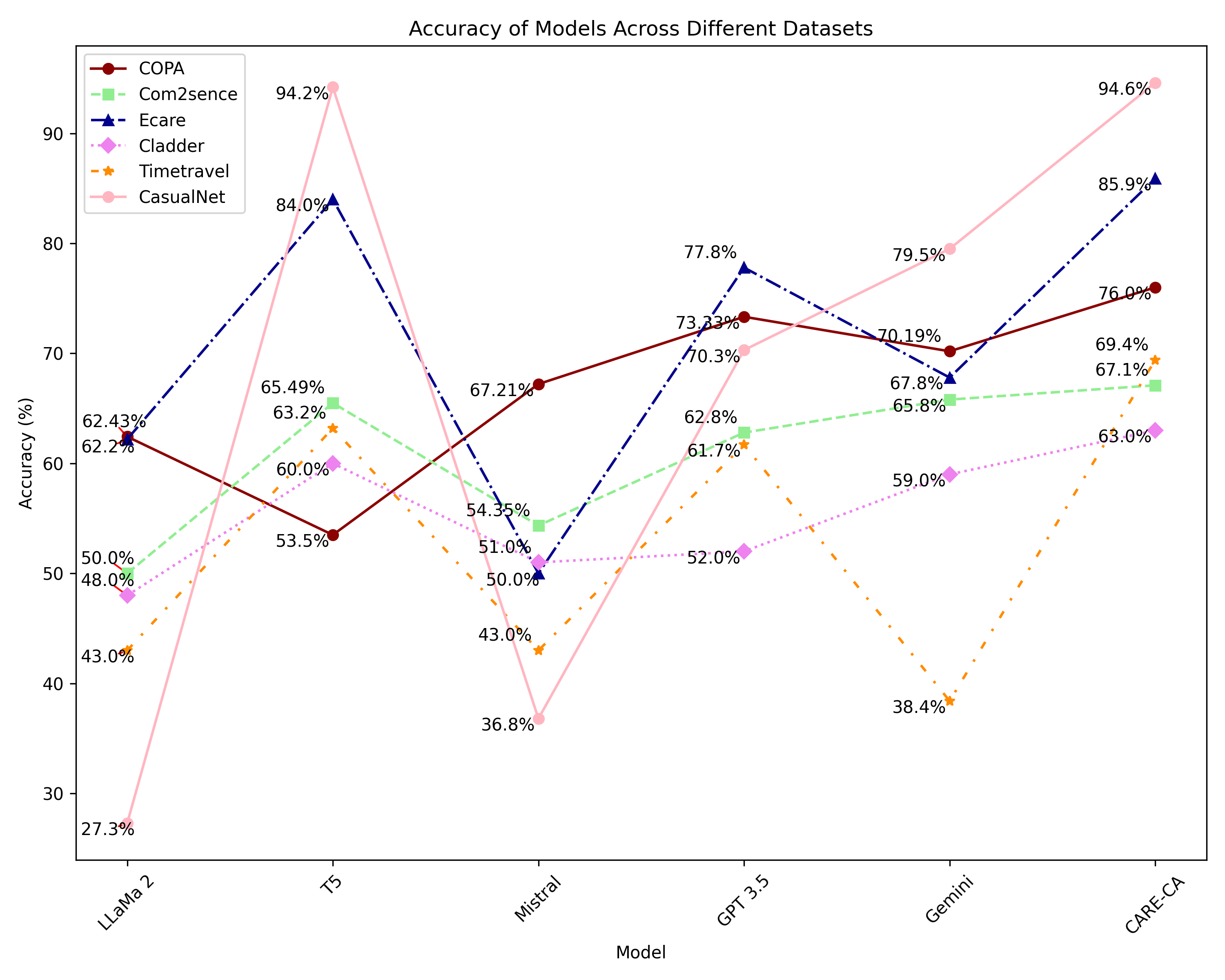
With the rise of Large Language Models(LLMs), it has become crucial to understand their capabilities and limitations in deciphering and explaining the complex web of causal relationships that language entails. Current methods use either explicit or implicit causal reasoning, yet there is a strong need for a unified approach combining both to tackle a wide array of causal relationships more effectively. This research proposes a novel architecture called Context Aware Reasoning Enhancement with Counterfactual Analysis(CARE CA) framework to enhance causal reasoning and explainability. The proposed framework incorporates an explicit causal detection module with ConceptNet and counterfactual statements, as well as implicit causal detection through LLMs. Our framework goes one step further with a layer of counterfactual explanations to accentuate LLMs understanding of causality. The knowledge from ConceptNet enhances the performance of multiple causal reasoning tasks such as causal discovery, causal identification and counterfactual reasoning. The counterfactual sentences add explicit knowledge of the not caused by scenarios. By combining these powerful modules, our model aims to provide a deeper understanding of causal relationships, enabling enhanced interpretability. Evaluation of benchmark datasets shows improved performance across all metrics, such as accuracy, precision, recall, and F1 scores. We also introduce CausalNet, a new dataset accompanied by our code, to facilitate further research in this domain.
Read more4/17/2024

0
Graph Edits for Counterfactual Explanations: A comparative study
Angeliki Dimitriou, Nikolaos Chaidos, Maria Lymperaiou, Giorgos Stamou
Counterfactuals have been established as a popular explainability technique which leverages a set of minimal edits to alter the prediction of a classifier. When considering conceptual counterfactuals on images, the edits requested should correspond to salient concepts present in the input data. At the same time, conceptual distances are defined by knowledge graphs, ensuring the optimality of conceptual edits. In this work, we extend previous endeavors on graph edits as counterfactual explanations by conducting a comparative study which encompasses both supervised and unsupervised Graph Neural Network (GNN) approaches. To this end, we pose the following significant research question: should we represent input data as graphs, which is the optimal GNN approach in terms of performance and time efficiency to generate minimal and meaningful counterfactual explanations for black-box image classifiers?
Read more4/19/2024