Missingness-resilient Video-enhanced Multimodal Disfluency Detection
2406.06964
0
0

Abstract
Most existing speech disfluency detection techniques only rely upon acoustic data. In this work, we present a practical multimodal disfluency detection approach that leverages available video data together with audio. We curate an audiovisual dataset and propose a novel fusion technique with unified weight-sharing modality-agnostic encoders to learn the temporal and semantic context. Our resilient design accommodates real-world scenarios where the video modality may sometimes be missing during inference. We also present alternative fusion strategies when both modalities are assured to be complete. In experiments across five disfluency-detection tasks, our unified multimodal approach significantly outperforms Audio-only unimodal methods, yielding an average absolute improvement of 10% (i.e., 10 percentage point increase) when both video and audio modalities are always available, and 7% even when video modality is missing in half of the samples.
Create account to get full access
Overview
- This paper presents a novel approach to disfluency detection in video-enhanced multimodal settings, where audio and video data are used to improve the performance of the disfluency detection model.
- The key idea is to develop a model that is resilient to missing data, as video data may not always be available during inference.
- The proposed model uses a combination of audio and video features to detect disfluencies, and it is designed to maintain high performance even when video data is missing.
Plain English Explanation
In this paper, the researchers developed a model that can detect disfluencies (speech errors or hesitations) in conversations by using both audio and video data. Disfluencies are common in natural speech, and detecting them can be useful for applications like automatic transcription or conversational analysis.
The researchers' approach is designed to be "missingness-resilient," which means it can still perform well even if the video data is missing during the actual use of the model. This is important because in real-world situations, video data may not always be available, such as when a person is using a voice-only interface.
The model uses a combination of audio features (like pitch, volume, and speech rhythm) and video features (like facial expressions and body language) to identify disfluencies. By using both types of data, the model can capture more nuanced information about the speaker's state and speech patterns, which can improve the accuracy of disfluency detection.
The key innovation of this work is the ability to maintain high performance even when the video data is missing. This is achieved through the model's design, which is able to effectively leverage the available audio data to compensate for the lack of video information. [This approach could be useful for a wide range of applications that involve analyzing human speech and conversations, such as improving multimodal learning or identifying schizophrenia using multimodal data.]
Technical Explanation
The researchers propose a missingness-resilient video-enhanced multimodal disfluency detection model. The model takes both audio and video data as input and uses a combination of audio and video features to detect disfluencies in the speech.
The key components of the model are:
- Audio feature extraction: The model extracts various acoustic features from the audio data, such as pitch, volume, and speech rhythm.
- Video feature extraction: The model extracts visual features from the video data, such as facial expressions and body language.
- Multimodal fusion: The audio and video features are combined using a fusion module to create a unified representation of the input.
- Disfluency detection: The fused features are then used by a classifier to detect the presence of disfluencies in the speech.
To address the issue of missing video data, the researchers introduce a missingness-resilient training approach. During training, the model is exposed to scenarios where the video data is randomly masked or removed, forcing the model to learn to rely more on the audio data when the video is unavailable.
The researchers evaluate their model on a benchmark dataset for disfluency detection and compare its performance to unimodal (audio-only or video-only) and other multimodal baselines. The results show that the proposed missingness-resilient video-enhanced model outperforms these baselines, particularly when video data is missing during inference.
[This approach could be useful for a wide range of applications that involve analyzing human speech and conversations, such as dynamic modality view selection for multimodal emotion recognition or enhanced multimodal content moderation for children's videos.]
Critical Analysis
The researchers have addressed an important challenge in multimodal disfluency detection, which is the potential for missing data, particularly video data, during inference. Their missingness-resilient approach is a valuable contribution to the field, as it allows the model to maintain high performance even when one modality is unavailable.
However, the paper does not provide a detailed analysis of the specific types of disfluencies that the model is able to detect or the relative importance of audio and video features for different disfluency types. Additionally, the paper does not discuss the computational complexity of the proposed model or its real-world deployment considerations, such as the trade-offs between model size, latency, and accuracy.
Further research could explore the generalization of the missingness-resilient approach to other multimodal tasks, such as continual event detection or multimodal emotion recognition, and investigate the model's performance in more diverse and challenging real-world scenarios.
Conclusion
The researchers have presented a novel missingness-resilient video-enhanced multimodal disfluency detection model that is able to maintain high performance even when video data is missing during inference. This is an important advancement in the field of multimodal speech analysis, as it addresses a common practical challenge in real-world applications.
The proposed approach effectively combines audio and video features to detect disfluencies, and the missingness-resilient training strategy ensures that the model can rely on the available audio data when video is not present. The results demonstrate the effectiveness of this approach compared to unimodal and other multimodal baselines.
This work has the potential to improve the accuracy and robustness of disfluency detection systems, which can benefit a wide range of applications involving speech analysis and natural language processing. Further research to explore the generalization of this approach to other multimodal tasks could lead to even more impactful advancements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
0
0
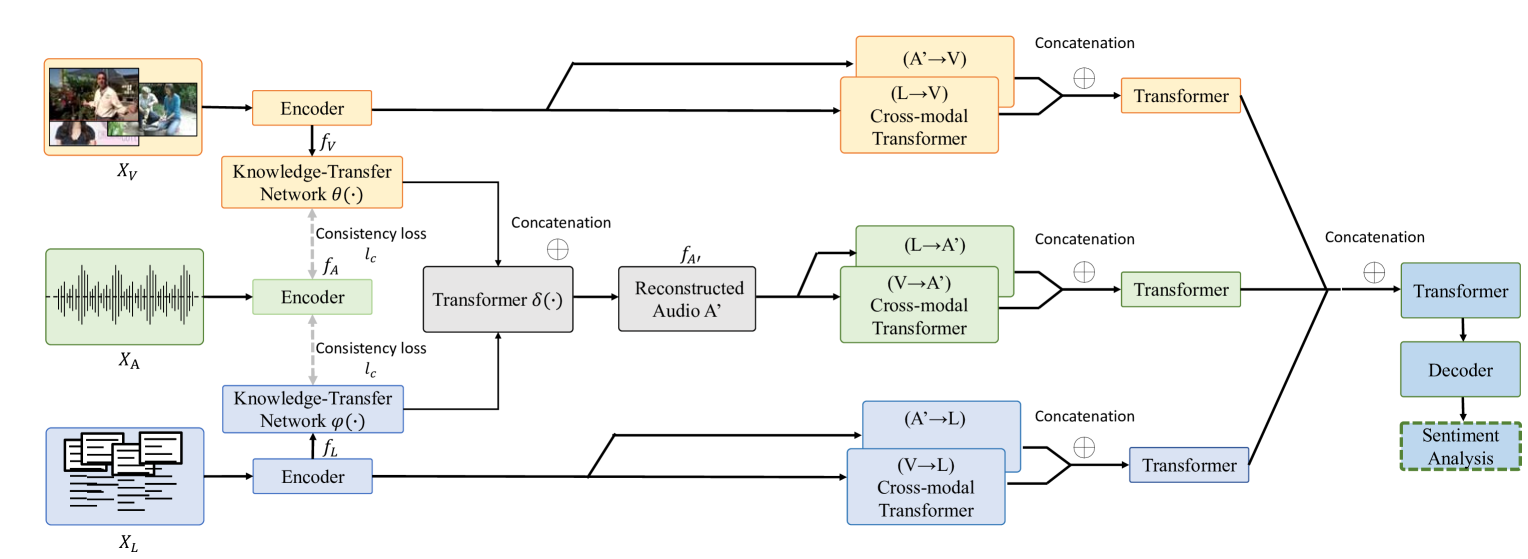
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
6/21/2024
🖼️
Enhanced Multimodal Content Moderation of Children's Videos using Audiovisual Fusion
Syed Hammad Ahmed, Muhammad Junaid Khan, Gita Sukthankar
0
0
Due to the rise in video content creation targeted towards children, there is a need for robust content moderation schemes for video hosting platforms. A video that is visually benign may include audio content that is inappropriate for young children while being impossible to detect with a unimodal content moderation system. Popular video hosting platforms for children such as YouTube Kids still publish videos which contain audio content that is not conducive to a child's healthy behavioral and physical development. A robust classification of malicious videos requires audio representations in addition to video features. However, recent content moderation approaches rarely employ multimodal architectures that explicitly consider non-speech audio cues. To address this, we present an efficient adaptation of CLIP (Contrastive Language-Image Pre-training) that can leverage contextual audio cues for enhanced content moderation. We incorporate 1) the audio modality and 2) prompt learning, while keeping the backbone modules of each modality frozen. We conduct our experiments on a multimodal version of the MOB (Malicious or Benign) dataset in supervised and few-shot settings.
5/13/2024
Dynamic Modality and View Selection for Multimodal Emotion Recognition with Missing Modalities
Luciana Trinkaus Menon, Luiz Carlos Ribeiro Neduziak, Jean Paul Barddal, Alessandro Lameiras Koerich, Alceu de Souza Britto Jr
0
0
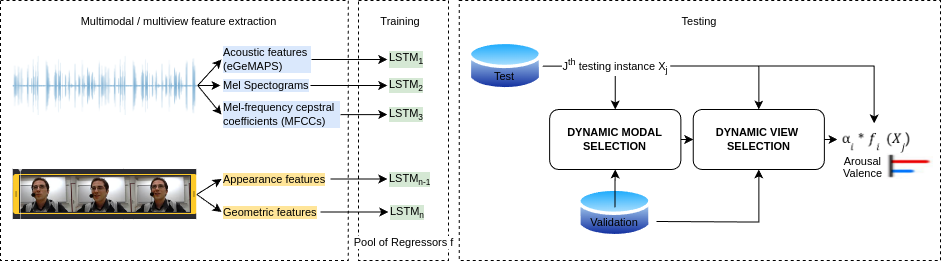
The study of human emotions, traditionally a cornerstone in fields like psychology and neuroscience, has been profoundly impacted by the advent of artificial intelligence (AI). Multiple channels, such as speech (voice) and facial expressions (image), are crucial in understanding human emotions. However, AI's journey in multimodal emotion recognition (MER) is marked by substantial technical challenges. One significant hurdle is how AI models manage the absence of a particular modality - a frequent occurrence in real-world situations. This study's central focus is assessing the performance and resilience of two strategies when confronted with the lack of one modality: a novel multimodal dynamic modality and view selection and a cross-attention mechanism. Results on the RECOLA dataset show that dynamic selection-based methods are a promising approach for MER. In the missing modalities scenarios, all dynamic selection-based methods outperformed the baseline. The study concludes by emphasizing the intricate interplay between audio and video modalities in emotion prediction, showcasing the adaptability of dynamic selection methods in handling missing modalities.
4/19/2024
📈
Improving Multimodal Learning with Multi-Loss Gradient Modulation
Konstantinos Kontras, Christos Chatzichristos, Matthew Blaschko, Maarten De Vos
0
0
Learning from multiple modalities, such as audio and video, offers opportunities for leveraging complementary information, enhancing robustness, and improving contextual understanding and performance. However, combining such modalities presents challenges, especially when modalities differ in data structure, predictive contribution, and the complexity of their learning processes. It has been observed that one modality can potentially dominate the learning process, hindering the effective utilization of information from other modalities and leading to sub-optimal model performance. To address this issue the vast majority of previous works suggest to assess the unimodal contributions and dynamically adjust the training to equalize them. We improve upon previous work by introducing a multi-loss objective and further refining the balancing process, allowing it to dynamically adjust the learning pace of each modality in both directions, acceleration and deceleration, with the ability to phase out balancing effects upon convergence. We achieve superior results across three audio-video datasets: on CREMA-D, models with ResNet backbone encoders surpass the previous best by 1.9% to 12.4%, and Conformer backbone models deliver improvements ranging from 2.8% to 14.1% across different fusion methods. On AVE, improvements range from 2.7% to 7.7%, while on UCF101, gains reach up to 6.1%.
5/14/2024