Dynamic Modality and View Selection for Multimodal Emotion Recognition with Missing Modalities
2404.12251
0
0
Abstract
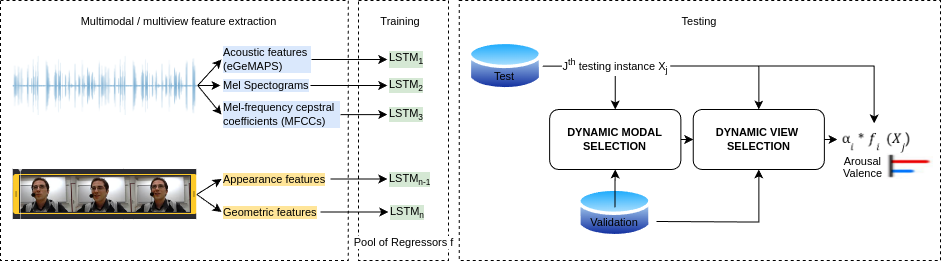
The study of human emotions, traditionally a cornerstone in fields like psychology and neuroscience, has been profoundly impacted by the advent of artificial intelligence (AI). Multiple channels, such as speech (voice) and facial expressions (image), are crucial in understanding human emotions. However, AI's journey in multimodal emotion recognition (MER) is marked by substantial technical challenges. One significant hurdle is how AI models manage the absence of a particular modality - a frequent occurrence in real-world situations. This study's central focus is assessing the performance and resilience of two strategies when confronted with the lack of one modality: a novel multimodal dynamic modality and view selection and a cross-attention mechanism. Results on the RECOLA dataset show that dynamic selection-based methods are a promising approach for MER. In the missing modalities scenarios, all dynamic selection-based methods outperformed the baseline. The study concludes by emphasizing the intricate interplay between audio and video modalities in emotion prediction, showcasing the adaptability of dynamic selection methods in handling missing modalities.
Create account to get full access
Overview
- This paper introduces a novel approach for multimodal emotion recognition in scenarios with missing modalities.
- The proposed method, called Dynamic Modality and View Selection (DMVS), can dynamically select the most informative modalities and views for emotion recognition based on the available data.
- DMVS aims to address the challenge of missing modalities, which is common in real-world applications, by adaptively leveraging the remaining modalities to maintain robust recognition performance.
Plain English Explanation
Emotion recognition is an important task with many practical applications, such as in human-computer interaction, mental health monitoring, and social robotics. When dealing with real-world data, it's common for some of the necessary information (known as "modalities") to be missing. For example, a video recording may be missing the audio or the facial expressions of the person being observed.
The authors of this paper have developed a new technique called Dynamic Modality and View Selection (DMVS) that can adapt to these missing modalities. Instead of relying on a fixed set of modalities, DMVS dynamically selects the most useful information from the available data to make accurate emotion predictions. This allows the system to maintain robust performance even when some of the expected data is not present.
The key innovation of DMVS is its ability to intelligently choose the best combination of modalities and "views" (different representations of the data) to use for emotion recognition. By adapting to the specific data at hand, DMVS can extract the maximum amount of relevant information to make high-quality predictions, even in the face of missing data.
This flexible and adaptive approach represents an important advancement in the field of multimodal emotion recognition, which has traditionally struggled with the challenges of missing or incomplete data. The DMVS method holds the potential to enable more reliable and practical emotion recognition systems that can be deployed in real-world settings.
Technical Explanation
The proposed Dynamic Modality and View Selection (DMVS) framework addresses the problem of multimodal emotion recognition in the presence of missing modalities. Unlike traditional approaches that rely on a fixed set of modalities, DMVS dynamically selects the most informative modalities and views (different representations of the data) to maintain robust recognition performance.
The key components of DMVS include:
- Modality Selector: This module dynamically determines the most relevant modalities based on the available data, using a gating mechanism to adaptively combine the modalities.
- View Selector: This component selects the optimal views (e.g., different feature representations) for each modality to further enhance the recognition accuracy.
- Emotion Classifier: The final emotion prediction is made by fusing the selected modalities and views using a multimodal fusion module.
The authors evaluate DMVS on several multimodal emotion recognition datasets, including SEWA, MMED, and RECOLA. The results demonstrate that DMVS outperforms state-of-the-art methods in terms of recognition accuracy, particularly in scenarios with missing modalities.
Critical Analysis
The DMVS approach addresses an important challenge in multimodal emotion recognition, namely the ability to handle missing modalities. By dynamically selecting the most informative modalities and views, the method can maintain high recognition accuracy even when some data is unavailable.
One potential limitation of the study is the evaluation on a relatively small number of datasets. While the results are promising, it would be helpful to see the performance of DMVS on a wider range of multimodal emotion recognition benchmarks to better understand its generalization capabilities.
Additionally, the authors do not provide much insight into the specific modalities and views that are selected by the DMVS framework in different scenarios. Understanding these patterns could lead to valuable insights about the relative importance of various data sources for emotion recognition.
Further research could also explore the integration of DMVS with other advanced multimodal fusion techniques, potentially leading to even more robust and accurate emotion recognition systems.
Conclusion
The Dynamic Modality and View Selection (DMVS) framework presented in this paper represents an important advancement in the field of multimodal emotion recognition. By dynamically selecting the most informative modalities and views, DMVS can maintain high recognition accuracy even when some data is missing, a common challenge in real-world applications.
The authors' evaluation on several benchmark datasets demonstrates the effectiveness of the DMVS approach, and the method's flexible and adaptive nature holds the potential to enable more reliable and practical emotion recognition systems. As the field of multimodal AI continues to evolve, techniques like DMVS will play a crucial role in pushing the boundaries of what is possible in areas such as human-computer interaction, mental health monitoring, and social robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
0
0
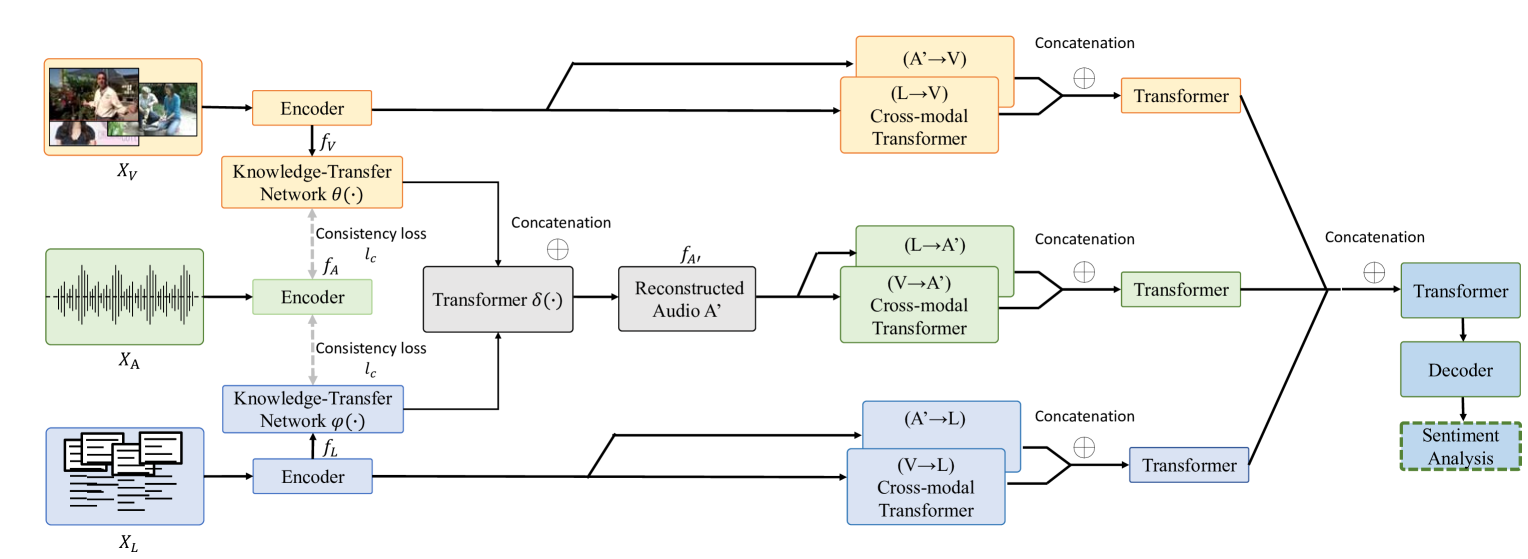
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
6/21/2024
MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild
Kateryna Chumachenko, Alexandros Iosifidis, Moncef Gabbouj
0
0
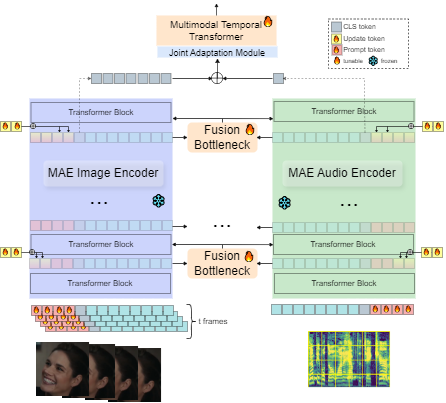
Dynamic Facial Expression Recognition (DFER) has received significant interest in the recent years dictated by its pivotal role in enabling empathic and human-compatible technologies. Achieving robustness towards in-the-wild data in DFER is particularly important for real-world applications. One of the directions aimed at improving such models is multimodal emotion recognition based on audio and video data. Multimodal learning in DFER increases the model capabilities by leveraging richer, complementary data representations. Within the field of multimodal DFER, recent methods have focused on exploiting advances of self-supervised learning (SSL) for pre-training of strong multimodal encoders. Another line of research has focused on adapting pre-trained static models for DFER. In this work, we propose a different perspective on the problem and investigate the advancement of multimodal DFER performance by adapting SSL-pre-trained disjoint unimodal encoders. We identify main challenges associated with this task, namely, intra-modality adaptation, cross-modal alignment, and temporal adaptation, and propose solutions to each of them. As a result, we demonstrate improvement over current state-of-the-art on two popular DFER benchmarks, namely DFEW and MFAW.
4/16/2024
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
0
0
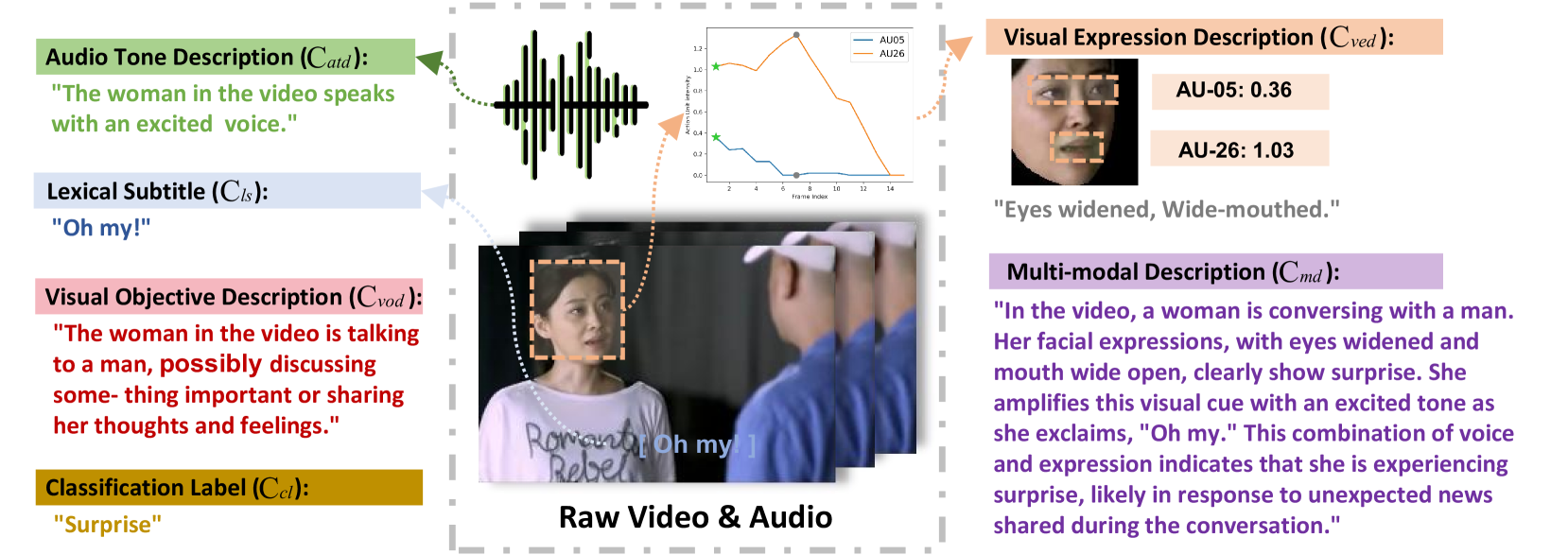
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
6/18/2024

Joint Multimodal Transformer for Emotion Recognition in the Wild
Paul Waligora, Haseeb Aslam, Osama Zeeshan, Soufiane Belharbi, Alessandro Lameiras Koerich, Marco Pedersoli, Simon Bacon, Eric Granger
0
0
Multimodal emotion recognition (MMER) systems typically outperform unimodal systems by leveraging the inter- and intra-modal relationships between, e.g., visual, textual, physiological, and auditory modalities. This paper proposes an MMER method that relies on a joint multimodal transformer (JMT) for fusion with key-based cross-attention. This framework can exploit the complementary nature of diverse modalities to improve predictive accuracy. Separate backbones capture intra-modal spatiotemporal dependencies within each modality over video sequences. Subsequently, our JMT fusion architecture integrates the individual modality embeddings, allowing the model to effectively capture inter- and intra-modal relationships. Extensive experiments on two challenging expression recognition tasks -- (1) dimensional emotion recognition on the Affwild2 dataset (with face and voice) and (2) pain estimation on the Biovid dataset (with face and biosensors) -- indicate that our JMT fusion can provide a cost-effective solution for MMER. Empirical results show that MMER systems with our proposed fusion allow us to outperform relevant baseline and state-of-the-art methods.
4/23/2024