Mitigating Backdoor Attacks using Activation-Guided Model Editing

0
Sign in to get full access
Overview
- This paper proposes a method called "Activation-Guided Model Editing" to mitigate backdoor attacks on machine learning models.
- Backdoor attacks are a type of security vulnerability where a model is trained to behave maliciously when triggered by a specific input pattern.
- The proposed method aims to identify and remove the backdoor by modifying the model's parameters based on the activation patterns of the trigger input.
Plain English Explanation
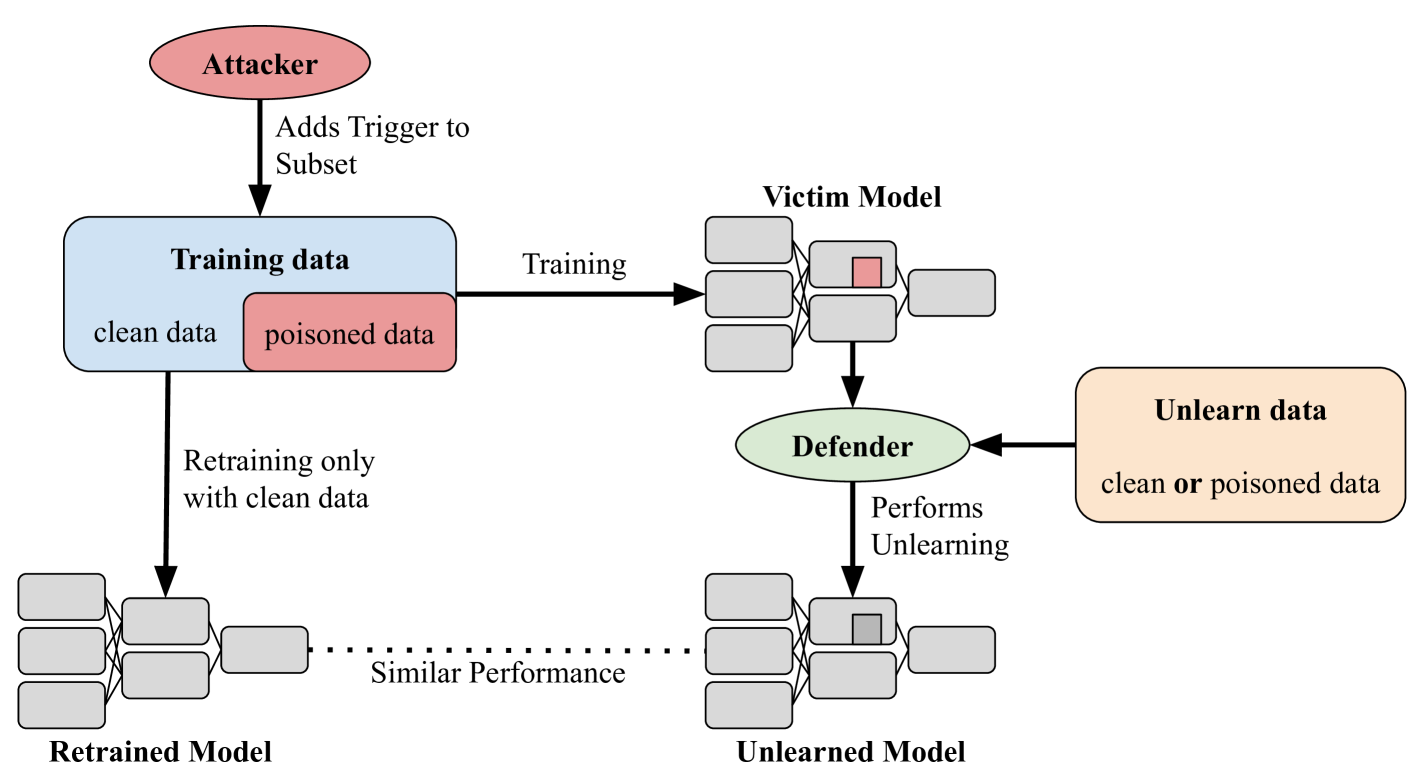
Imagine you have a machine learning model that is supposed to recognize images of dogs. But someone has secretly tampered with the model so that whenever they show it a picture of a dog with a small red dot in the corner, the model wrongly classifies it as a cat. This is called a backdoor attack - the model has been tricked into behaving in an unintended way.
The researchers in this paper developed a way to detect and fix this backdoor problem. Their key idea is to look at how the model's "neurons" (the individual components that make up the model) are activated when you show it the trigger input with the red dot. By analyzing these activation patterns, they can identify which parts of the model are responsible for the backdoor behavior, and then adjust those parts to remove the backdoor.
This is like finding the hidden switch that the attacker installed in the model, and then disabling it so the model goes back to correctly recognizing dogs. The paper shows that this activation-guided editing approach can effectively mitigate backdoor attacks without harming the model's overall performance on normal inputs.
Technical Explanation
The key technical elements of this paper include:
-
Activation-Guided Editing: The proposed method analyzes the activation patterns of the model when presented with the backdoor trigger input. It then uses this information to selectively modify the model's parameters in order to reduce the model's responsiveness to the backdoor trigger.
-
Unlearning Backdoor: The paper builds on prior work on model unlearning and gradient-based backdoor removal, but adds the activation-guided component to more precisely target the backdoor.
-
Evaluation: The authors evaluate their method on standard backdoor benchmarks, showing that it can effectively mitigate backdoor attacks while preserving the model's clean-data performance, in contrast with some prior backdoor defense methods that may introduce new vulnerabilities.
-
Proactive Defense: The paper also explores a "proactive defense" variant that injects synthetic backdoor samples during training, similar to prior work, to further strengthen the model against backdoor attacks.
Critical Analysis
The paper provides a promising approach for mitigating backdoor attacks, but a few potential limitations are worth noting:
- The method still requires access to the backdoor trigger input during the editing process, which may not always be feasible in real-world scenarios.
- The effectiveness of the approach may depend on the specific type and implementation of the backdoor attack, and further research is needed to understand its generalizability.
- The paper does not deeply explore the potential for unintended consequences or side effects of the model editing process, which could be an area for further investigation.
Overall, the activation-guided model editing technique represents an important step forward in the ongoing efforts to mitigate the risks of backdoor attacks and enhance the security of machine learning systems.
Conclusion
This paper presents a novel approach called "Activation-Guided Model Editing" to effectively mitigate backdoor attacks on machine learning models. By analyzing the activation patterns of the model when presented with the backdoor trigger input, the method can identify and remove the backdoor vulnerability without significantly impacting the model's overall performance. While more research is needed to fully understand the limitations and broader applicability of this technique, it represents an important advance in the ongoing efforts to secure machine learning systems against malicious attacks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mitigating Backdoor Attacks using Activation-Guided Model Editing
Felix Hsieh, Huy H. Nguyen, AprilPyone MaungMaung, Dmitrii Usynin, Isao Echizen
Backdoor attacks compromise the integrity and reliability of machine learning models by embedding a hidden trigger during the training process, which can later be activated to cause unintended misbehavior. We propose a novel backdoor mitigation approach via machine unlearning to counter such backdoor attacks. The proposed method utilizes model activation of domain-equivalent unseen data to guide the editing of the model's weights. Unlike the previous unlearning-based mitigation methods, ours is computationally inexpensive and achieves state-of-the-art performance while only requiring a handful of unseen samples for unlearning. In addition, we also point out that unlearning the backdoor may cause the whole targeted class to be unlearned, thus introducing an additional repair step to preserve the model's utility after editing the model. Experiment results show that the proposed method is effective in unlearning the backdoor on different datasets and trigger patterns.
Read more7/11/2024
⛏️
0
Unveiling and Mitigating Backdoor Vulnerabilities based on Unlearning Weight Changes and Backdoor Activeness
Weilin Lin, Li Liu, Shaokui Wei, Jianze Li, Hui Xiong
The security threat of backdoor attacks is a central concern for deep neural networks (DNNs). Recently, without poisoned data, unlearning models with clean data and then learning a pruning mask have contributed to backdoor defense. Additionally, vanilla fine-tuning with those clean data can help recover the lost clean accuracy. However, the behavior of clean unlearning is still under-explored, and vanilla fine-tuning unintentionally induces back the backdoor effect. In this work, we first investigate model unlearning from the perspective of weight changes and gradient norms, and find two interesting observations in the backdoored model: 1) the weight changes between poison and clean unlearning are positively correlated, making it possible for us to identify the backdoored-related neurons without using poisoned data; 2) the neurons of the backdoored model are more active (i.e., larger changes in gradient norm) than those in the clean model, suggesting the need to suppress the gradient norm during fine-tuning. Then, we propose an effective two-stage defense method. In the first stage, an efficient Neuron Weight Change (NWC)-based Backdoor Reinitialization is proposed based on observation 1). In the second stage, based on observation 2), we design an Activeness-Aware Fine-Tuning to replace the vanilla fine-tuning. Extensive experiments, involving eight backdoor attacks on three benchmark datasets, demonstrate the superior performance of our proposed method compared to recent state-of-the-art backdoor defense approaches.
Read more5/31/2024
📈
0
Unlearning Backdoor Attacks through Gradient-Based Model Pruning
Kealan Dunnett, Reza Arablouei, Dimity Miller, Volkan Dedeoglu, Raja Jurdak
In the era of increasing concerns over cybersecurity threats, defending against backdoor attacks is paramount in ensuring the integrity and reliability of machine learning models. However, many existing approaches require substantial amounts of data for effective mitigation, posing significant challenges in practical deployment. To address this, we propose a novel approach to counter backdoor attacks by treating their mitigation as an unlearning task. We tackle this challenge through a targeted model pruning strategy, leveraging unlearning loss gradients to identify and eliminate backdoor elements within the model. Built on solid theoretical insights, our approach offers simplicity and effectiveness, rendering it well-suited for scenarios with limited data availability. Our methodology includes formulating a suitable unlearning loss and devising a model-pruning technique tailored for convolutional neural networks. Comprehensive evaluations demonstrate the efficacy of our proposed approach compared to state-of-the-art approaches, particularly in realistic data settings.
Read more5/8/2024

0
Breaking the False Sense of Security in Backdoor Defense through Re-Activation Attack
Mingli Zhu, Siyuan Liang, Baoyuan Wu
Deep neural networks face persistent challenges in defending against backdoor attacks, leading to an ongoing battle between attacks and defenses. While existing backdoor defense strategies have shown promising performance on reducing attack success rates, can we confidently claim that the backdoor threat has truly been eliminated from the model? To address it, we re-investigate the characteristics of the backdoored models after defense (denoted as defense models). Surprisingly, we find that the original backdoors still exist in defense models derived from existing post-training defense strategies, and the backdoor existence is measured by a novel metric called backdoor existence coefficient. It implies that the backdoors just lie dormant rather than being eliminated. To further verify this finding, we empirically show that these dormant backdoors can be easily re-activated during inference, by manipulating the original trigger with well-designed tiny perturbation using universal adversarial attack. More practically, we extend our backdoor reactivation to black-box scenario, where the defense model can only be queried by the adversary during inference, and develop two effective methods, i.e., query-based and transfer-based backdoor re-activation attacks. The effectiveness of the proposed methods are verified on both image classification and multimodal contrastive learning (i.e., CLIP) tasks. In conclusion, this work uncovers a critical vulnerability that has never been explored in existing defense strategies, emphasizing the urgency of designing more robust and advanced backdoor defense mechanisms in the future.
Read more5/31/2024