Mitigating Hallucinations in Large Language Models via Self-Refinement-Enhanced Knowledge Retrieval
2405.06545
0
0
💬
Abstract
Large language models (LLMs) have demonstrated remarkable capabilities across various domains, although their susceptibility to hallucination poses significant challenges for their deployment in critical areas such as healthcare. To address this issue, retrieving relevant facts from knowledge graphs (KGs) is considered a promising method. Existing KG-augmented approaches tend to be resource-intensive, requiring multiple rounds of retrieval and verification for each factoid, which impedes their application in real-world scenarios. In this study, we propose Self-Refinement-Enhanced Knowledge Graph Retrieval (Re-KGR) to augment the factuality of LLMs' responses with less retrieval efforts in the medical field. Our approach leverages the attribution of next-token predictive probability distributions across different tokens, and various model layers to primarily identify tokens with a high potential for hallucination, reducing verification rounds by refining knowledge triples associated with these tokens. Moreover, we rectify inaccurate content using retrieved knowledge in the post-processing stage, which improves the truthfulness of generated responses. Experimental results on a medical dataset demonstrate that our approach can enhance the factual capability of LLMs across various foundational models as evidenced by the highest scores on truthfulness.
Create account to get full access
Overview
- Large language models (LLMs) have become remarkably capable, but they can sometimes produce inaccurate or "hallucinatory" information.
- Retrieving relevant facts from knowledge graphs (KGs) is a promising way to address this issue and improve the factual accuracy of LLM responses.
- Existing KG-augmented approaches tend to be resource-intensive, requiring multiple rounds of retrieval and verification for each piece of information.
Plain English Explanation
Large language models, advanced artificial intelligence systems that can generate human-like text, have made impressive breakthroughs in a variety of tasks. However, one of the key challenges with these models is their tendency to sometimes produce information that is inaccurate or made up, a phenomenon known as "hallucination."
To tackle this problem, researchers are exploring the use of knowledge graphs - structured databases of facts and information. By retrieving relevant facts from a knowledge graph and incorporating them into the language model's responses, the hope is to improve the truthfulness and reliability of the model's outputs.
Unfortunately, the current approaches to integrating knowledge graphs with language models can be quite resource-intensive, requiring multiple rounds of searching and verifying information. This can make it challenging to apply these techniques in real-world, time-sensitive scenarios, such as in the medical field.
Technical Explanation
In this study, the researchers propose a new method called "Self-Refinement-Enhanced Knowledge Graph Retrieval" (Re-KGR) to more efficiently augment the factual accuracy of LLMs' responses in the medical domain.
The key innovation of Re-KGR is that it leverages the language model's own internal probability distributions to identify tokens (individual words or subwords) that are more likely to be hallucinated. It then focuses the knowledge graph retrieval process on refining the information associated with these high-risk tokens, reducing the overall number of retrieval and verification steps required.
Additionally, the researchers incorporate a post-processing stage that uses the retrieved knowledge to directly correct any inaccuracies in the model's generated text, further enhancing the truthfulness of the final output.
The researchers evaluate their approach on a medical dataset and find that Re-KGR is able to improve the factual capability of LLMs across various foundational models, as evidenced by the highest scores on measures of truthfulness.
Critical Analysis
The paper presents a promising approach to reducing hallucination in large language models through the use of knowledge graph retrieval. The key strengths are the efficiency gains achieved by selectively targeting high-risk tokens for retrieval and the post-processing step that directly corrects inaccuracies.
However, the paper does not address certain limitations, such as the potential for bias or errors in the underlying knowledge graph, or the scalability of the approach to very large language models and broad domains beyond the medical field. Additionally, the paper does not explore the potential trade-offs between improving factual accuracy and maintaining the fluency and coherence of the generated text.
Further research would be valuable to address these concerns and explore the broader applicability of the Re-KGR approach to other domains and use cases.
Conclusion
This study presents a novel technique called Re-KGR that leverages language model internals and knowledge graph retrieval to enhance the factual accuracy of large language model outputs, with a particular focus on the medical domain. The efficiency gains and post-processing corrections demonstrated in the experiments suggest that this approach could be a valuable tool for deploying LLMs in critical applications where factual reliability is of the utmost importance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
Self-Alignment for Factuality: Mitigating Hallucinations in LLMs via Self-Evaluation
Xiaoying Zhang, Baolin Peng, Ye Tian, Jingyan Zhou, Lifeng Jin, Linfeng Song, Haitao Mi, Helen Meng
0
0
Despite showing increasingly human-like abilities, large language models (LLMs) often struggle with factual inaccuracies, i.e. hallucinations, even when they hold relevant knowledge. To address these hallucinations, current approaches typically necessitate high-quality human factuality annotations. In this work, we explore Self-Alignment for Factuality, where we leverage the self-evaluation capability of an LLM to provide training signals that steer the model towards factuality. Specifically, we incorporate Self-Eval, a self-evaluation component, to prompt an LLM to validate the factuality of its own generated responses solely based on its internal knowledge. Additionally, we design Self-Knowledge Tuning (SK-Tuning) to augment the LLM's self-evaluation ability by improving the model's confidence estimation and calibration. We then utilize these self-annotated responses to fine-tune the model via Direct Preference Optimization algorithm. We show that the proposed self-alignment approach substantially enhances factual accuracy over Llama family models across three key knowledge-intensive tasks on TruthfulQA and BioGEN.
6/12/2024
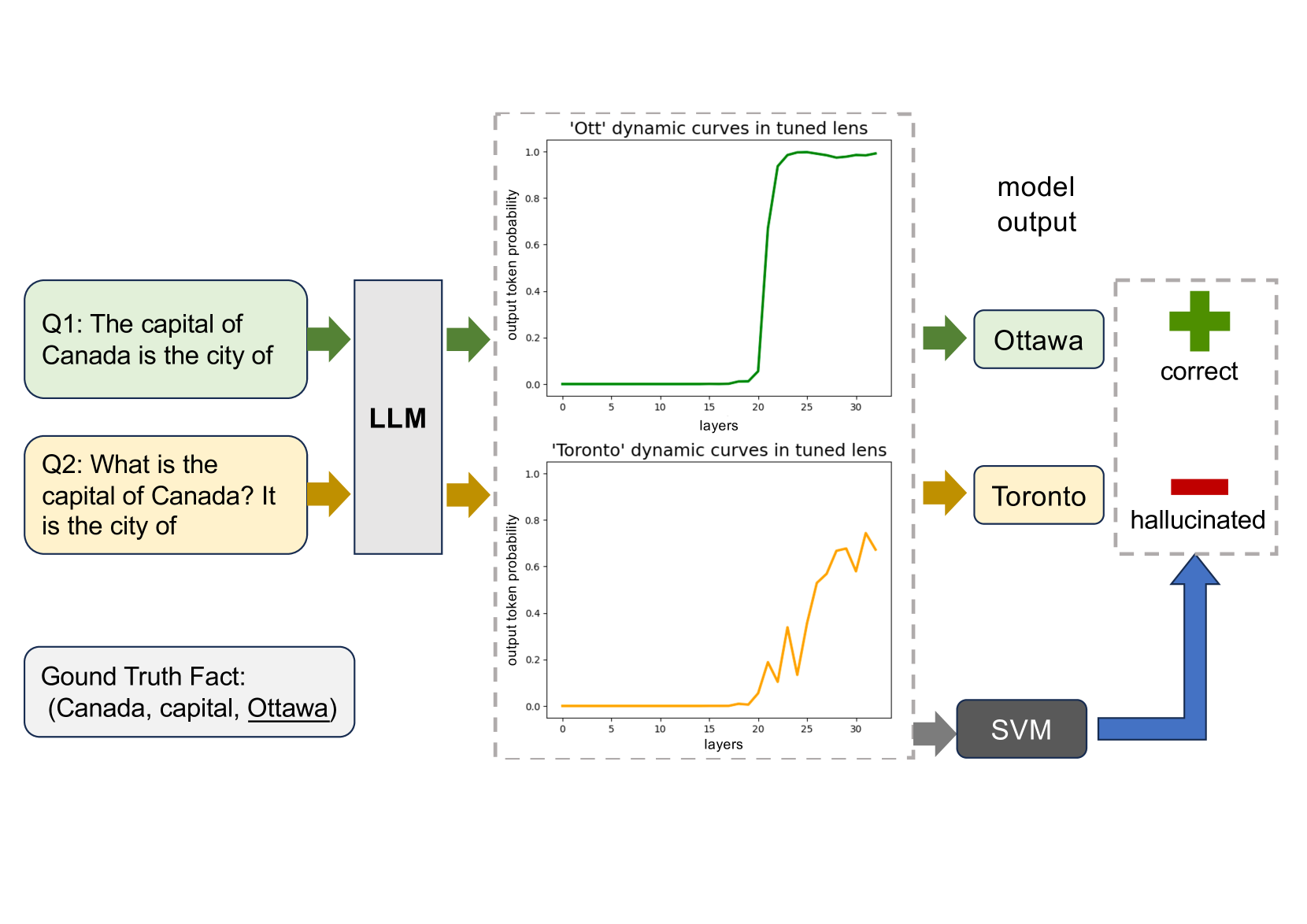
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
0
0
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
4/1/2024

Knowledge Verification to Nip Hallucination in the Bud
Fanqi Wan, Xinting Huang, Leyang Cui, Xiaojun Quan, Wei Bi, Shuming Shi
0
0
While large language models (LLMs) have demonstrated exceptional performance across various tasks following human alignment, they may still generate responses that sound plausible but contradict factual knowledge, a phenomenon known as emph{hallucination}. In this paper, we demonstrate the feasibility of mitigating hallucinations by verifying and minimizing the inconsistency between external knowledge present in the alignment data and the intrinsic knowledge embedded within foundation LLMs. Specifically, we propose a novel approach called Knowledge Consistent Alignment (KCA), which employs a well-aligned LLM to automatically formulate assessments based on external knowledge to evaluate the knowledge boundaries of foundation LLMs. To address knowledge inconsistencies in the alignment data, KCA implements several specific strategies to deal with these data instances. We demonstrate the superior efficacy of KCA in reducing hallucinations across six benchmarks, utilizing foundation LLMs of varying backbones and scales. This confirms the effectiveness of mitigating hallucinations by reducing knowledge inconsistency. Our code, model weights, and data are openly accessible at url{https://github.com/fanqiwan/KCA}.
4/17/2024

Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Priyesh Vakharia, Devavrat Joshi, Meenal Chavan, Dhananjay Sonawane, Bhrigu Garg, Parsa Mazaheri
0
0
Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
4/4/2024