SCANNER: Knowledge-Enhanced Approach for Robust Multi-modal Named Entity Recognition of Unseen Entities

0
Sign in to get full access
Overview
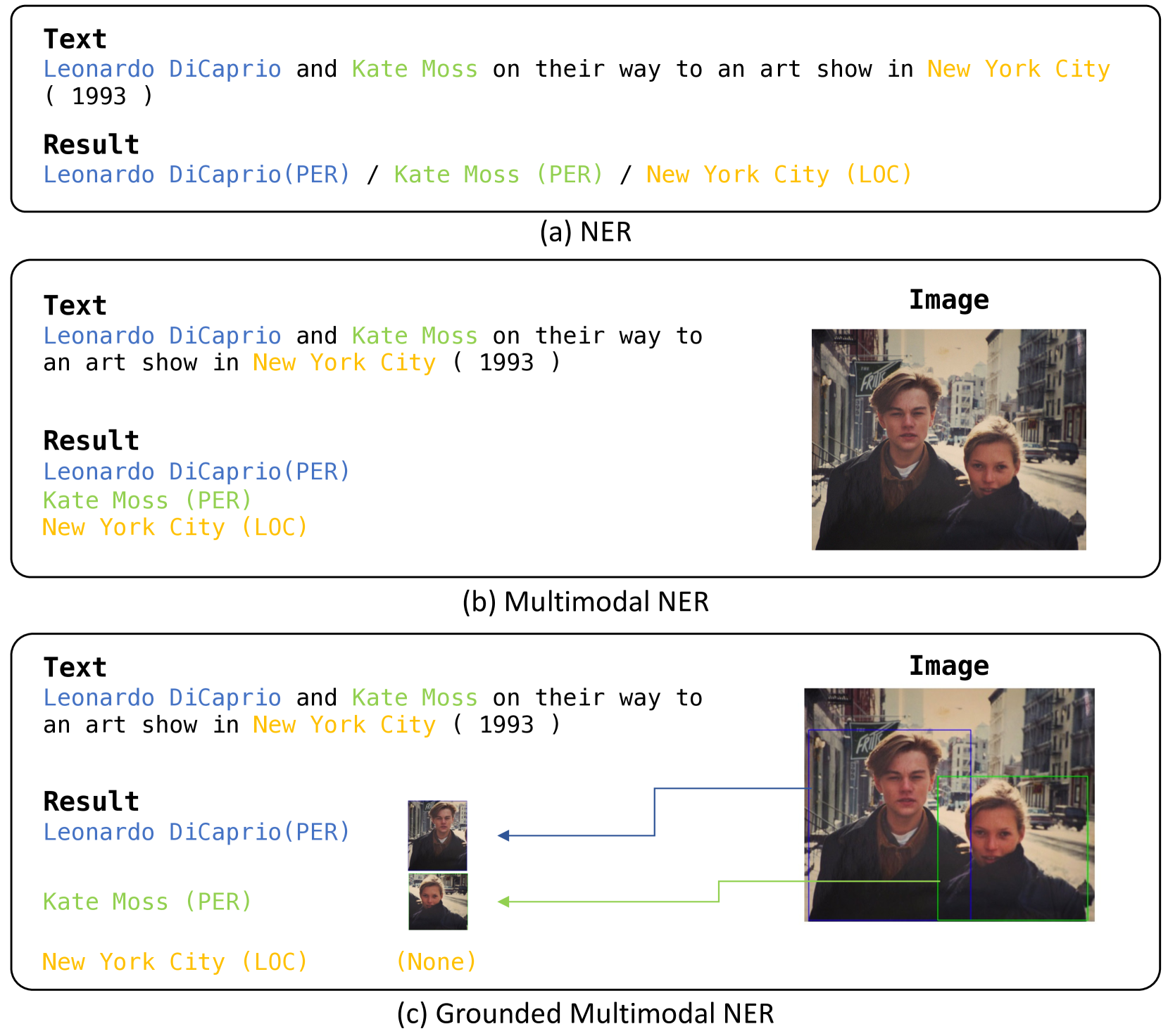
- The paper introduces SCANNER, a knowledge-enhanced approach for robust multi-modal named entity recognition (NER) that can identify unseen entities.
- SCANNER leverages both textual and visual information to improve NER performance, especially for entities not seen during training.
- The model uses a knowledge graph to incorporate external knowledge and enhance its understanding of entities.
Plain English Explanation
SCANNER is a new AI system that can identify names of people, places, organizations, and other entities in text and images. It's designed to work well even for entities the system hasn't seen before during training.
Most existing NER systems rely only on the text, which can struggle with unfamiliar or unusual entities. SCANNER instead uses both the text and visual information from any accompanying images. It also taps into a knowledge graph - a database of facts about the world - to gain a deeper understanding of different entities.
This combination of textual, visual, and knowledge-based cues allows SCANNER to recognize a wider range of entities, including ones it hasn't encountered before. This can be especially useful for analyzing news articles, social media posts, or other real-world text that often contains references to newly emerging people, places, and things.
Technical Explanation
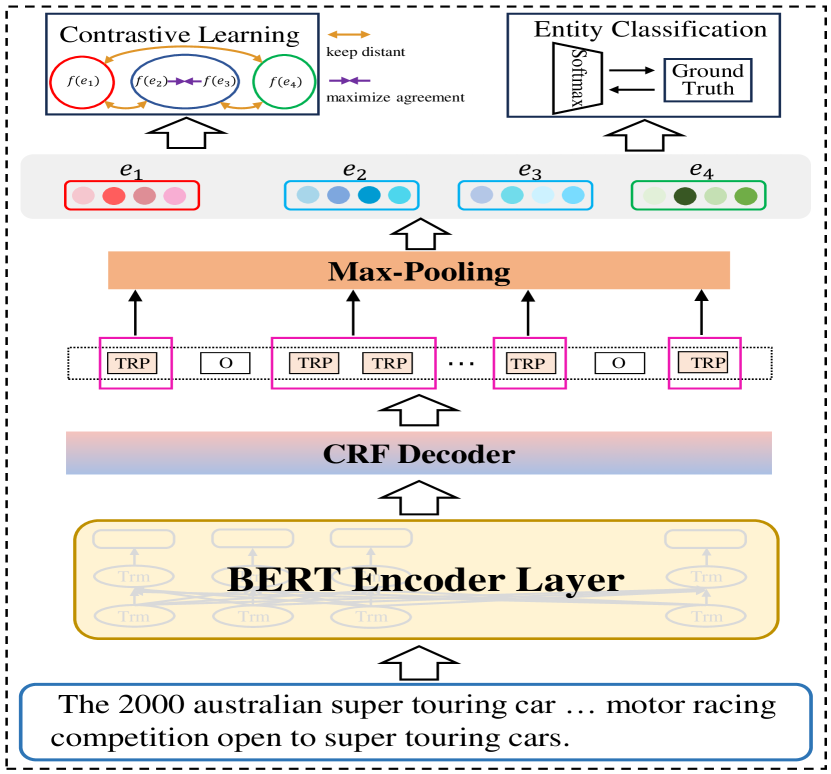
The key innovations in SCANNER include:
-
Multimodal entity representation: SCANNER learns a joint embedding space to represent entities using both textual and visual features. This allows the model to leverage complementary information from text and images.
-
Knowledge graph encoding: SCANNER incorporates external knowledge by encoding information from a knowledge graph into its entity representations. This provides additional context about the semantic relationships between entities.
-
Adaptive entity prediction: The model dynamically adapts its entity prediction based on the confidence of its textual and visual signals, as well as the availability of knowledge graph information. This allows it to handle a wide range of entity types, including unseen ones.
The authors evaluate SCANNER on several standard NER benchmarks, as well as a new dataset they created to assess performance on unseen entities. They show that SCANNER outperforms previous state-of-the-art models, especially for entities that did not appear in the training data.
Critical Analysis
The authors acknowledge that SCANNER's reliance on external knowledge graphs introduces some limitations. The performance of the model will depend on the coverage and quality of the knowledge graph used. Additionally, the model may struggle with entities that have limited or noisy information in the knowledge graph.
Another potential issue is the interpretability of the model's predictions. While the multimodal and knowledge-enhanced approach improves performance, it can be difficult to understand the specific reasons behind the model's decisions. Providing more transparency around the model's reasoning could be an area for future work.
Overall, SCANNER represents a promising advance in multi-modal NER, particularly for handling unseen entities. The authors have demonstrated the value of combining textual, visual, and knowledge-based cues to enhance entity recognition in real-world applications.
Conclusion
The SCANNER model introduces a novel knowledge-enhanced approach to multi-modal named entity recognition. By leveraging both textual and visual information, as well as external knowledge graphs, SCANNER can identify a wider range of entities, including those not encountered during training. This capability makes SCANNER a valuable tool for analyzing text and images in domains where new entities are constantly emerging, such as news, social media, and scientific literature.
The authors have made an important contribution to the field of NER, demonstrating how the integration of multiple modalities and external knowledge can significantly improve the robustness and generalization of entity recognition systems. While the model has some limitations, SCANNER represents a significant step forward in addressing the challenge of recognizing unseen entities in real-world data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SCANNER: Knowledge-Enhanced Approach for Robust Multi-modal Named Entity Recognition of Unseen Entities
Hyunjong Ok, Taeho Kil, Sukmin Seo, Jaeho Lee
Recent advances in named entity recognition (NER) have pushed the boundary of the task to incorporate visual signals, leading to many variants, including multi-modal NER (MNER) or grounded MNER (GMNER). A key challenge to these tasks is that the model should be able to generalize to the entities unseen during the training, and should be able to handle the training samples with noisy annotations. To address this obstacle, we propose SCANNER (Span CANdidate detection and recognition for NER), a model capable of effectively handling all three NER variants. SCANNER is a two-stage structure; we extract entity candidates in the first stage and use it as a query to get knowledge, effectively pulling knowledge from various sources. We can boost our performance by utilizing this entity-centric extracted knowledge to address unseen entities. Furthermore, to tackle the challenges arising from noisy annotations in NER datasets, we introduce a novel self-distillation method, enhancing the robustness and accuracy of our model in processing training data with inherent uncertainties. Our approach demonstrates competitive performance on the NER benchmark and surpasses existing methods on both MNER and GMNER benchmarks. Further analysis shows that the proposed distillation and knowledge utilization methods improve the performance of our model on various benchmarks.
Read more4/3/2024
0
Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning
Peipei Liu, Gaosheng Wang, Ying Tong, Jian Liang, Zhenquan Ding, Hongsong Zhu
Few-shot named entity recognition can identify new types of named entities based on a few labeled examples. Previous methods employing token-level or span-level metric learning suffer from the computational burden and a large number of negative sample spans. In this paper, we propose the Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning (MsFNER), which splits the general NER into two stages: entity-span detection and entity classification. There are 3 processes for introducing MsFNER: training, finetuning, and inference. In the training process, we train and get the best entity-span detection model and the entity classification model separately on the source domain using meta-learning, where we create a contrastive learning module to enhance entity representations for entity classification. During finetuning, we finetune the both models on the support dataset of target domain. In the inference process, for the unlabeled data, we first detect the entity-spans, then the entity-spans are jointly determined by the entity classification model and the KNN. We conduct experiments on the open FewNERD dataset and the results demonstrate the advance of MsFNER.
Read more4/11/2024
💬
0
2M-NER: Contrastive Learning for Multilingual and Multimodal NER with Language and Modal Fusion
Dongsheng Wang, Xiaoqin Feng, Zeming Liu, Chuan Wang
Named entity recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities in sentences into pre-defined types. It plays a crucial role in various research fields, including entity linking, question answering, and online product recommendation. Recent studies have shown that incorporating multilingual and multimodal datasets can enhance the effectiveness of NER. This is due to language transfer learning and the presence of shared implicit features across different modalities. However, the lack of a dataset that combines multilingualism and multimodality has hindered research exploring the combination of these two aspects, as multimodality can help NER in multiple languages simultaneously. In this paper, we aim to address a more challenging task: multilingual and multimodal named entity recognition (MMNER), considering its potential value and influence. Specifically, we construct a large-scale MMNER dataset with four languages (English, French, German and Spanish) and two modalities (text and image). To tackle this challenging MMNER task on the dataset, we introduce a new model called 2M-NER, which aligns the text and image representations using contrastive learning and integrates a multimodal collaboration module to effectively depict the interactions between the two modalities. Extensive experimental results demonstrate that our model achieves the highest F1 score in multilingual and multimodal NER tasks compared to some comparative and representative baselines. Additionally, in a challenging analysis, we discovered that sentence-level alignment interferes a lot with NER models, indicating the higher level of difficulty in our dataset.
Read more4/29/2024

0
UNER: A Unified Prediction Head for Named Entity Recognition in Visually-rich Documents
Yi Tu, Chong Zhang, Ya Guo, Huan Chen, Jinyang Tang, Huijia Zhu, Qi Zhang
The recognition of named entities in visually-rich documents (VrD-NER) plays a critical role in various real-world scenarios and applications. However, the research in VrD-NER faces three major challenges: complex document layouts, incorrect reading orders, and unsuitable task formulations. To address these challenges, we propose a query-aware entity extraction head, namely UNER, to collaborate with existing multi-modal document transformers to develop more robust VrD-NER models. The UNER head considers the VrD-NER task as a combination of sequence labeling and reading order prediction, effectively addressing the issues of discontinuous entities in documents. Experimental evaluations on diverse datasets demonstrate the effectiveness of UNER in improving entity extraction performance. Moreover, the UNER head enables a supervised pre-training stage on various VrD-NER datasets to enhance the document transformer backbones and exhibits substantial knowledge transfer from the pre-training stage to the fine-tuning stage. By incorporating universal layout understanding, a pre-trained UNER-based model demonstrates significant advantages in few-shot and cross-linguistic scenarios and exhibits zero-shot entity extraction abilities.
Read more8/13/2024