Mixed-Integer Optimal Control via Reinforcement Learning: A Case Study on Hybrid Electric Vehicle Energy Management
2305.01461
0
0
🏅
Abstract
Many optimal control problems require the simultaneous output of discrete and continuous control variables. These problems are usually formulated as mixed-integer optimal control (MIOC) problems, which are challenging to solve due to the complexity of the solution space. Numerical methods such as branch-and-bound are computationally expensive and undesirable for real-time control. This paper proposes a novel hybrid-action reinforcement learning (HARL) algorithm, twin delayed deep deterministic actor-Q (TD3AQ), for MIOC problems. TD3AQ combines the advantages of both actor-critic and Q-learning methods, and can handle the discrete and continuous action spaces simultaneously. The proposed algorithm is evaluated on a plug-in hybrid electric vehicle (PHEV) energy management problem, where real-time control of the discrete variables, clutch engagement/disengagement and gear shift, and continuous variable, engine torque, is essential to maximize fuel economy while satisfying driving constraints. Simulation outcomes demonstrate that TD3AQ achieves control results close to optimality when compared with dynamic programming (DP), with just 4.69% difference. Furthermore, it surpasses the performance of baseline reinforcement learning algorithms.
Create account to get full access
Overview
- This paper proposes a novel hybrid-action reinforcement learning (HARL) algorithm, called twin delayed deep deterministic actor-Q (TD3AQ), for solving mixed-integer optimal control (MIOC) problems.
- MIOC problems involve the simultaneous optimization of both discrete and continuous control variables, which are challenging to solve using traditional numerical methods.
- The authors evaluate the proposed TD3AQ algorithm on a plug-in hybrid electric vehicle (PHEV) energy management problem, where real-time control of discrete variables (clutch engagement/disengagement and gear shift) and a continuous variable (engine torque) is essential for maximizing fuel economy.
Plain English Explanation
Many real-world control problems, such as managing the energy system of a hybrid electric vehicle, require both discrete decisions (e.g., whether to engage or disengage the clutch) and continuous adjustments (e.g., how much engine torque to apply). These mixed-integer optimal control (MIOC) problems are difficult to solve because the combination of discrete and continuous variables creates a complex solution space.
The researchers in this paper developed a new reinforcement learning algorithm called TD3AQ that can handle both discrete and continuous control variables simultaneously. This hybrid-action reinforcement learning (HARL) approach combines the advantages of actor-critic and Q-learning methods to learn how to make the best decisions for controlling the energy system of a plug-in hybrid electric vehicle (PHEV).
The researchers tested the TD3AQ algorithm on a PHEV energy management problem, where it needed to control the engagement/disengagement of the clutch, the gear shifting, and the engine torque in real-time to maximize fuel efficiency while meeting driving requirements. The results show that TD3AQ performs very close to the optimal control strategy determined by a computationally expensive dynamic programming approach, but can be applied much more efficiently for real-time control.
Technical Explanation
The authors propose the TD3AQ algorithm, a novel hybrid-action reinforcement learning (HARL) approach for solving mixed-integer optimal control (MIOC) problems. TD3AQ combines the strengths of actor-critic and Q-learning methods to handle both discrete and continuous action spaces simultaneously.
The algorithm is evaluated on a plug-in hybrid electric vehicle (PHEV) energy management problem, where the goal is to optimize the real-time control of the discrete variables (clutch engagement/disengagement and gear shift) and the continuous variable (engine torque) to maximize fuel economy while satisfying driving constraints.
The performance of TD3AQ is compared to dynamic programming (DP), a computationally expensive but optimal control method. The simulation results show that TD3AQ achieves control results very close to the DP optimum, with just a 4.69% difference. Additionally, TD3AQ outperforms baseline reinforcement learning algorithms.
Critical Analysis
The authors acknowledge that while TD3AQ demonstrates promising results, it is still a learning-based approach and may not always converge to the global optimum, unlike DP. There could be cases where the algorithm gets stuck in local minima or fails to explore the entire solution space effectively.
Additionally, the evaluation is limited to a single PHEV energy management problem, and further testing on a wider range of mixed-integer optimal control problems would be necessary to validate the generalizability of the proposed algorithm.
It would also be interesting to see how TD3AQ performs in decentralized multi-agent reinforcement learning scenarios, where the control decisions are made by multiple autonomous entities rather than a centralized controller.
Conclusion
This paper presents a novel hybrid-action reinforcement learning (HARL) algorithm, TD3AQ, for solving mixed-integer optimal control (MIOC) problems. The algorithm's ability to handle both discrete and continuous control variables simultaneously makes it a promising approach for real-world control problems, as demonstrated by its performance on the PHEV energy management problem. While the results are encouraging, further research is needed to fully understand the algorithm's limitations and potential applications in decentralized multi-agent reinforcement learning scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Equivariant Deep Learning of Mixed-Integer Optimal Control Solutions for Vehicle Decision Making and Motion Planning
Rudolf Reiter, Rien Quirynen, Moritz Diehl, Stefano Di Cairano
0
0
Mixed-integer quadratic programs (MIQPs) are a versatile way of formulating vehicle decision making and motion planning problems, where the prediction model is a hybrid dynamical system that involves both discrete and continuous decision variables. However, even the most advanced MIQP solvers can hardly account for the challenging requirements of automotive embedded platforms. Thus, we use machine learning to simplify and hence speed up optimization. Our work builds on recent ideas for solving MIQPs in real-time by training a neural network to predict the optimal values of integer variables and solving the remaining problem by online quadratic programming. Specifically, we propose a recurrent permutation equivariant deep set that is particularly suited for imitating MIQPs that involve many obstacles, which is often the major source of computational burden in motion planning problems. Our framework comprises also a feasibility projector that corrects infeasible predictions of integer variables and considerably increases the likelihood of computing a collision-free trajectory. We evaluate the performance, safety and real-time feasibility of decision-making for autonomous driving using the proposed approach on realistic multi-lane traffic scenarios with interactive agents in SUMO simulations.
5/15/2024
🛠️
Data-driven modeling and supervisory control system optimization for plug-in hybrid electric vehicles
Hao Zhang, Nuo Lei, Boli Chen, Bingbing Li, Rulong Li, Zhi Wang
0
0
Learning-based intelligent energy management systems for plug-in hybrid electric vehicles (PHEVs) are crucial for achieving efficient energy utilization. However, their application faces system reliability challenges in the real world, which prevents widespread acceptance by original equipment manufacturers (OEMs). This paper begins by establishing a PHEV model based on physical and data-driven models, focusing on the high-fidelity training environment. It then proposes a real-vehicle application-oriented control framework, combining horizon-extended reinforcement learning (RL)-based energy management with the equivalent consumption minimization strategy (ECMS) to enhance practical applicability, and improves the flawed method of equivalent factor evaluation based on instantaneous driving cycle and powertrain states found in existing research. Finally, comprehensive simulation and hardware-in-the-loop validation are carried out which demonstrates the advantages of the proposed control framework in fuel economy over adaptive-ECMS and rule-based strategies. Compared to conventional RL architectures that directly control powertrain components, the proposed control method not only achieves similar optimality but also significantly enhances the disturbance resistance of the energy management system, providing an effective control framework for RL-based energy management strategies aimed at real-vehicle applications by OEMs.
6/14/2024
🏅
Reinforcement Learning for Intensity Control: An Application to Choice-Based Network Revenue Management
Huiling Meng, Ningyuan Chen, Xuefeng Gao
0
0
Intensity control is a type of continuous-time dynamic optimization problems with many important applications in Operations Research including queueing and revenue management. In this study, we adapt the reinforcement learning framework to intensity control using choice-based network revenue management as a case study, which is a classical problem in revenue management that features a large state space, a large action space and a continuous time horizon. We show that by utilizing the inherent discretization of the sample paths created by the jump points, a unique and defining feature of intensity control, one does not need to discretize the time horizon in advance, which was believed to be necessary because most reinforcement learning algorithms are designed for discrete-time problems. As a result, the computation can be facilitated and the discretization error is significantly reduced. We lay the theoretical foundation for the Monte Carlo and temporal difference learning algorithms for policy evaluation and develop policy gradient based actor critic algorithms for intensity control. Via a comprehensive numerical study, we demonstrate the benefit of our approach versus other state-of-the-art benchmarks.
6/11/2024
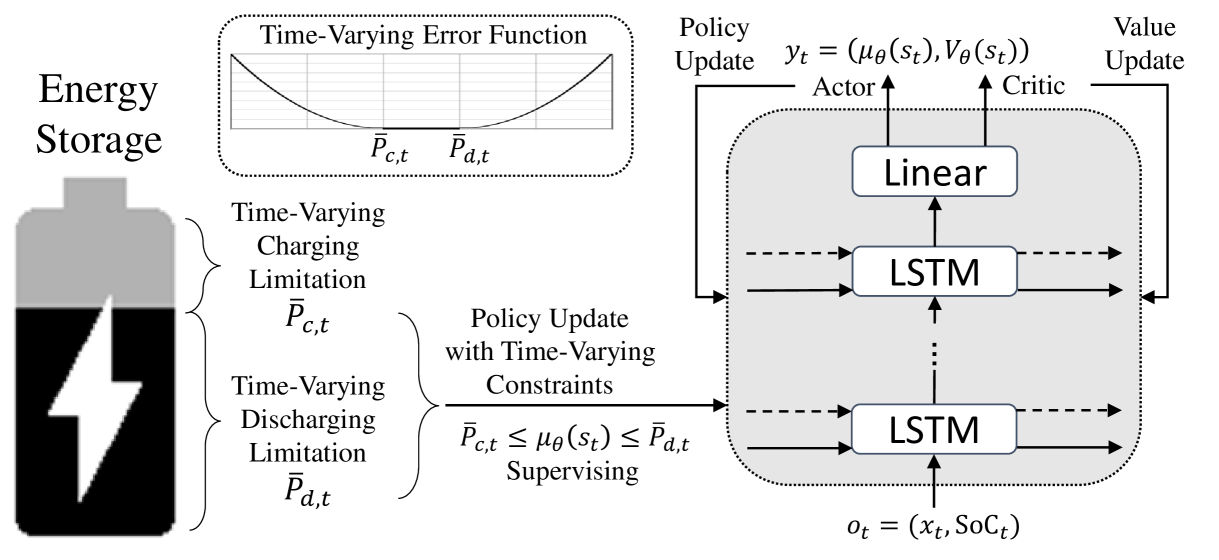
Time-Varying Constraint-Aware Reinforcement Learning for Energy Storage Control
Jaeik Jeong, Tai-Yeon Ku, Wan-Ki Park
0
0
Energy storage devices, such as batteries, thermal energy storages, and hydrogen systems, can help mitigate climate change by ensuring a more stable and sustainable power supply. To maximize the effectiveness of such energy storage, determining the appropriate charging and discharging amounts for each time period is crucial. Reinforcement learning is preferred over traditional optimization for the control of energy storage due to its ability to adapt to dynamic and complex environments. However, the continuous nature of charging and discharging levels in energy storage poses limitations for discrete reinforcement learning, and time-varying feasible charge-discharge range based on state of charge (SoC) variability also limits the conventional continuous reinforcement learning. In this paper, we propose a continuous reinforcement learning approach that takes into account the time-varying feasible charge-discharge range. An additional objective function was introduced for learning the feasible action range for each time period, supplementing the objectives of training the actor for policy learning and the critic for value learning. This actively promotes the utilization of energy storage by preventing them from getting stuck in suboptimal states, such as continuous full charging or discharging. This is achieved through the enforcement of the charging and discharging levels into the feasible action range. The experimental results demonstrated that the proposed method further maximized the effectiveness of energy storage by actively enhancing its utilization.
5/20/2024