Reinforcement Learning for Intensity Control: An Application to Choice-Based Network Revenue Management

0
🏅
Sign in to get full access
Overview
- This paper explores how reinforcement learning can be applied to intensity control, a type of continuous-time dynamic optimization problem with many important applications in operations research.
- The researchers use choice-based network revenue management as a case study, which is a classical problem in revenue management that features a large state space, a large action space, and a continuous time horizon.
- The key contribution is showing that by leveraging the inherent discretization of the sample paths created by the jump points in intensity control, one does not need to discretize the time horizon in advance, which was previously believed to be necessary.
Plain English Explanation
The paper discusses a way to use reinforcement learning to solve a type of optimization problem called "intensity control." Intensity control is relevant to many real-world situations, like managing queues or optimizing revenue.
The researchers focused on a specific problem in revenue management, called "choice-based network revenue management." This is a complex problem because there are many possible states the system can be in, many actions that can be taken, and the time horizon is continuous (rather than divided into discrete steps).
Most reinforcement learning algorithms are designed for discrete-time problems, so they would require discretizing the time horizon. However, the researchers found a way to avoid this by taking advantage of the inherent discretization in intensity control problems. This makes the computations easier and reduces errors caused by discretizing the time.
Technical Explanation
The paper adapts the reinforcement learning framework to intensity control problems, using choice-based network revenue management as a case study. Intensity control problems have a continuous time horizon, which was previously believed to require discretizing the time in advance before applying reinforcement learning algorithms, as most such algorithms are designed for discrete-time problems.
However, the researchers show that by leveraging the inherent discretization of the sample paths created by the jump points in intensity control, one does not need to discretize the time horizon. This significantly reduces the computation required and the discretization error.
The paper lays the theoretical foundation for using Monte Carlo and temporal difference learning algorithms for policy evaluation in intensity control problems. It also develops policy gradient-based actor-critic algorithms for these problems.
Through numerical experiments, the researchers demonstrate the benefits of their approach compared to other state-of-the-art methods for solving continuous control tasks and using reinforcement learning for intervention-assisted policy gradient.
Critical Analysis
The paper provides a compelling approach to applying reinforcement learning to intensity control problems, which have important real-world applications. By avoiding the need to discretize the time horizon, the researchers have made the computations more efficient and reduced a key source of error.
However, the paper does not address the potential limitations of using reinforcement learning for these types of problems. For example, the performance of the algorithms may depend heavily on the choice of reward function and state representation, which can be challenging to design for complex, real-world scenarios.
Additionally, the paper focuses on a specific case study in revenue management, and it's unclear how well the approach would generalize to other intensity control problems. Further research may be needed to understand the broader applicability of the techniques developed in this paper.
Conclusion
This paper presents an innovative approach to applying reinforcement learning to intensity control problems, a important class of optimization problems with many real-world applications. By leveraging the inherent discretization in intensity control, the researchers have developed more efficient algorithms that avoid the need for discretizing the time horizon, a key limitation of previous methods.
The findings of this paper have the potential to significantly impact how reinforcement learning is used to solve complex, continuous-time optimization problems in fields like operations research, queueing theory, and revenue management. However, further research is needed to understand the broader applicability of the techniques and their robustness to the challenges of real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Reinforcement Learning for Intensity Control: An Application to Choice-Based Network Revenue Management
Huiling Meng, Ningyuan Chen, Xuefeng Gao
Intensity control is a type of continuous-time dynamic optimization problems with many important applications in Operations Research including queueing and revenue management. In this study, we adapt the reinforcement learning framework to intensity control using choice-based network revenue management as a case study, which is a classical problem in revenue management that features a large state space, a large action space and a continuous time horizon. We show that by utilizing the inherent discretization of the sample paths created by the jump points, a unique and defining feature of intensity control, one does not need to discretize the time horizon in advance, which was believed to be necessary because most reinforcement learning algorithms are designed for discrete-time problems. As a result, the computation can be facilitated and the discretization error is significantly reduced. We lay the theoretical foundation for the Monte Carlo and temporal difference learning algorithms for policy evaluation and develop policy gradient based actor critic algorithms for intensity control. Via a comprehensive numerical study, we demonstrate the benefit of our approach versus other state-of-the-art benchmarks.
Read more6/11/2024
🏅
0
Mixed-Integer Optimal Control via Reinforcement Learning: A Case Study on Hybrid Electric Vehicle Energy Management
Jinming Xu, Nasser Lashgarian Azad, Yuan Lin
Many optimal control problems require the simultaneous output of discrete and continuous control variables. These problems are usually formulated as mixed-integer optimal control (MIOC) problems, which are challenging to solve due to the complexity of the solution space. Numerical methods such as branch-and-bound are computationally expensive and undesirable for real-time control. This paper proposes a novel hybrid-action reinforcement learning (HARL) algorithm, twin delayed deep deterministic actor-Q (TD3AQ), for MIOC problems. TD3AQ combines the advantages of both actor-critic and Q-learning methods, and can handle the discrete and continuous action spaces simultaneously. The proposed algorithm is evaluated on a plug-in hybrid electric vehicle (PHEV) energy management problem, where real-time control of the discrete variables, clutch engagement/disengagement and gear shift, and continuous variable, engine torque, is essential to maximize fuel economy while satisfying driving constraints. Simulation outcomes demonstrate that TD3AQ achieves control results close to optimality when compared with dynamic programming (DP), with just 4.69% difference. Furthermore, it surpasses the performance of baseline reinforcement learning algorithms.
Read more6/3/2024
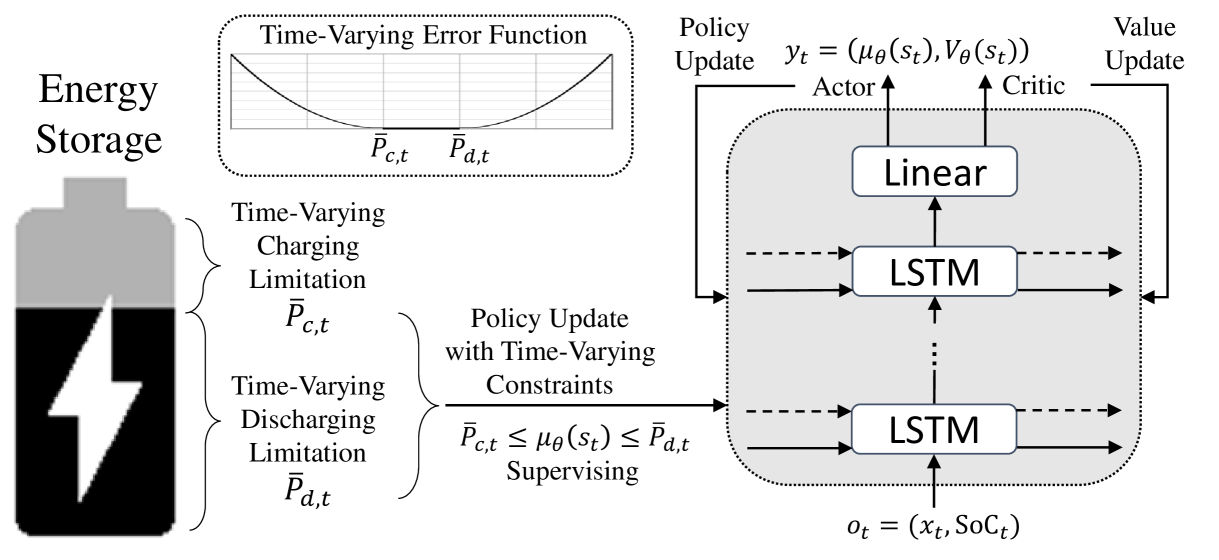
0
Time-Varying Constraint-Aware Reinforcement Learning for Energy Storage Control
Jaeik Jeong, Tai-Yeon Ku, Wan-Ki Park
Energy storage devices, such as batteries, thermal energy storages, and hydrogen systems, can help mitigate climate change by ensuring a more stable and sustainable power supply. To maximize the effectiveness of such energy storage, determining the appropriate charging and discharging amounts for each time period is crucial. Reinforcement learning is preferred over traditional optimization for the control of energy storage due to its ability to adapt to dynamic and complex environments. However, the continuous nature of charging and discharging levels in energy storage poses limitations for discrete reinforcement learning, and time-varying feasible charge-discharge range based on state of charge (SoC) variability also limits the conventional continuous reinforcement learning. In this paper, we propose a continuous reinforcement learning approach that takes into account the time-varying feasible charge-discharge range. An additional objective function was introduced for learning the feasible action range for each time period, supplementing the objectives of training the actor for policy learning and the critic for value learning. This actively promotes the utilization of energy storage by preventing them from getting stuck in suboptimal states, such as continuous full charging or discharging. This is achieved through the enforcement of the charging and discharging levels into the feasible action range. The experimental results demonstrated that the proposed method further maximized the effectiveness of energy storage by actively enhancing its utilization.
Read more5/20/2024

0
Growing Q-Networks: Solving Continuous Control Tasks with Adaptive Control Resolution
Tim Seyde, Peter Werner, Wilko Schwarting, Markus Wulfmeier, Daniela Rus
Recent reinforcement learning approaches have shown surprisingly strong capabilities of bang-bang policies for solving continuous control benchmarks. The underlying coarse action space discretizations often yield favourable exploration characteristics while final performance does not visibly suffer in the absence of action penalization in line with optimal control theory. In robotics applications, smooth control signals are commonly preferred to reduce system wear and energy efficiency, but action costs can be detrimental to exploration during early training. In this work, we aim to bridge this performance gap by growing discrete action spaces from coarse to fine control resolution, taking advantage of recent results in decoupled Q-learning to scale our approach to high-dimensional action spaces up to dim(A) = 38. Our work indicates that an adaptive control resolution in combination with value decomposition yields simple critic-only algorithms that yield surprisingly strong performance on continuous control tasks.
Read more4/8/2024