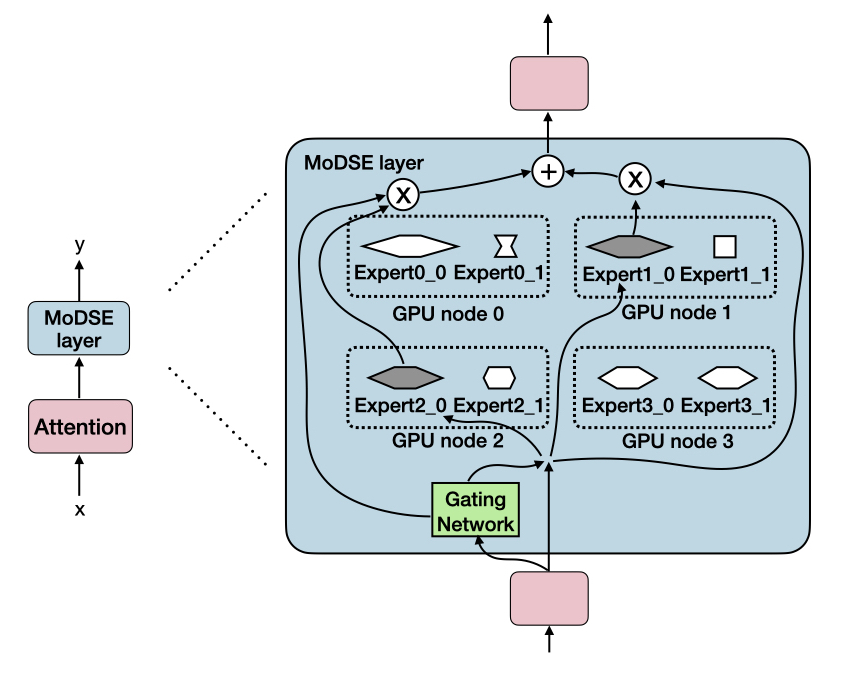
Mixture of Diverse Size Experts

0
Sign in to get full access
Overview
- The paper introduces a new deep learning architecture called Mixture of Diverse Size Experts (MoDSE) for large-scale machine learning tasks.
- MoDSE combines multiple expert models of varying sizes to efficiently handle the diverse complexity of different input examples.
- The experts specialize in different types of inputs, allowing the model to dynamically allocate computational resources based on the complexity of the problem.
Plain English Explanation
The researchers developed a new type of deep learning model called Mixture of Diverse Size Experts (MoDSE) that is designed to handle a wide range of machine learning tasks efficiently. The key idea behind MoDSE is to have multiple "expert" models, each of which is specialized in handling a certain type of input.
For example, some inputs may be simple and straightforward, while others may be more complex and require more computational power to process. With MoDSE, the model can dynamically allocate its resources by selecting the most appropriate expert for each input, rather than using a one-size-fits-all approach.
This allows the model to be more efficient and effective, as it can focus its computational power where it's needed the most. The experts in MoDSE can also vary in size, with smaller experts handling simpler inputs and larger experts tackling more complex ones.
By using this mixture of diverse experts, the MoDSE model can adapt to a wide range of machine learning problems, from image recognition to natural language processing, without sacrificing performance or efficiency.
Technical Explanation
The core idea behind the Mixture of Diverse Size Experts (MoDSE) architecture is to combine multiple expert models of varying sizes to efficiently handle the diverse complexity of different input examples.
The MoDSE architecture consists of a gating network that dynamically selects the most appropriate expert model for each input, and a set of expert models with a range of sizes and capacities. The gating network learns to route each input to the expert that is best suited to process it, based on the input's complexity.
This approach allows the MoDSE model to allocate computational resources more effectively, as the smaller experts can quickly handle simpler inputs, while the larger experts focus on the more complex examples. The authors demonstrate the effectiveness of MoDSE on a variety of large-scale machine learning tasks, including image recognition and natural language processing.
The mixture of experts approach has been studied extensively in the literature, and the MoDSE architecture builds upon these previous works by incorporating experts of diverse sizes. This allows the model to better capture the heterogeneous nature of real-world data, as different inputs may require different levels of model complexity to process effectively.
Critical Analysis
The MoDSE paper presents a promising approach to improving the efficiency and effectiveness of deep learning models, but there are a few potential limitations and areas for further research:
-
Complexity of the Gating Network: The performance of the MoDSE model relies heavily on the gating network's ability to accurately route inputs to the appropriate expert. As the number of experts grows, the complexity of the gating network may increase, potentially introducing additional computational overhead.
-
Specialization and Generalization: While the diverse experts in MoDSE can specialize in different types of inputs, this specialization may come at the cost of reduced generalization ability. Further research is needed to understand the trade-offs between specialization and generalization in the MoDSE framework.
-
Interpretability and Explainability: The authors do not address the interpretability or explainability of the MoDSE model, which could be an important consideration for certain applications, such as in high-stakes decision-making scenarios.
-
Dynamic Adaptation: The current MoDSE architecture requires the gating network to be trained along with the expert models. It would be interesting to explore approaches that allow the gating network to dynamically adapt to changing input distributions without the need for retraining the entire model.
Conclusion
The Mixture of Diverse Size Experts (MoDSE) architecture presents a novel and promising approach to improving the efficiency and effectiveness of deep learning models. By combining multiple expert models of varying sizes, MoDSE can dynamically allocate computational resources based on the complexity of the input, leading to better performance on a wide range of machine learning tasks.
While the paper demonstrates the effectiveness of MoDSE, there are still some areas for further research, such as the complexity of the gating network, the trade-offs between specialization and generalization, and the interpretability and explainability of the model. Nonetheless, the MoDSE framework represents an important step forward in the development of more efficient and adaptive deep learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mixture of Diverse Size Experts
Manxi Sun, Wei Liu, Jian Luan, Pengzhi Gao, Bin Wang
The Sparsely-Activated Mixture-of-Experts (MoE) has gained increasing popularity for scaling up large language models (LLMs) without exploding computational costs. Despite its success, the current design faces a challenge where all experts have the same size, limiting the ability of tokens to choose the experts with the most appropriate size for generating the next token. In this paper, we propose the Mixture of Diverse Size Experts (MoDSE), a new MoE architecture with layers designed to have experts of different sizes. Our analysis of difficult token generation tasks shows that experts of various sizes achieve better predictions, and the routing path of the experts tends to be stable after a training period. However, having experts of diverse sizes can lead to uneven workload distribution. To tackle this limitation, we introduce an expert-pair allocation strategy to evenly distribute the workload across multiple GPUs. Comprehensive evaluations across multiple benchmarks demonstrate the effectiveness of MoDSE, as it outperforms existing MoEs by allocating the parameter budget to experts adaptively while maintaining the same total parameter size and the number of experts.
Read more9/20/2024

0
A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
Read more6/27/2024
0
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
Read more4/4/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024