Mixture of Experts in a Mixture of RL settings
2406.18420
0
0

Abstract
Mixtures of Experts (MoEs) have gained prominence in (self-)supervised learning due to their enhanced inference efficiency, adaptability to distributed training, and modularity. Previous research has illustrated that MoEs can significantly boost Deep Reinforcement Learning (DRL) performance by expanding the network's parameter count while reducing dormant neurons, thereby enhancing the model's learning capacity and ability to deal with non-stationarity. In this work, we shed more light on MoEs' ability to deal with non-stationarity and investigate MoEs in DRL settings with amplified non-stationarity via multi-task training, providing further evidence that MoEs improve learning capacity. In contrast to previous work, our multi-task results allow us to better understand the underlying causes for the beneficial effect of MoE in DRL training, the impact of the various MoE components, and insights into how best to incorporate them in actor-critic-based DRL networks. Finally, we also confirm results from previous work.
Create account to get full access
Overview
- This paper proposes a novel approach called "Mixture of Experts in a Mixture of RL Settings" (MEMORS) that aims to address the challenge of learning in diverse reinforcement learning (RL) environments.
- MEMORS combines the principles of Mixture of Experts and Hierarchical RL to create a flexible and adaptable system.
- The key idea is to use a mixture of specialized sub-policies (experts) that can be selectively activated based on the current state of the environment, allowing the agent to learn and perform well across a range of diverse RL tasks.
Plain English Explanation
The paper describes a new approach to reinforcement learning (RL) that aims to help AI agents perform well in a variety of different environments or tasks. The core idea is to have a "mixture" of specialized sub-policies or "experts" that can be selectively activated based on the current situation.
Imagine you're training an AI agent to play different video games. Each game might have its own unique challenges, such as fast-paced action, puzzle-solving, or resource management. A traditional RL system would try to learn a single, general policy that performs well across all these games, but this can be difficult and lead to suboptimal performance.
Instead, the MEMORS approach breaks things down into a collection of specialized "experts" - each one focused on a particular aspect of gameplay. When the agent encounters a new game or situation, it can select the most appropriate experts to handle the current task, rather than relying on a one-size-fits-all policy.
This allows the agent to be more flexible and adaptive, drawing on the strengths of its specialized sub-policies as needed. It's like having a toolbox full of different tools, and choosing the right one for the job at hand, rather than trying to use a single, general-purpose tool for everything.
By combining this "mixture of experts" concept with hierarchical RL techniques, the researchers aim to create a powerful and versatile system that can learn and perform well across a wide range of reinforcement learning scenarios.
Technical Explanation
The MEMORS framework consists of two key components:
-
Mixture of Experts (MoE): The agent is composed of a collection of specialized sub-policies or "experts", each of which is trained to handle a particular aspect of the task or environment. A gating network is used to dynamically select the most appropriate experts for the current situation.
-
Hierarchical RL: The agent uses a two-level hierarchy, with a high-level policy that selects which experts to activate, and low-level experts that handle the execution of specific skills or behaviors.
During training, the agent learns to optimize both the high-level policy (for expert selection) and the low-level experts (for task completion) simultaneously. This allows the system to develop a diverse repertoire of skills and dynamically combine them as needed.
The researchers evaluate MEMORS on a range of challenging RL benchmarks, including continuous control tasks and multi-task learning environments. The results demonstrate that MEMORS can outperform traditional RL approaches, particularly in settings with diverse task distributions or rapidly changing environments.
Critical Analysis
The MEMORS framework represents a promising step forward in addressing the challenge of learning and performing well in complex, heterogeneous RL settings. By leveraging the principles of Mixture of Experts and Hierarchical RL, the system can develop a diverse set of skills and dynamically combine them as needed.
However, the paper does not address certain limitations and potential issues with the approach:
- The training process for MEMORS may be computationally intensive, as it requires learning both the high-level policy and the low-level experts simultaneously.
- The performance of the system may be sensitive to the specific architecture and hyperparameters of the MoE and hierarchical RL components, which could make it challenging to apply in practice.
- The paper does not explore the interpretability or explainability of the learned experts and their selection mechanisms, which could be important for understanding and debugging the system's behavior.
Further research is needed to address these concerns and explore the broader applicability and scalability of the MEMORS approach, particularly in real-world RL scenarios with even greater task diversity and complexity.
Conclusion
The MEMORS framework represents a significant advancement in the field of reinforcement learning, tackling the challenge of learning and performing well in diverse RL environments. By combining the principles of Mixture of Experts and Hierarchical RL, the system can develop a diverse repertoire of skills and dynamically activate the most appropriate ones for the current situation.
The results presented in the paper demonstrate the potential of this approach to outperform traditional RL methods, particularly in settings with rapidly changing or heterogeneous tasks. While the framework has some limitations that warrant further exploration, the core ideas of MEMORS could have far-reaching implications for the development of more flexible, adaptable, and capable reinforcement learning agents.
As the field of AI continues to advance, approaches like MEMORS may play a crucial role in enabling agents to navigate the complexity and diversity of real-world environments, paving the way for more effective and impactful applications of reinforcement learning in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Theory on Mixture-of-Experts in Continual Learning
Hongbo Li, Sen Lin, Lingjie Duan, Yingbin Liang, Ness B. Shroff
0
0
Continual learning (CL) has garnered significant attention because of its ability to adapt to new tasks that arrive over time. Catastrophic forgetting (of old tasks) has been identified as a major issue in CL, as the model adapts to new tasks. The Mixture-of-Experts (MoE) model has recently been shown to effectively mitigate catastrophic forgetting in CL, by employing a gating network to sparsify and distribute diverse tasks among multiple experts. However, there is a lack of theoretical analysis of MoE and its impact on the learning performance in CL. This paper provides the first theoretical results to characterize the impact of MoE in CL via the lens of overparameterized linear regression tasks. We establish the benefit of MoE over a single expert by proving that the MoE model can diversify its experts to specialize in different tasks, while its router learns to select the right expert for each task and balance the loads across all experts. Our study further suggests an intriguing fact that the MoE in CL needs to terminate the update of the gating network after sufficient training rounds to attain system convergence, which is not needed in the existing MoE studies that do not consider the continual task arrival. Furthermore, we provide explicit expressions for the expected forgetting and overall generalization error to characterize the benefit of MoE in the learning performance in CL. Interestingly, adding more experts requires additional rounds before convergence, which may not enhance the learning performance. Finally, we conduct experiments on both synthetic and real datasets to extend these insights from linear models to deep neural networks (DNNs), which also shed light on the practical algorithm design for MoE in CL.
6/26/2024
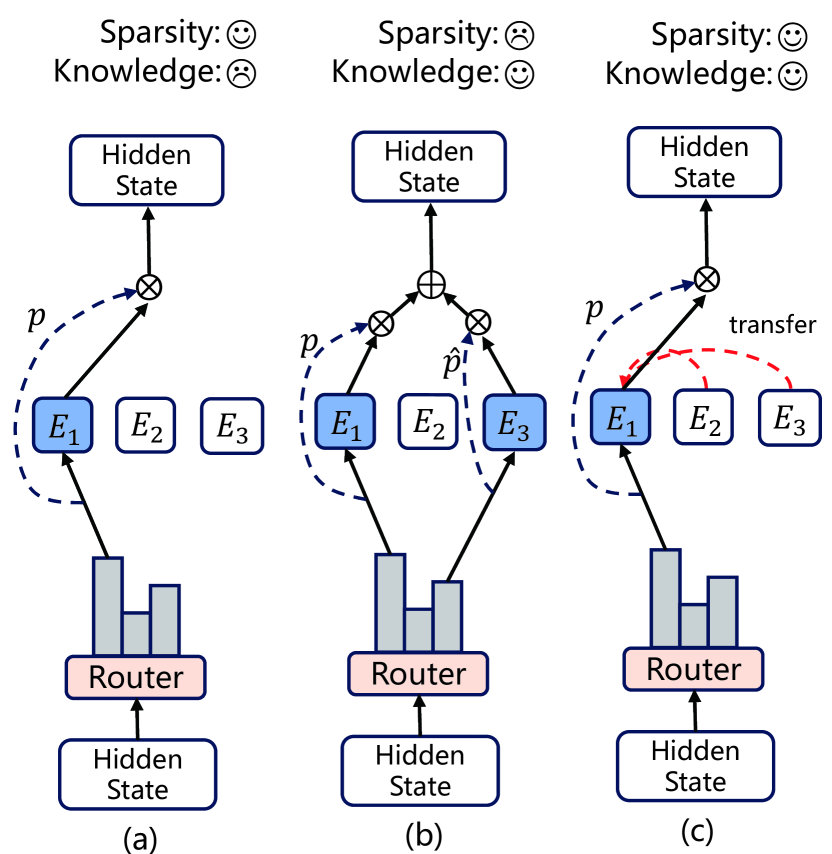
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
0
0
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
5/22/2024

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024

Mixtures of Experts Unlock Parameter Scaling for Deep RL
Johan Obando-Ceron, Ghada Sokar, Timon Willi, Clare Lyle, Jesse Farebrother, Jakob Foerster, Gintare Karolina Dziugaite, Doina Precup, Pablo Samuel Castro
0
0
The recent rapid progress in (self) supervised learning models is in large part predicted by empirical scaling laws: a model's performance scales proportionally to its size. Analogous scaling laws remain elusive for reinforcement learning domains, however, where increasing the parameter count of a model often hurts its final performance. In this paper, we demonstrate that incorporating Mixture-of-Expert (MoE) modules, and in particular Soft MoEs (Puigcerver et al., 2023), into value-based networks results in more parameter-scalable models, evidenced by substantial performance increases across a variety of training regimes and model sizes. This work thus provides strong empirical evidence towards developing scaling laws for reinforcement learning.
6/27/2024