Theory on Mixture-of-Experts in Continual Learning
2406.16437
0
0

Abstract
Continual learning (CL) has garnered significant attention because of its ability to adapt to new tasks that arrive over time. Catastrophic forgetting (of old tasks) has been identified as a major issue in CL, as the model adapts to new tasks. The Mixture-of-Experts (MoE) model has recently been shown to effectively mitigate catastrophic forgetting in CL, by employing a gating network to sparsify and distribute diverse tasks among multiple experts. However, there is a lack of theoretical analysis of MoE and its impact on the learning performance in CL. This paper provides the first theoretical results to characterize the impact of MoE in CL via the lens of overparameterized linear regression tasks. We establish the benefit of MoE over a single expert by proving that the MoE model can diversify its experts to specialize in different tasks, while its router learns to select the right expert for each task and balance the loads across all experts. Our study further suggests an intriguing fact that the MoE in CL needs to terminate the update of the gating network after sufficient training rounds to attain system convergence, which is not needed in the existing MoE studies that do not consider the continual task arrival. Furthermore, we provide explicit expressions for the expected forgetting and overall generalization error to characterize the benefit of MoE in the learning performance in CL. Interestingly, adding more experts requires additional rounds before convergence, which may not enhance the learning performance. Finally, we conduct experiments on both synthetic and real datasets to extend these insights from linear models to deep neural networks (DNNs), which also shed light on the practical algorithm design for MoE in CL.
Create account to get full access
Overview
- This paper presents a theory on using a Mixture-of-Experts (MoE) model for continual learning tasks.
- Continual learning refers to the ability of a model to learn new tasks or data while retaining knowledge from previous tasks, without catastrophic forgetting.
- The proposed MoE-based approach aims to address the challenges of continual learning by leveraging a modular architecture with specialized sub-models (experts) that can be selectively updated.
Plain English Explanation
The paper explores a way to build AI models that can continuously learn new information without forgetting what they've learned before. This is an important challenge in the field of machine learning, known as "continual learning."
The key idea is to use a Mixture-of-Experts (MoE) model, which is like having a team of specialized sub-models (called "experts") that work together. When the model needs to learn a new task, it can selectively update just the relevant experts, rather than the entire model. This helps the model retain its knowledge from previous tasks while incorporating new information.
The paper provides a theoretical framework for how this MoE-based continual learning approach could work. The intuition is that by having a modular architecture with specialized experts, the model can more efficiently adapt to new tasks without catastrophically forgetting what it has learned before.
This research could have important implications for building AI systems that can continually expand their capabilities over time, like an AI model that can learn new languages or skills without losing their previous knowledge. It's an important step towards more flexible and adaptable AI.
Technical Explanation
The paper introduces a theoretical framework for using a Mixture-of-Experts (MoE) model architecture to address the challenges of continual learning. In a MoE model, there are multiple specialized "expert" sub-models that work together, with a gating network that decides which experts to use for a given input.
The key insight is that in a continual learning setting, the MoE structure allows the model to selectively update only the relevant experts when learning a new task, rather than having to retrain the entire model. This helps mitigate catastrophic forgetting, where a model forgets previously learned knowledge when trained on new data.
The paper provides a detailed mathematical formulation of the MoE continual learning problem and outlines potential solutions. It draws connections to related work, such as low-rank MoE models and hyper-network MoE approaches.
The authors also discuss practical considerations, such as efficient MoE implementations and potential connections to large language model architectures like LLaMA-MoE.
Critical Analysis
The paper provides a solid theoretical foundation for using MoE models in continual learning, but does not present any empirical results or experiments. As such, the true efficacy of the proposed approach remains to be validated through future work.
Some potential limitations or areas for further research include:
- Determining the optimal number and specialization of experts for different types of continual learning tasks
- Investigating how to efficiently train and update the gating network to effectively route inputs to the appropriate experts
- Exploring ways to transfer knowledge between experts to further mitigate forgetting
- Analyzing the scalability and computational efficiency of MoE continual learning models, especially for large-scale problems
Overall, the paper offers a promising theoretical framework, but more practical experimentation and evaluation will be needed to assess the real-world benefits and drawbacks of the MoE continual learning approach.
Conclusion
This paper presents a theoretical foundation for using a Mixture-of-Experts (MoE) model architecture to address the challenges of continual learning. The key idea is that the modular MoE structure allows the model to selectively update only the relevant expert sub-models when learning new tasks, helping to prevent catastrophic forgetting of previous knowledge.
While the paper does not provide empirical results, it lays the groundwork for future research in this area. Developing effective MoE-based continual learning systems could have significant implications for building AI models that can continuously expand their capabilities over time, like learning new languages or skills without forgetting their previous knowledge. This is an important step towards more flexible and adaptable artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Mixture of Experts in a Mixture of RL settings
Timon Willi, Johan Obando-Ceron, Jakob Foerster, Karolina Dziugaite, Pablo Samuel Castro
0
0
Mixtures of Experts (MoEs) have gained prominence in (self-)supervised learning due to their enhanced inference efficiency, adaptability to distributed training, and modularity. Previous research has illustrated that MoEs can significantly boost Deep Reinforcement Learning (DRL) performance by expanding the network's parameter count while reducing dormant neurons, thereby enhancing the model's learning capacity and ability to deal with non-stationarity. In this work, we shed more light on MoEs' ability to deal with non-stationarity and investigate MoEs in DRL settings with amplified non-stationarity via multi-task training, providing further evidence that MoEs improve learning capacity. In contrast to previous work, our multi-task results allow us to better understand the underlying causes for the beneficial effect of MoE in DRL training, the impact of the various MoE components, and insights into how best to incorporate them in actor-critic-based DRL networks. Finally, we also confirm results from previous work.
6/27/2024

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024

Low-Rank Mixture-of-Experts for Continual Medical Image Segmentation
Qian Chen, Lei Zhu, Hangzhou He, Xinliang Zhang, Shuang Zeng, Qiushi Ren, Yanye Lu
0
0
The primary goal of continual learning (CL) task in medical image segmentation field is to solve the catastrophic forgetting problem, where the model totally forgets previously learned features when it is extended to new categories (class-level) or tasks (task-level). Due to the privacy protection, the historical data labels are inaccessible. Prevalent continual learning methods primarily focus on generating pseudo-labels for old datasets to force the model to memorize the learned features. However, the incorrect pseudo-labels may corrupt the learned feature and lead to a new problem that the better the model is trained on the old task, the poorer the model performs on the new tasks. To avoid this problem, we propose a network by introducing the data-specific Mixture of Experts (MoE) structure to handle the new tasks or categories, ensuring that the network parameters of previous tasks are unaffected or only minimally impacted. To further overcome the tremendous memory costs caused by introducing additional structures, we propose a Low-Rank strategy which significantly reduces memory cost. We validate our method on both class-level and task-level continual learning challenges. Extensive experiments on multiple datasets show our model outperforms all other methods.
6/21/2024
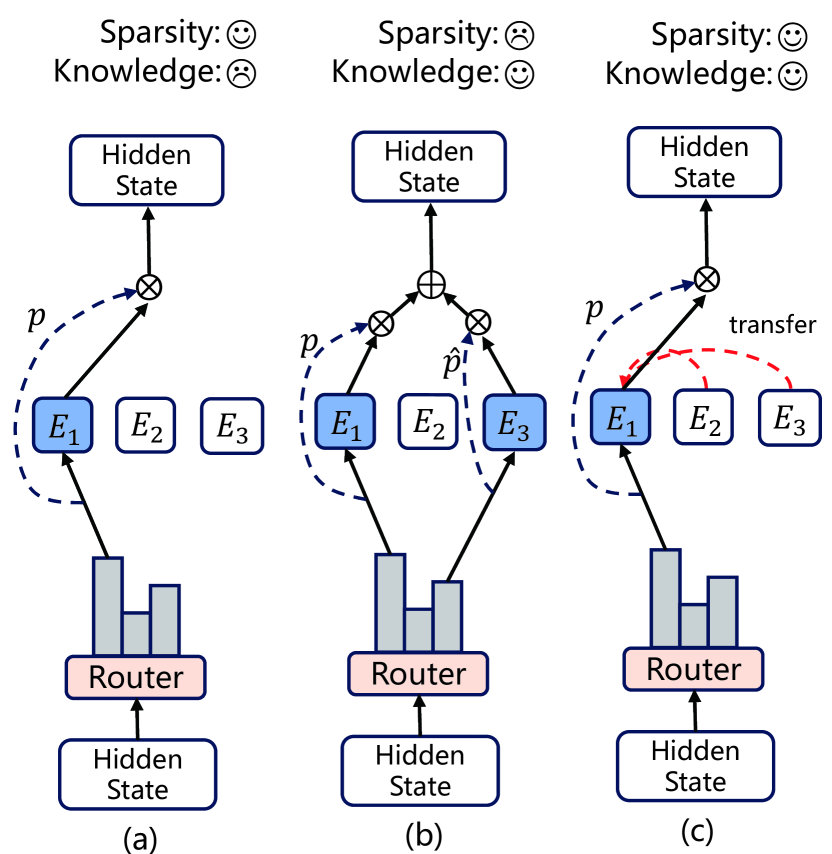
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
0
0
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
5/22/2024