Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
2404.04883
0
0

Abstract
Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a "Mixture of Low-rank Experts" (MoLE) model for detecting AI-generated images
- MoLE leverages a mixture of specialized experts, each focused on a different type of AI-generated image, to improve detection performance
- The model is designed to be transferable, allowing it to detect images from a wide range of AI generation models
Plain English Explanation
The paper describes a new way to detect images that have been created by artificial intelligence (AI) models, rather than captured by a camera. The researchers developed a system called "Mixture of Low-rank Experts" (MoLE) that uses a combination of different expert models, each trained to recognize a particular type of AI-generated image.
The key idea is that different AI generation models (like VITAMIN, Diverse-Tailored, or CLIP-based video highlight detection) can produce images with distinct visual characteristics. By having a set of specialized experts, each focused on a particular style or artifact, the MoLE model can more accurately identify a wide range of AI-generated content.
The researchers designed MoLE to be "transferable", meaning it can be applied to detect AI-generated images from models it wasn't specifically trained on. This is important because new AI image generation models are constantly being developed, and a detection system needs to be able to adapt to these emerging threats.
Technical Explanation
The core of the MoLE model is a mixture of "low-rank experts", where each expert is a neural network trained to detect a specific type of AI-generated image. The experts are combined using a gating network that dynamically assigns input images to the most appropriate expert(s).
The low-rank nature of the experts allows the model to be compact and efficient, while still maintaining strong detection performance. The authors also introduce a novel training procedure that encourages the experts to specialize in different types of AI-generated content, further improving the model's ability to generalize.
Experiments show that MoLE outperforms previous state-of-the-art AI-generated image detectors on a range of benchmarks, including the ability to detect images from unseen generation models (Model-Agnostic Origin Attribution). The authors also demonstrate the transferability of MoLE by showing it can be fine-tuned on new datasets with minimal additional training.
Critical Analysis
The paper presents a compelling approach to the challenging problem of AI-generated image detection. The key strength of MoLE is its ability to leverage specialized experts to cover a diverse range of AI generation styles, while maintaining a compact and efficient model architecture.
However, the authors acknowledge that MoLE may struggle to detect images from completely novel AI generation paradigms that exhibit very different visual characteristics. Additionally, the reliance on a gating network to dynamically route images to experts could potentially introduce some computational overhead, which may limit the model's real-world deployment in certain scenarios.
Further research is needed to explore the robustness of MoLE to adversarial attacks, where attackers may try to deliberately craft images that circumvent the detection system. The authors also note that their evaluation was primarily focused on static images, and extending the approach to video or other media formats may present additional challenges.
Conclusion
The "Mixture of Low-rank Experts" model proposed in this paper represents a significant advance in the field of AI-generated image detection. By combining specialized experts, the model can effectively identify a wide range of AI-generated content, while maintaining a compact and transferable architecture.
As AI image generation technologies continue to evolve, systems like MoLE will be essential for maintaining the integrity of visual media and combating the spread of synthetic content. The authors have made an important contribution to this critical area of research, and their work lays the groundwork for future advancements in the detection and mitigation of AI-generated imagery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
0
0
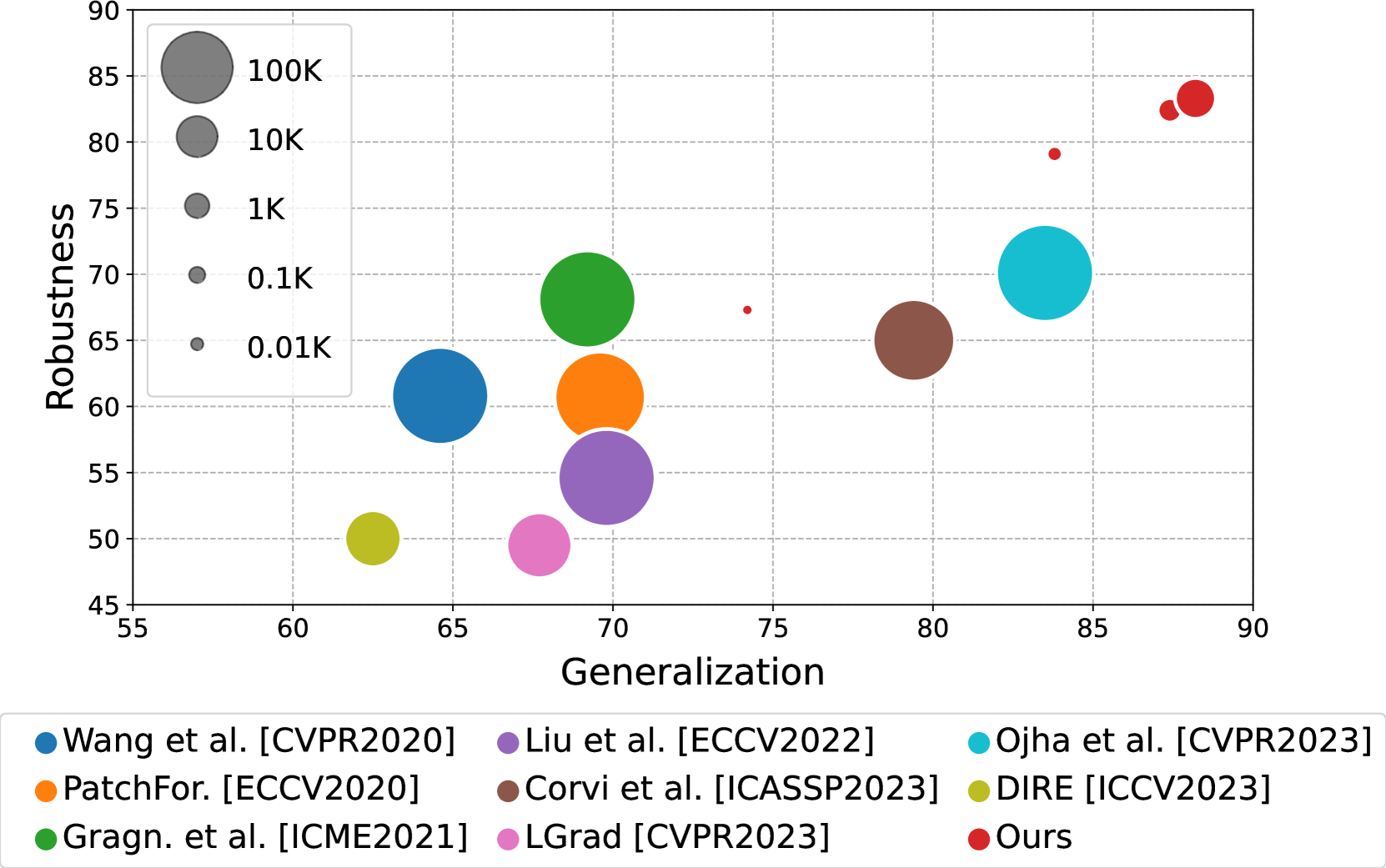
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
4/30/2024
Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images
Santosh, Li Lin, Irene Amerini, Xin Wang, Shu Hu
0
0
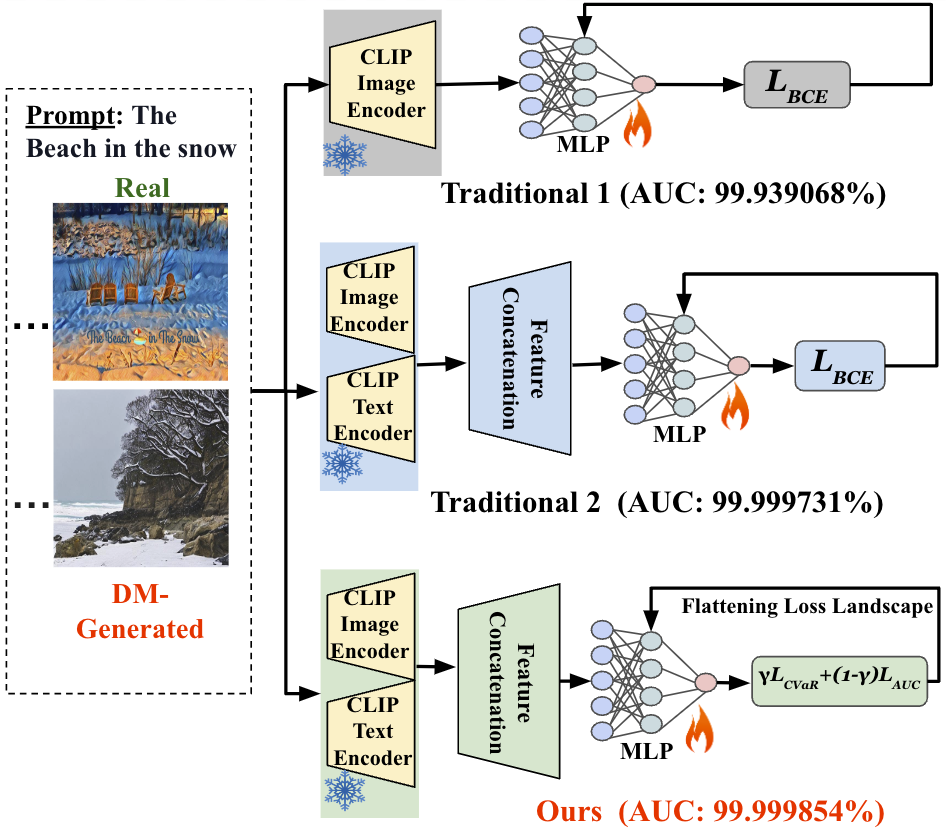
Diffusion models (DMs) have revolutionized image generation, producing high-quality images with applications spanning various fields. However, their ability to create hyper-realistic images poses significant challenges in distinguishing between real and synthetic content, raising concerns about digital authenticity and potential misuse in creating deepfakes. This work introduces a robust detection framework that integrates image and text features extracted by CLIP model with a Multilayer Perceptron (MLP) classifier. We propose a novel loss that can improve the detector's robustness and handle imbalanced datasets. Additionally, we flatten the loss landscape during the model training to improve the detector's generalization capabilities. The effectiveness of our method, which outperforms traditional detection techniques, is demonstrated through extensive experiments, underscoring its potential to set a new state-of-the-art approach in DM-generated image detection. The code is available at https://github.com/Purdue-M2/Robust_DM_Generated_Image_Detection.
4/22/2024
📶
Detecting AI-Generated Images via CLIP
A. G. Moskowitz, T. Gaona, J. Peterson
0
0
As AI-generated image (AIGI) methods become more powerful and accessible, it has become a critical task to determine if an image is real or AI-generated. Because AIGI lack the signatures of photographs and have their own unique patterns, new models are needed to determine if an image is AI-generated. In this paper, we investigate the ability of the Contrastive Language-Image Pre-training (CLIP) architecture, pre-trained on massive internet-scale data sets, to perform this differentiation. We fine-tune CLIP on real images and AIGI from several generative models, enabling CLIP to determine if an image is AI-generated and, if so, determine what generation method was used to create it. We show that the fine-tuned CLIP architecture is able to differentiate AIGI as well or better than models whose architecture is specifically designed to detect AIGI. Our method will significantly increase access to AIGI-detecting tools and reduce the negative effects of AIGI on society, as our CLIP fine-tuning procedures require no architecture changes from publicly available model repositories and consume significantly less GPU resources than other AIGI detection models.
4/16/2024
ViTamin: Designing Scalable Vision Models in the Vision-Language Era
Jieneng Chen, Qihang Yu, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
0
0
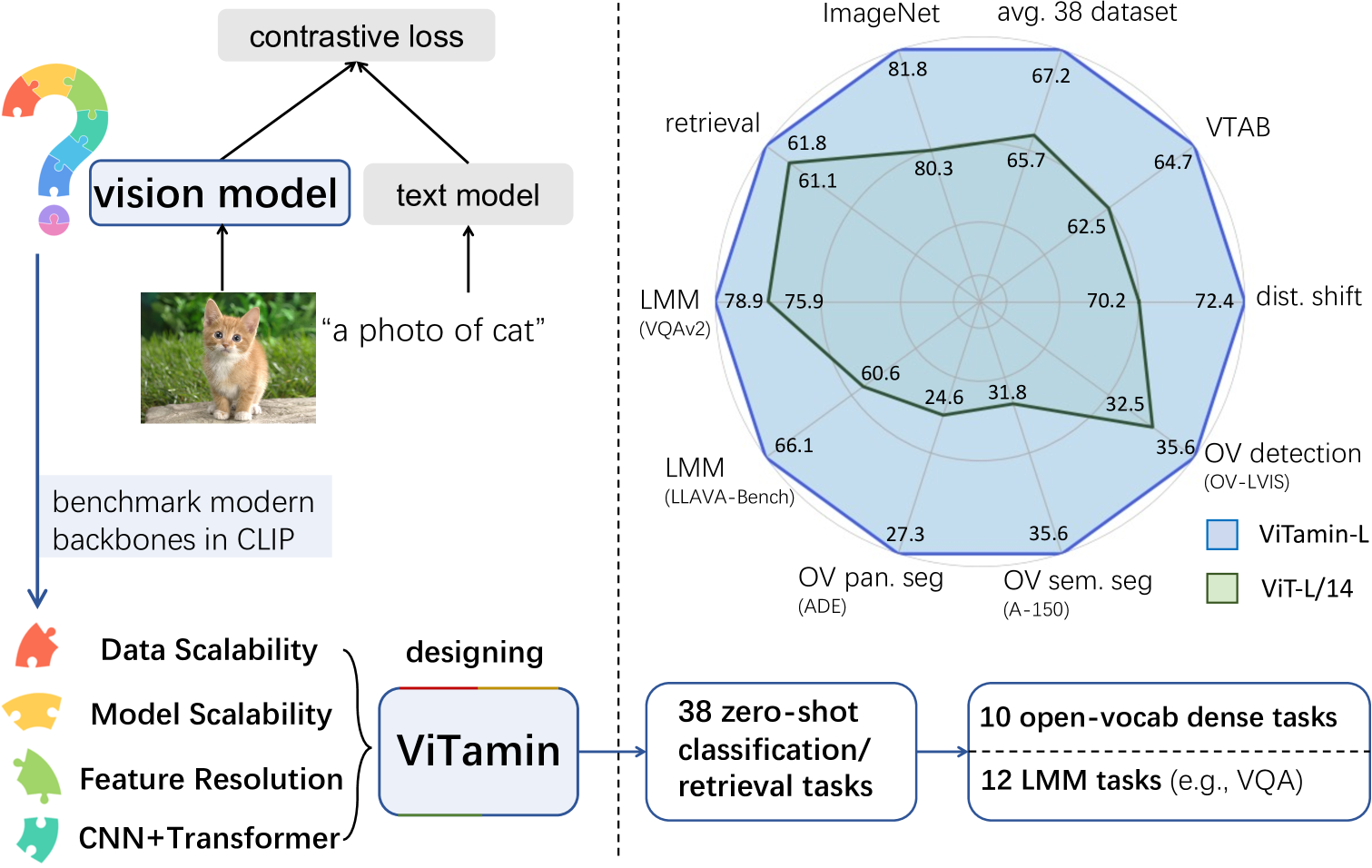
Recent breakthroughs in vision-language models (VLMs) start a new page in the vision community. The VLMs provide stronger and more generalizable feature embeddings compared to those from ImageNet-pretrained models, thanks to the training on the large-scale Internet image-text pairs. However, despite the amazing achievement from the VLMs, vanilla Vision Transformers (ViTs) remain the default choice for the image encoder. Although pure transformer proves its effectiveness in the text encoding area, it remains questionable whether it is also the case for image encoding, especially considering that various types of networks are proposed on the ImageNet benchmark, which, unfortunately, are rarely studied in VLMs. Due to small data/model scale, the original conclusions of model design on ImageNet can be limited and biased. In this paper, we aim at building an evaluation protocol of vision models in the vision-language era under the contrastive language-image pretraining (CLIP) framework. We provide a comprehensive way to benchmark different vision models, covering their zero-shot performance and scalability in both model and training data sizes. To this end, we introduce ViTamin, a new vision models tailored for VLMs. ViTamin-L significantly outperforms ViT-L by 2.0% ImageNet zero-shot accuracy, when using the same publicly available DataComp-1B dataset and the same OpenCLIP training scheme. ViTamin-L presents promising results on 60 diverse benchmarks, including classification, retrieval, open-vocabulary detection and segmentation, and large multi-modal models. When further scaling up the model size, our ViTamin-XL with only 436M parameters attains 82.9% ImageNet zero-shot accuracy, surpassing 82.0% achieved by EVA-E that has ten times more parameters (4.4B).
4/5/2024