Unleash the Potential of CLIP for Video Highlight Detection
2404.01745
0
0

Abstract
Multimodal and large language models (LLMs) have revolutionized the utilization of open-world knowledge, unlocking novel potentials across various tasks and applications. Among these domains, the video domain has notably benefited from their capabilities. In this paper, we present Highlight-CLIP (HL-CLIP), a method designed to excel in the video highlight detection task by leveraging the pre-trained knowledge embedded in multimodal models. By simply fine-tuning the multimodal encoder in combination with our innovative saliency pooling technique, we have achieved the state-of-the-art performance in the highlight detection task, the QVHighlight Benchmark, to the best of our knowledge.
Create account to get full access
Overview
- This paper explores using the CLIP (Contrastive Language-Image Pre-training) model to detect video highlights.
- CLIP is a powerful machine learning model that can understand the semantic relationship between images and text.
- The researchers investigate how CLIP can be leveraged to identify key moments or "highlights" within videos.
- They introduce a new dataset called QVHighlight, which contains videos and human-annotated highlight segments.
- The paper presents a CLIP-based approach for video highlight detection and evaluates its performance on the QVHighlight dataset.
Plain English Explanation
The paper examines how a machine learning model called CLIP can be used to automatically identify the most interesting or exciting parts of a video. CLIP is trained to understand the meaning and context of images and text, and the researchers wanted to see if this capability could be applied to spotting video highlights.
To test this, the researchers created a new dataset called QVHighlight, which contains a collection of videos with specific segments labeled by humans as being the "highlights" of each video. They then developed a CLIP-based system that can analyze a video and determine which parts are the most compelling or noteworthy.
The key idea is that CLIP's ability to link visual information with textual descriptions could allow it to recognize the types of scenes or events that people tend to find most interesting in a video. For example, CLIP might be able to identify an exciting sports play or a funny comedic moment as a highlight, based on its understanding of the visual content and how it relates to typical highlight reel footage.
By using CLIP in this way, the researchers hope to enable more efficient video browsing and summarization, where viewers can quickly identify the most important or engaging parts of a video without having to watch the full length. This could be useful for applications like video sharing, online education, and entertainment.
Technical Explanation
The paper introduces a novel approach for video highlight detection using the CLIP (Contrastive Language-Image Pre-training) model. CLIP is a state-of-the-art deep learning model that can encode visual and textual information into a shared embedding space, allowing it to understand the semantic relationships between images and their associated descriptions.
The researchers hypothesized that CLIP's strong cross-modal understanding could be leveraged to identify the most salient and interesting segments within videos. To test this, they created the QVHighlight dataset, which contains 3,626 videos from various domains (e.g., sports, news, entertainment) with human-annotated highlight segments.
The proposed CLIP-based approach first encodes each video frame using the CLIP visual encoder, generating a sequence of visual embeddings. It then computes a textual embedding for each video by aggregating the visual embeddings weighted by their relevance to a learned "highlight" text prompt. Finally, the system identifies the video segments with the highest relevance scores as the detected highlights.
The authors evaluate their method on the QVHighlight dataset and compare it to several baselines, including video summarization techniques and other highlight detection approaches. The results demonstrate that the CLIP-based model outperforms the competing methods, achieving improved highlight detection performance as measured by various metrics.
Critical Analysis
The paper presents a compelling approach for leveraging the capabilities of the CLIP model to tackle the challenging task of video highlight detection. The introduction of the QVHighlight dataset is a valuable contribution, as it provides a standardized benchmark for evaluating highlight detection systems.
One strength of the proposed method is its ability to capture the semantic relationship between visual content and textual descriptions, which is a key advantage of the CLIP model. By learning a "highlight" text prompt, the system can effectively identify the video segments most relevant to this concept, yielding accurate highlight detection.
However, the paper does not provide a detailed analysis of the limitations or potential biases in the QVHighlight dataset or the CLIP-based approach. For example, it is unclear how well the method would generalize to more diverse or niche video domains beyond the ones represented in the dataset.
Additionally, the paper could have delved deeper into the interpretability and explainability of the CLIP-based highlight detection. Understanding the reasoning behind the system's decisions could lead to further improvements and more trust in the model's outputs.
Conclusion
This paper demonstrates the potential of the CLIP model for video highlight detection, a task with practical applications in video browsing, summarization, and content curation. By leveraging CLIP's cross-modal understanding, the proposed approach can effectively identify the most salient and engaging segments within videos, as evidenced by the strong performance on the QVHighlight dataset.
The introduction of the QVHighlight benchmark and the novel CLIP-based highlight detection method represent valuable contributions to the field of video analysis. These advancements could pave the way for more efficient and intelligent video management systems, empowering users to quickly navigate and consume video content.
While the paper demonstrates the promise of this approach, further research is needed to address potential limitations and explore the broader applicability of the CLIP-based technique across diverse video domains and use cases. Nonetheless, this work showcases the power of pre-trained models like CLIP in tackling complex multimedia challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
0
0
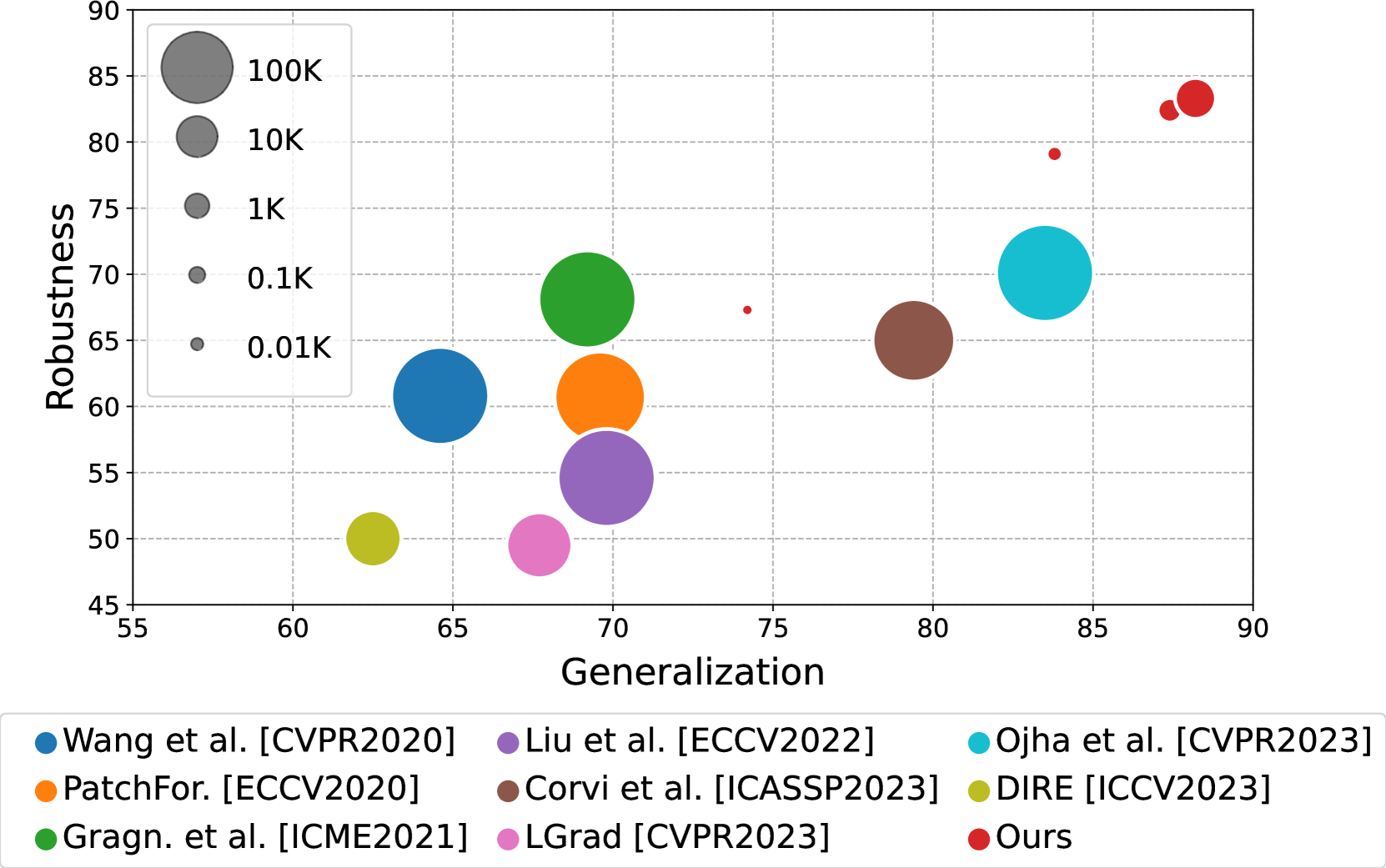
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
4/30/2024

The Surprising Effectiveness of Multimodal Large Language Models for Video Moment Retrieval
Meinardus Boris, Batra Anil, Rohrbach Anna, Rohrbach Marcus
0
0
Recent studies have shown promising results in utilizing multimodal large language models (MLLMs) for computer vision tasks such as object detection and semantic segmentation. However, many challenging video tasks remain under-explored. Video-language tasks necessitate spatial and temporal comprehension and require significant compute. Therefore, prior works have developed complex, highly specialized architectures or leveraged additional input signals such as video transcripts to best encode contextual and temporal information, which limits their generality and can be impractical. One particularly challenging task is video moment retrieval, which requires precise temporal and contextual grounding. This work demonstrates the surprising effectiveness of leveraging image-text pretrained MLLMs for moment retrieval. We introduce Mr. BLIP (Mr. as in Moment Retrieval), a multimodal, single-stage model that requires no expensive video-language pretraining, no additional input signal (e.g., no transcript or audio), and has a simpler and more versatile design than prior state-of-the-art methods. We achieve a new state-of-the-art in moment retrieval on the widely used benchmarks Charades-STA, QVHighlights, and ActivityNet Captions and illustrate our method's versatility with a new state-of-the-art in temporal action localization on ActivityNet. Notably, we attain over 9% (absolute) higher Recall (at 0.5 and 0.7 IoU) on the challenging long-video multi-moment QVHighlights benchmark. Our code is publicly available.
6/27/2024
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
0
0
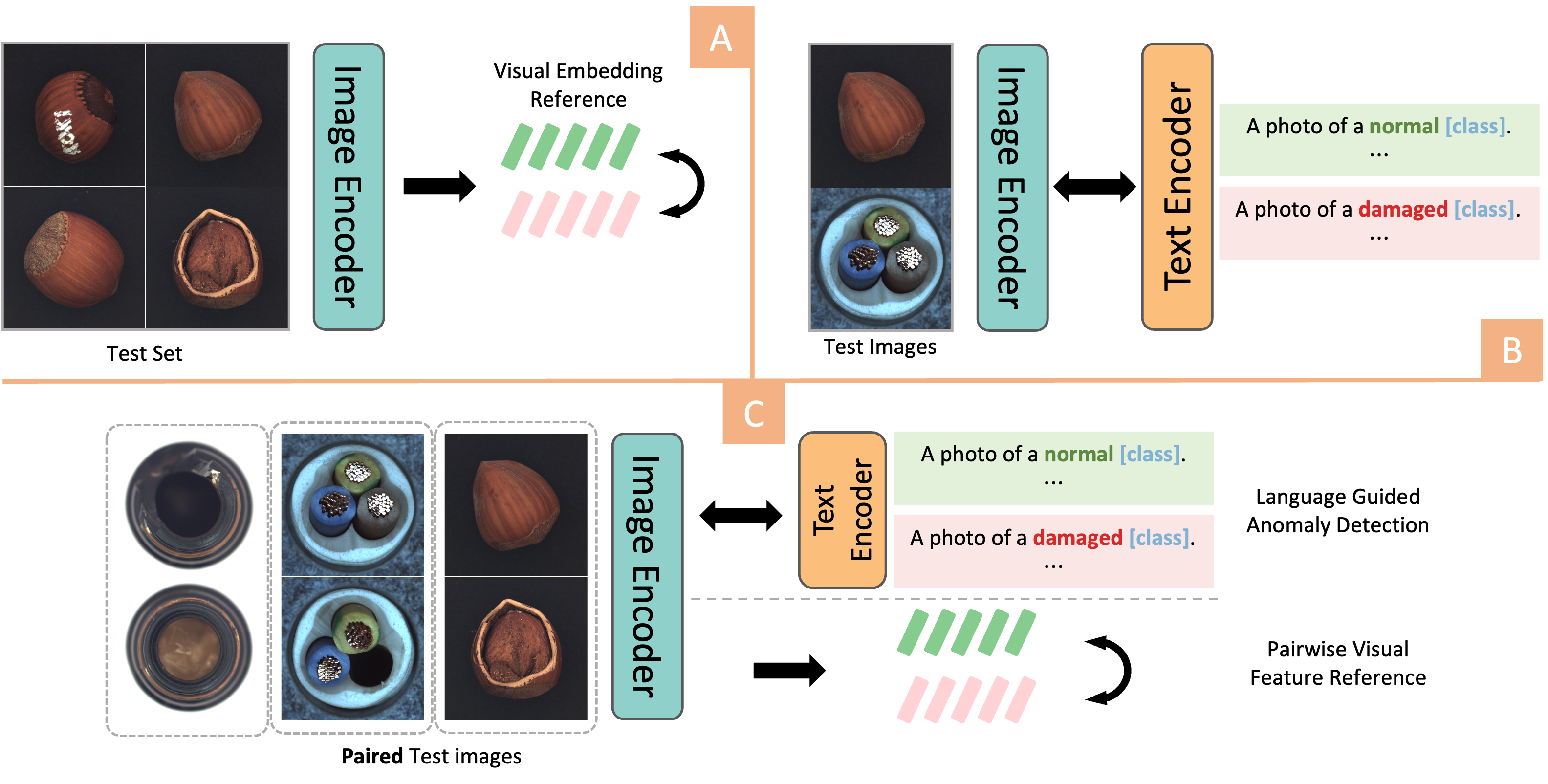
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
5/9/2024

CLIP with Quality Captions: A Strong Pretraining for Vision Tasks
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Oncel Tuzel
0
0
CLIP models perform remarkably well on zero-shot classification and retrieval tasks. But recent studies have shown that learnt representations in CLIP are not well suited for dense prediction tasks like object detection, semantic segmentation or depth estimation. More recently, multi-stage training methods for CLIP models was introduced to mitigate the weak performance of CLIP on downstream tasks. In this work, we find that simply improving the quality of captions in image-text datasets improves the quality of CLIP's visual representations, resulting in significant improvement on downstream dense prediction vision tasks. In fact, we find that CLIP pretraining with good quality captions can surpass recent supervised, self-supervised and weakly supervised pretraining methods. We show that when CLIP model with ViT-B/16 as image encoder is trained on well aligned image-text pairs it obtains 12.1% higher mIoU and 11.5% lower RMSE on semantic segmentation and depth estimation tasks over recent state-of-the-art Masked Image Modeling (MIM) pretraining methods like Masked Autoencoder (MAE). We find that mobile architectures also benefit significantly from CLIP pretraining. A recent mobile vision architecture, MCi2, with CLIP pretraining obtains similar performance as Swin-L, pretrained on ImageNet-22k for semantic segmentation task while being 6.1$times$ smaller. Moreover, we show that improving caption quality results in $10times$ data efficiency when finetuning for dense prediction tasks.
5/16/2024