Mixture of Modular Experts: Distilling Knowledge from a Multilingual Teacher into Specialized Modular Language Models

0

Sign in to get full access
Overview
- Presents a novel approach called "Mixture of Modular Experts" for distilling knowledge from a multilingual teacher model into specialized language models
- Aims to create efficient and customized language models for different tasks and languages
- Explores the benefits of modular language models compared to monolithic models
Plain English Explanation
The paper introduces a new technique called "Mixture of Modular Experts" that takes a powerful multilingual teacher model and distills its knowledge into specialized language models. The goal is to create efficient and customized models that are tailored for specific tasks and languages, rather than a single large model that tries to do everything.
The key idea is to break down the teacher model into a collection of "expert" models, each of which specializes in a particular aspect of language. These expert models can then be combined in different ways to create language models that are optimized for different use cases. For example, one expert might be great at handling technical jargon, while another excels at casual conversation.
By using this modular approach, the researchers hope to get the best of both worlds - the broad capabilities of a large multilingual model, combined with the efficiency and customization of specialized models. This could lead to more powerful and cost-effective language AI systems that can be fine-tuned for specific applications.
Technical Explanation
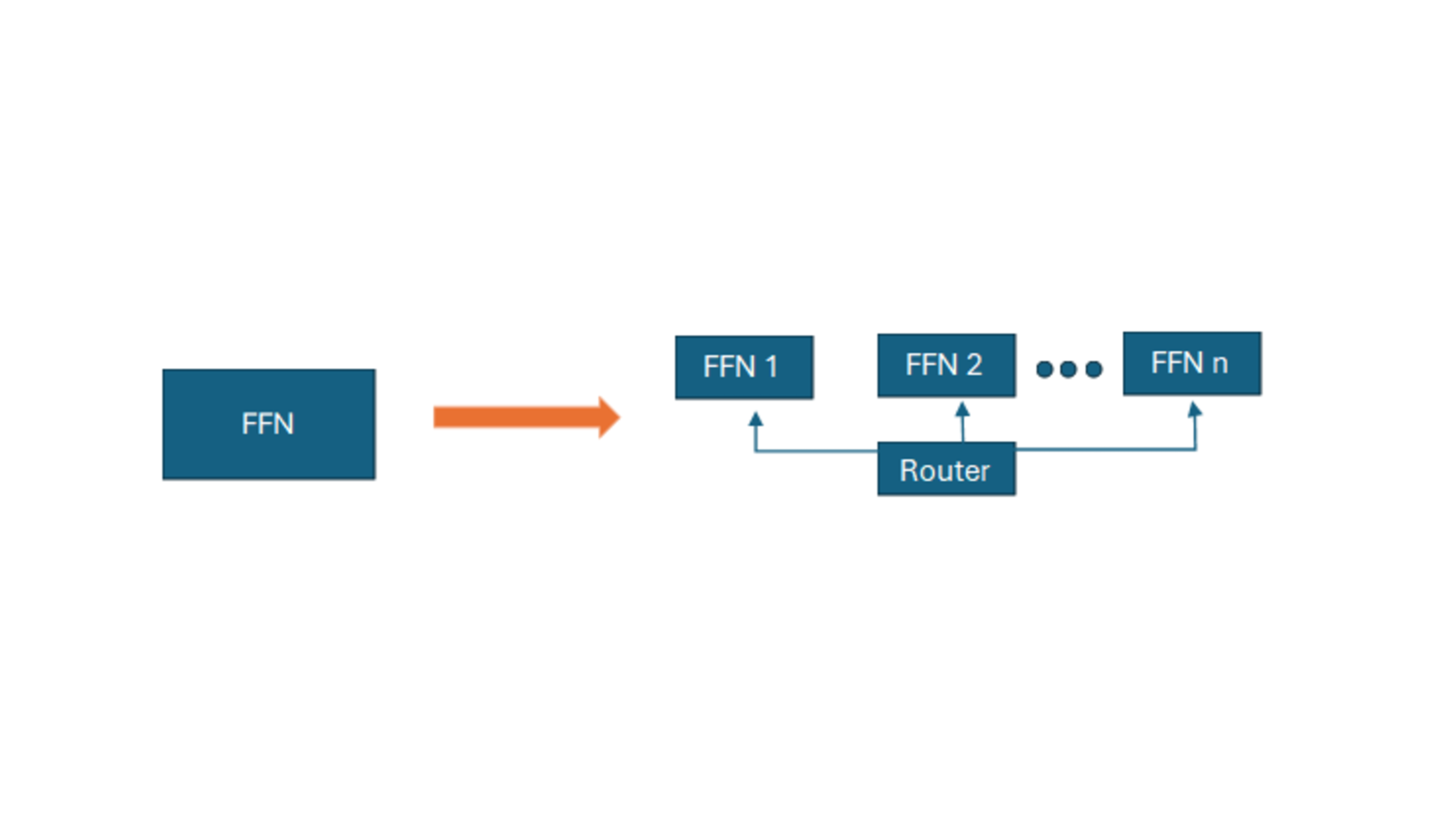
The paper proposes a novel approach called "Mixture of Modular Experts" (MoME) that aims to distill the knowledge from a powerful multilingual teacher model into a set of specialized modular language models. The key idea is to break down the teacher model into a collection of "expert" models, each of which specializes in a particular aspect of language. These expert models can then be combined in different ways to create language models that are optimized for different tasks and languages.
The researchers first train a large multilingual teacher model using standard techniques. They then use a distillation process to transfer the knowledge from this teacher model into a set of modular expert models. Each expert model is trained to handle a specific aspect of language, such as technical jargon, casual conversation, or a particular language.
To create a specialized language model for a given task or language, the researchers then combine the relevant expert models using a gating mechanism. This allows the model to dynamically allocate its resources to the most important expert modules for a particular input, rather than treating all aspects of language equally.
The researchers evaluate their MoME approach on a range of language tasks and find that it outperforms both the original teacher model and a standard monolithic language model. They also show that the modular models are more efficient and can be more easily customized for different applications.
Critical Analysis
The paper presents a compelling approach for creating specialized language models by distilling knowledge from a larger multilingual teacher model. The modular nature of the MoME approach offers several potential benefits, including improved efficiency, customization, and the ability to handle a diverse range of language tasks and domains.
However, the paper does not fully address some potential limitations and areas for further research. For example, the distillation process from the teacher model to the expert models may result in some loss of knowledge or performance, which could limit the overall capabilities of the specialized models. Additionally, the complexity of the gating mechanism used to combine the expert models could introduce additional computational overhead, potentially offsetting some of the efficiency gains.
It would also be valuable to see the MoME approach evaluated on a broader range of tasks and languages, as well as in real-world applications, to better understand its strengths, weaknesses, and practical implications. The paper could also benefit from a more thorough discussion of the ethical considerations and potential societal impact of deploying such modular language models in various contexts.
Overall, the MoME approach represents an interesting and promising direction in the field of language modeling, but further research and development may be needed to fully realize its potential.
Conclusion
The "Mixture of Modular Experts" (MoME) approach presented in this paper offers a novel way to distill knowledge from a powerful multilingual teacher model into specialized language models. By breaking down the teacher model into a collection of expert models, each focusing on a particular aspect of language, the researchers have created a more efficient and customizable framework for deploying language AI systems.
The modular nature of the MoME approach could lead to significant improvements in the performance, cost-effectiveness, and flexibility of language models, allowing them to be better tailored to specific tasks, domains, and user needs. While the paper highlights the potential benefits of this approach, further research and development will be necessary to fully explore its implications and address any limitations.
As the field of natural language processing continues to evolve, techniques like MoME may play an increasingly important role in creating language AI systems that are more powerful, efficient, and accessible to a wide range of applications and users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mixture of Modular Experts: Distilling Knowledge from a Multilingual Teacher into Specialized Modular Language Models
Mohammed Al-Maamari, Mehdi Ben Amor, Michael Granitzer
This research combines Knowledge Distillation (KD) and Mixture of Experts (MoE) to develop modular, efficient multilingual language models. Key objectives include evaluating adaptive versus fixed alpha methods in KD and comparing modular MoE architectures for handling multi-domain inputs and preventing catastrophic forgetting. KD compresses large language models (LLMs) into smaller, efficient models, while MoE enhances modularity with specialized tasks. Experiments showed similar performance for both KD methods, with marginal improvements from adaptive alpha. A combined loss approach provided more stable learning. The router, trained to classify input sequences into English, French, German, or Python, achieved 99.95% precision, recall, and F1 score, with Logistic Regression being the most effective classifier. Evaluations of modular MoE architectures revealed that Pre-trained Language Experts (PLE) and Joint Expert Embedding Training (JEET) performed similarly, while the MoE with Common Expert (MoE-CE) setup showed slightly lower performance. Including a common expert in MoE-CE improved its performance. Studies on catastrophic forgetting indicated that sequential training led to significant forgetting, while single-session training with balanced batches and the MoE approach mitigated this issue. The MoE architecture preserved knowledge across multiple languages effectively. The research contributes open-sourced resources including the dataset (https://zenodo.org/doi/10.5281/zenodo.12677631), a balanced dataset creation tool (https://github.com/padas-lab-de/multi-language-dataset-creator), and the research codebase (https://github.com/ModMaamari/mixture-modular-experts).
Read more7/30/2024

0
A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
Read more6/27/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024
0
Flexible and Effective Mixing of Large Language Models into a Mixture of Domain Experts
Rhui Dih Lee, Laura Wynter, Raghu Kiran Ganti
We present a toolkit for creating low-cost Mixture-of-Domain-Experts (MOE) from trained models. The toolkit can be used for creating a mixture from models or from adapters. We perform extensive tests and offer guidance on defining the architecture of the resulting MOE using the toolkit. A public repository is available.
Read more9/12/2024