MoReVQA: Exploring Modular Reasoning Models for Video Question Answering
2404.06511
0
0
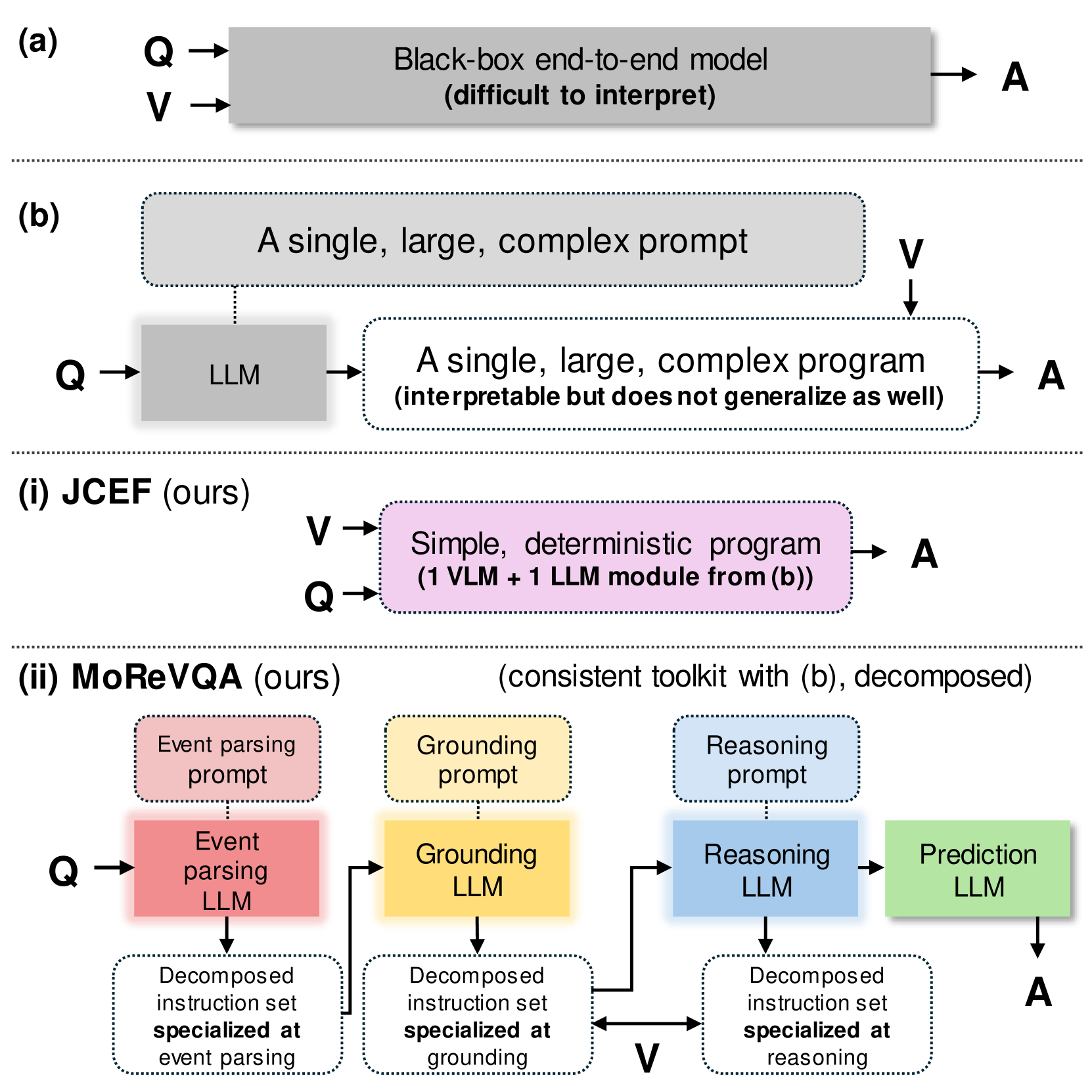
Abstract
This paper addresses the task of video question answering (videoQA) via a decomposed multi-stage, modular reasoning framework. Previous modular methods have shown promise with a single planning stage ungrounded in visual content. However, through a simple and effective baseline, we find that such systems can lead to brittle behavior in practice for challenging videoQA settings. Thus, unlike traditional single-stage planning methods, we propose a multi-stage system consisting of an event parser, a grounding stage, and a final reasoning stage in conjunction with an external memory. All stages are training-free, and performed using few-shot prompting of large models, creating interpretable intermediate outputs at each stage. By decomposing the underlying planning and task complexity, our method, MoReVQA, improves over prior work on standard videoQA benchmarks (NExT-QA, iVQA, EgoSchema, ActivityNet-QA) with state-of-the-art results, and extensions to related tasks (grounded videoQA, paragraph captioning).
Create account to get full access
Overview
- This paper, "MoReVQA: Exploring Modular Reasoning Models for Video Question Answering," investigates the use of modular reasoning approaches for video question answering tasks.
- The authors propose a novel modular reasoning framework that aims to break down complex video-based questions into simpler sub-tasks, which can then be addressed using specialized modules.
- The paper evaluates the performance of this modular reasoning approach on several benchmark video question answering datasets, and compares it to more traditional end-to-end neural network models.
Plain English Explanation
The paper explores a new way of answering questions about videos, called "modular reasoning." Instead of using a single, complex machine learning model to answer all types of questions, the researchers break down the problem into smaller, simpler sub-tasks. Each sub-task is handled by a specialized "module" within the system.
For example, if a question is about the color of an object in a video, there might be a module that is specifically trained to identify colors. If the question is about the actions of a person in the video, there might be a module that is trained to recognize different types of human behavior. By breaking the problem down in this way, the researchers hope to create a more efficient and effective video question answering system.
The paper tests this modular reasoning approach on several existing datasets of video questions and answers. The results are compared to more traditional, end-to-end machine learning models that try to solve the entire problem at once. The authors find that their modular approach can outperform the traditional models in many cases, suggesting that this could be a promising direction for future research in video question answering.
Technical Explanation
The authors of this paper propose a novel "Modular Reasoning" framework for video question answering (VQA), called MoReVQA. This approach aims to break down complex video-based questions into simpler sub-tasks, which can then be addressed using specialized modules.
At the core of the MoReVQA framework is a module-based architecture, where each module is responsible for handling a specific type of sub-task, such as object detection, action recognition, or spatial reasoning. These modules are trained independently, and then combined in a flexible way to answer the original question.
The paper also introduces a novel module-gating mechanism, which allows the system to dynamically select the most appropriate modules for a given question, based on an analysis of the question's content and structure. This helps to ensure that the system focuses on the most relevant aspects of the video when answering the question.
To evaluate the effectiveness of the MoReVQA approach, the authors conduct experiments on several benchmark VQA datasets, including TINYVQA, Design-as-Desired, and HAMMR. They compare the performance of MoReVQA to that of more traditional end-to-end VQA models, and find that their modular approach can achieve state-of-the-art results on several of the benchmark tasks.
Critical Analysis
The authors of the paper provide a thorough evaluation of the MoReVQA framework and demonstrate its effectiveness on several benchmark VQA datasets. However, the paper does not address some potential limitations of the modular reasoning approach.
One potential concern is the scalability of the MoReVQA framework as the number of sub-tasks and modules increases. Maintaining and coordinating a large number of specialized modules could become computationally and organizationally challenging, especially in real-world applications with a wide range of possible questions and video content.
Additionally, the paper does not explore the robustness of the modular approach to changes in the underlying video and question data. It is possible that the performance of the system could degrade if the distribution of the test data differs significantly from the training data, as the specialized modules may not generalize well to unfamiliar situations.
Further research could also investigate the interpretability and explainability of the MoReVQA framework, as the modular design may allow for better insights into the system's decision-making process compared to traditional end-to-end models.
Conclusion
The "MoReVQA: Exploring Modular Reasoning Models for Video Question Answering" paper presents a promising approach to video question answering by leveraging a modular reasoning framework. The authors demonstrate that breaking down complex video-based questions into simpler sub-tasks and addressing them using specialized modules can lead to improved performance compared to traditional end-to-end models.
This work highlights the potential benefits of modular architectures in complex multimodal tasks, such as improved flexibility, efficiency, and interpretability. As the field of video question answering continues to evolve, the insights and techniques explored in this paper may inspire further research into modular and compositional approaches to tackle challenging problems at the intersection of computer vision, natural language processing, and reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
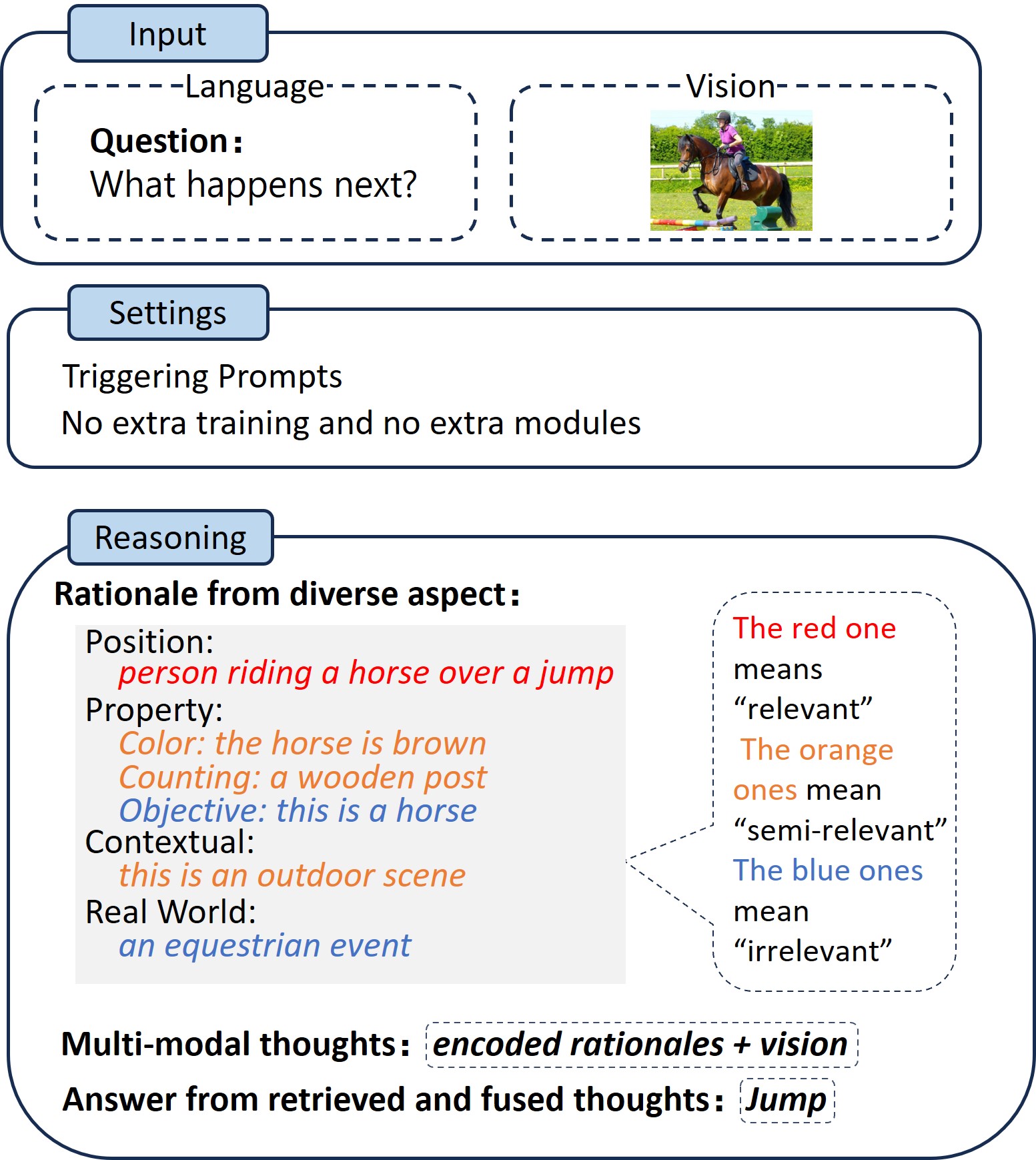
Mixture of Rationale: Multi-Modal Reasoning Mixture for Visual Question Answering
Tao Li, Linjun Shou, Xuejun Liu
0
0
Zero-shot visual question answering (VQA) is a challenging task that requires reasoning across modalities. While some existing methods rely on a single rationale within the Chain of Thoughts (CoT) framework, they may fall short of capturing the complexity of the VQA problem. On the other hand, some other methods that use multiple rationales may still suffer from low diversity, poor modality alignment, and inefficient retrieval and fusion. In response to these challenges, we propose emph{Mixture of Rationales (MoR)}, a novel multi-modal reasoning method that mixes multiple rationales for VQA. MoR uses a single frozen Vision-and-Language Pre-trained Models (VLPM) model to {dynamically generate, retrieve and fuse multi-modal thoughts}. We evaluate MoR on two challenging VQA datasets, i.e. NLVR2 and OKVQA, with two representative backbones OFA and VL-T5. MoR achieves a 12.43% accuracy improvement on NLVR2, and a 2.45% accuracy improvement on OKVQA-S( the science and technology category of OKVQA).
6/4/2024

Disentangling Knowledge-based and Visual Reasoning by Question Decomposition in KB-VQA
Elham J. Barezi, Parisa Kordjamshidi
0
0
We study the Knowledge-Based visual question-answering problem, for which given a question, the models need to ground it into the visual modality to find the answer. Although many recent works use question-dependent captioners to verbalize the given image and use Large Language Models to solve the VQA problem, the research results show they are not reasonably performing for multi-hop questions. Our study shows that replacing a complex question with several simpler questions helps to extract more relevant information from the image and provide a stronger comprehension of it. Moreover, we analyze the decomposed questions to find out the modality of the information that is required to answer them and use a captioner for the visual questions and LLMs as a general knowledge source for the non-visual KB-based questions. Our results demonstrate the positive impact of using simple questions before retrieving visual or non-visual information. We have provided results and analysis on three well-known VQA datasets including OKVQA, A-OKVQA, and KRVQA, and achieved up to 2% improvement in accuracy.
6/28/2024

Weakly Supervised Gaussian Contrastive Grounding with Large Multimodal Models for Video Question Answering
Haibo Wang, Chenghang Lai, Yixuan Sun, Weifeng Ge
0
0
Video Question Answering (VideoQA) aims to answer natural language questions based on the information observed in videos. Despite the recent success of Large Multimodal Models (LMMs) in image-language understanding and reasoning, they deal with VideoQA insufficiently, by simply taking uniformly sampled frames as visual inputs, which ignores question-relevant visual clues. Moreover, there are no human annotations for question-critical timestamps in existing VideoQA datasets. In light of this, we propose a novel weakly supervised framework to enforce the LMMs to reason out the answers with question-critical moments as visual inputs. Specifically, we first fuse the question and answer pairs as event descriptions to find multiple keyframes as target moments and pseudo-labels, with the visual-language alignment capability of the CLIP models. With these pseudo-labeled keyframes as additionally weak supervision, we devise a lightweight Gaussian-based Contrastive Grounding (GCG) module. GCG learns multiple Gaussian functions to characterize the temporal structure of the video, and sample question-critical frames as positive moments to be the visual inputs of LMMs. Extensive experiments on several benchmarks verify the effectiveness of our framework, and we achieve substantial improvements compared to previous state-of-the-art methods.
4/29/2024

II-MMR: Identifying and Improving Multi-modal Multi-hop Reasoning in Visual Question Answering
Jihyung Kil, Farideh Tavazoee, Dongyeop Kang, Joo-Kyung Kim
0
0
Visual Question Answering (VQA) often involves diverse reasoning scenarios across Vision and Language (V&L). Most prior VQA studies, however, have merely focused on assessing the model's overall accuracy without evaluating it on different reasoning cases. Furthermore, some recent works observe that conventional Chain-of-Thought (CoT) prompting fails to generate effective reasoning for VQA, especially for complex scenarios requiring multi-hop reasoning. In this paper, we propose II-MMR, a novel idea to identify and improve multi-modal multi-hop reasoning in VQA. In specific, II-MMR takes a VQA question with an image and finds a reasoning path to reach its answer using two novel language promptings: (i) answer prediction-guided CoT prompt, or (ii) knowledge triplet-guided prompt. II-MMR then analyzes this path to identify different reasoning cases in current VQA benchmarks by estimating how many hops and what types (i.e., visual or beyond-visual) of reasoning are required to answer the question. On popular benchmarks including GQA and A-OKVQA, II-MMR observes that most of their VQA questions are easy to answer, simply demanding single-hop reasoning, whereas only a few questions require multi-hop reasoning. Moreover, while the recent V&L model struggles with such complex multi-hop reasoning questions even using the traditional CoT method, II-MMR shows its effectiveness across all reasoning cases in both zero-shot and fine-tuning settings.
6/4/2024