MLIP: Efficient Multi-Perspective Language-Image Pretraining with Exhaustive Data Utilization
2406.01460
0
0

Abstract
Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success, leading to rapid advancements in multimodal studies. However, CLIP faces a notable challenge in terms of inefficient data utilization. It relies on a single contrastive supervision for each image-text pair during representation learning, disregarding a substantial amount of valuable information that could offer richer supervision. Additionally, the retention of non-informative tokens leads to increased computational demands and time costs, particularly in CLIP's ViT image encoder. To address these issues, we propose Multi-Perspective Language-Image Pretraining (MLIP). In MLIP, we leverage the frequency transform's sensitivity to both high and low-frequency variations, which complements the spatial domain's sensitivity limited to low-frequency variations only. By incorporating frequency transforms and token-level alignment, we expand CILP's single supervision into multi-domain and multi-level supervision, enabling a more thorough exploration of informative image features. Additionally, we introduce a token merging method guided by comprehensive semantics from the frequency and spatial domains. This allows us to merge tokens to multi-granularity tokens with a controllable compression rate to accelerate CLIP. Extensive experiments validate the effectiveness of our design.
Create account to get full access
Overview
- Introduces a novel language-image pretraining approach called "MLIP" (Efficient Multi-Perspective Language-Image Pretraining with Exhaustive Data Utilization)
- Aims to improve the efficiency and performance of cross-modal pretraining models like CLIP and RankCLIP
- Leverages multiple self-supervised pretraining tasks and a large, diverse dataset to achieve strong results on various vision-language benchmarks
Plain English Explanation
MLIP is a new approach to training machine learning models that can understand and work with both language and images. The key idea is to use a variety of self-supervised pretraining tasks, along with a large and diverse dataset, to teach the model to extract useful information from both text and visual data.
The researchers behind MLIP recognized that existing approaches, like CLIP and RankCLIP, could be made more efficient and effective. By incorporating multiple pretraining objectives and leveraging a comprehensive dataset, MLIP aims to create a more capable and versatile language-image model.
The advantage of this approach is that the model can learn to understand the connections between words and visual concepts, allowing it to perform a wide range of tasks, such as image captioning, visual question answering, and image retrieval. This could be useful in applications like medical imaging, where the ability to interpret both text and images is crucial.
Technical Explanation
The MLIP framework consists of several key components:
-
Multi-Perspective Pretraining Tasks: The researchers designed a suite of self-supervised pretraining tasks that expose the model to different aspects of language-image relationships. These include masked language modeling, image-text matching, and visual reasoning.
-
Exhaustive Data Utilization: MLIP is trained on a large and diverse dataset that covers a wide range of topics and visual domains. This allows the model to learn robust representations that generalize well to various downstream tasks.
-
Efficient Architecture: The MLIP model leverages a transformer-based architecture, similar to CLIP, but with several optimization techniques to improve its efficiency and performance.
The researchers conducted extensive experiments to evaluate MLIP's performance on a variety of vision-language benchmarks, including image-text retrieval, visual question answering, and image captioning. The results demonstrate that MLIP outperforms state-of-the-art models like CLIP and RankCLIP, while requiring less computational resources during training and inference.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to language-image pretraining. However, there are a few potential limitations and areas for further research:
-
Dataset Bias: While the researchers claim to use a diverse dataset, it's possible that certain biases or skewed distributions in the data could still impact the model's performance and generalization. Further investigation into the dataset's characteristics and their influence on the results would be valuable.
-
Computational Complexity: Although MLIP is more efficient than some existing models, the pretraining and fine-tuning process is still computationally intensive. Exploring ways to further reduce the computational requirements without sacrificing performance could broaden the accessibility and deployment of such models.
-
Interpretability: The paper does not delve deeply into the interpretability of the MLIP model's internal representations and decision-making process. Gaining a better understanding of how the model arrives at its outputs could lead to more transparent and trustworthy applications of language-image AI systems.
Despite these potential areas for improvement, the MLIP approach represents a significant advancement in the field of cross-modal pretraining and could have far-reaching implications for various applications that require understanding both language and visual data, such as medical image analysis and online lifelong learning.
Conclusion
The MLIP paper introduces a novel and efficient approach to language-image pretraining that leverages multiple self-supervised tasks and a large, diverse dataset. The results demonstrate that this approach can outperform state-of-the-art models while requiring less computational resources. The potential applications of MLIP-like models are broad, ranging from medical imaging to online lifelong learning. As the field of cross-modal AI continues to evolve, the MLIP framework provides a promising direction for further research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
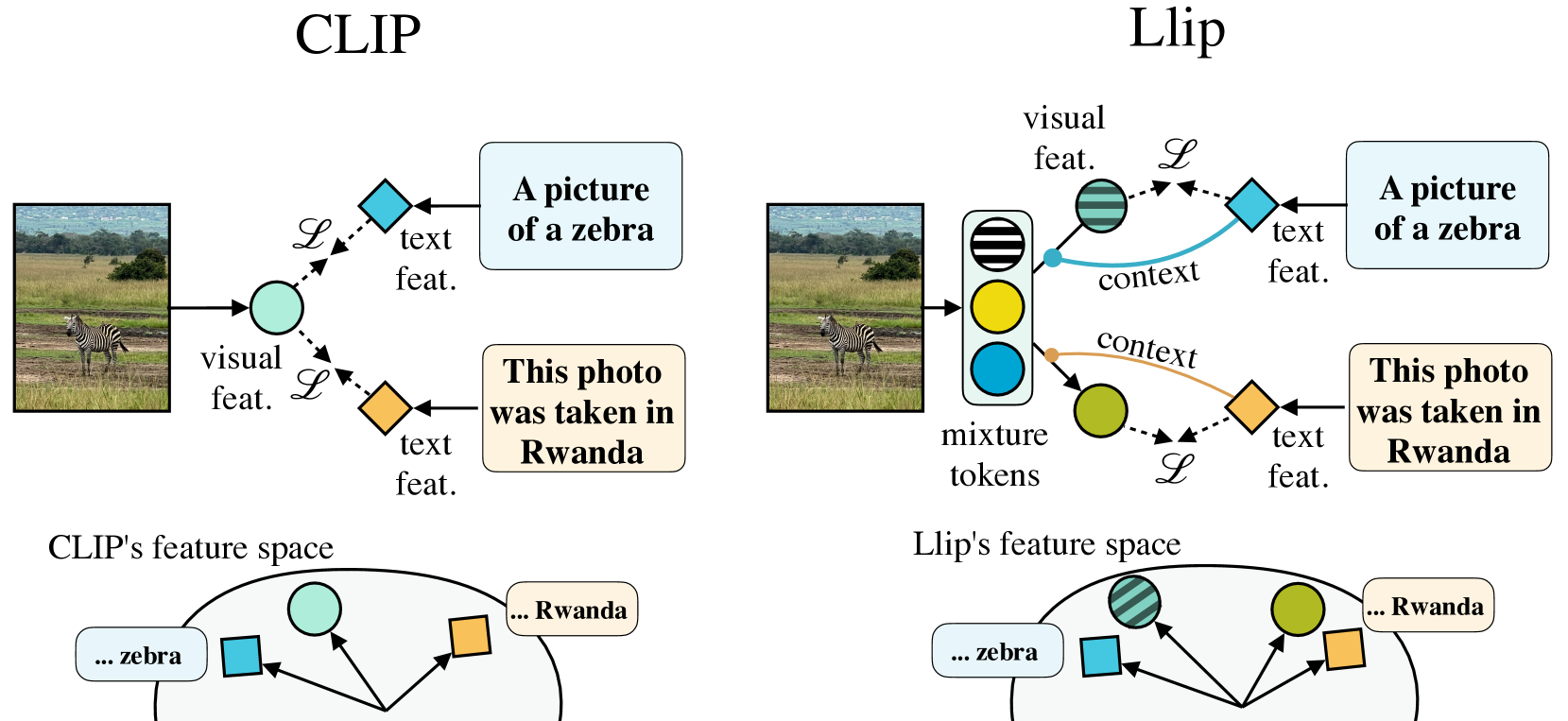
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
6/21/2024

CLIP in Medical Imaging: A Comprehensive Survey
Zihao Zhao, Yuxiao Liu, Han Wu, Yonghao Li, Sheng Wang, Lin Teng, Disheng Liu, Zhiming Cui, Qian Wang, Dinggang Shen
0
0
Contrastive Language-Image Pre-training (CLIP), a simple yet effective pre-training paradigm, successfully introduces text supervision to vision models. It has shown promising results across various tasks, attributable to its generalizability and interpretability. The use of CLIP has recently gained increasing interest in the medical imaging domain, serving both as a pre-training paradigm for aligning medical vision and language, and as a critical component in diverse clinical tasks. With the aim of facilitating a deeper understanding of this promising direction, this survey offers an in-depth exploration of the CLIP paradigm within the domain of medical imaging, regarding both refined CLIP pre-training and CLIP-driven applications. In this study, We (1) start with a brief introduction to the fundamentals of CLIP methodology. (2) Then, we investigate the adaptation of CLIP pre-training in the medical domain, focusing on how to optimize CLIP given characteristics of medical images and reports. (3) Furthermore, we explore the practical utilization of CLIP pre-trained models in various tasks, including classification, dense prediction, and cross-modal tasks. (4) Finally, we discuss existing limitations of CLIP in the context of medical imaging and propose forward-looking directions to address the demands of medical imaging domain. We expect that this comprehensive survey will provide researchers in the field of medical image analysis with a holistic understanding of the CLIP paradigm and its potential implications. The project page can be found on https://github.com/zhaozh10/Awesome-CLIP-in-Medical-Imaging.
5/22/2024

CLIP model is an Efficient Online Lifelong Learner
Leyuan Wang, Liuyu Xiang, Yujie Wei, Yunlong Wang, Zhaofeng He
0
0
Online Lifelong Learning (OLL) addresses the challenge of learning from continuous and non-stationary data streams. Existing online lifelong learning methods based on image classification models often require preset conditions such as the total number of classes or maximum memory capacity, which hinders the realization of real never-ending learning and renders them impractical for real-world scenarios. In this work, we propose that vision-language models, such as Contrastive Language-Image Pretraining (CLIP), are more suitable candidates for online lifelong learning. We discover that maintaining symmetry between image and text is crucial during Parameter-Efficient Tuning (PET) for CLIP model in online lifelong learning. To this end, we introduce the Symmetric Image-Text (SIT) tuning strategy. We conduct extensive experiments on multiple lifelong learning benchmark datasets and elucidate the effectiveness of SIT through gradient analysis. Additionally, we assess the impact of lifelong learning on generalizability of CLIP and found that tuning the image encoder is beneficial for lifelong learning, while tuning the text encoder aids in zero-shot learning.
5/27/2024