CLIP in Medical Imaging: A Comprehensive Survey
2312.07353
0
0

Abstract
Contrastive Language-Image Pre-training (CLIP), a simple yet effective pre-training paradigm, successfully introduces text supervision to vision models. It has shown promising results across various tasks, attributable to its generalizability and interpretability. The use of CLIP has recently gained increasing interest in the medical imaging domain, serving both as a pre-training paradigm for aligning medical vision and language, and as a critical component in diverse clinical tasks. With the aim of facilitating a deeper understanding of this promising direction, this survey offers an in-depth exploration of the CLIP paradigm within the domain of medical imaging, regarding both refined CLIP pre-training and CLIP-driven applications. In this study, We (1) start with a brief introduction to the fundamentals of CLIP methodology. (2) Then, we investigate the adaptation of CLIP pre-training in the medical domain, focusing on how to optimize CLIP given characteristics of medical images and reports. (3) Furthermore, we explore the practical utilization of CLIP pre-trained models in various tasks, including classification, dense prediction, and cross-modal tasks. (4) Finally, we discuss existing limitations of CLIP in the context of medical imaging and propose forward-looking directions to address the demands of medical imaging domain. We expect that this comprehensive survey will provide researchers in the field of medical image analysis with a holistic understanding of the CLIP paradigm and its potential implications. The project page can be found on https://github.com/zhaozh10/Awesome-CLIP-in-Medical-Imaging.
Create account to get full access
Overview
- This paper provides a comprehensive survey of the application of CLIP (Contrastive Language-Image Pre-training) models in medical imaging.
- CLIP is a powerful vision-language model that has shown impressive performance on a wide range of tasks, including medical image analysis.
- The survey covers the key developments and applications of CLIP in medical imaging, as well as the challenges and limitations of the approach.
Plain English Explanation
CLIP is a type of artificial intelligence (AI) model that has become very popular in recent years. It is a "vision-language" model, which means it can understand and process both images and text. CLIP has shown that it can perform very well on a wide variety of tasks, including analyzing medical images.
This paper reviews all the different ways that researchers have been using CLIP for medical imaging applications. It covers the key ideas behind how CLIP works, and the various ways it has been adapted and applied in the medical field. The paper also discusses the challenges and limitations of using CLIP for medical imaging, and areas where further research is needed.
The main goal of the paper is to provide a comprehensive overview of the current state of CLIP in medical imaging, to help researchers and practitioners understand the current capabilities and limitations of the technology. By summarizing all the relevant work in this area, the paper aims to serve as a useful resource for those interested in applying CLIP to medical imaging problems.
Technical Explanation
The paper begins by providing background on the CLIP model itself. CLIP is a type of contrastive language-image pre-training model, which means it is trained on a large dataset of image-text pairs to learn a joint representation of visual and textual information. This allows CLIP to perform well on a variety of "vision-language" tasks, such as image captioning, visual question answering, and zero-shot image classification.
The survey then goes on to cover the various ways CLIP has been adapted and applied in the medical imaging domain. This includes work on demystifying the CLIP dataset and scaling down CLIP for medical applications. The paper also reviews research on using CLIP for specific medical imaging tasks, such as mammography classification and medical image retrieval.
Throughout the technical explanation, the paper highlights the key insights and findings from the various studies covered, as well as the limitations and challenges of applying CLIP in medical imaging. For example, the survey discusses issues around the suitability of the CLIP pretraining data for medical applications, and the need for further research on how to effectively fine-tune and adapt CLIP for medical imaging tasks.
Critical Analysis
The paper provides a thorough and well-researched survey of the application of CLIP in medical imaging. It does a commendable job of covering the breadth of work in this area, from the underlying CLIP model to the various medical imaging use cases.
However, one potential limitation is that the survey may not delve deeply enough into the specific technical details and experimental findings of the individual studies. While the high-level summaries are useful, some readers may wish for more in-depth analysis of the methodologies and results reported in the reviewed papers.
Additionally, the paper does not extensively critique or question the validity of the research covered. While it does mention some of the limitations and challenges, a more critical examination of the assumptions, potential biases, and areas for improvement could further strengthen the survey.
Nevertheless, the paper serves as a valuable resource for understanding the current state of CLIP in medical imaging. By synthesizing a large body of work in this area, it provides a solid foundation for researchers and practitioners interested in exploring the applications of CLIP in the medical domain.
Conclusion
This comprehensive survey paper provides a detailed overview of the use of CLIP (Contrastive Language-Image Pre-training) models in medical imaging. It covers the key developments, applications, and insights from the growing body of research in this area.
The paper explains the underlying CLIP model and its potential benefits for medical imaging tasks, and then reviews a wide range of studies that have adapted and applied CLIP to various medical imaging domains. This includes work on demystifying the CLIP dataset, scaling down CLIP for medical applications, and using CLIP for specific tasks like mammography classification and medical image retrieval.
While the paper could potentially go deeper into the technical details and provide more critical analysis, it still serves as a valuable resource for understanding the current state of CLIP in medical imaging. By synthesizing the key research in this area, the survey offers a solid foundation for those interested in exploring the use of CLIP for medical imaging applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
6/21/2024
📊
Demystifying CLIP Data
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer
0
0
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
4/9/2024

MLIP: Efficient Multi-Perspective Language-Image Pretraining with Exhaustive Data Utilization
Yu Zhang, Qi Zhang, Zixuan Gong, Yiwei Shi, Yepeng Liu, Duoqian Miao, Yang Liu, Ke Liu, Kun Yi, Wei Fan, Liang Hu, Changwei Wang
0
0
Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success, leading to rapid advancements in multimodal studies. However, CLIP faces a notable challenge in terms of inefficient data utilization. It relies on a single contrastive supervision for each image-text pair during representation learning, disregarding a substantial amount of valuable information that could offer richer supervision. Additionally, the retention of non-informative tokens leads to increased computational demands and time costs, particularly in CLIP's ViT image encoder. To address these issues, we propose Multi-Perspective Language-Image Pretraining (MLIP). In MLIP, we leverage the frequency transform's sensitivity to both high and low-frequency variations, which complements the spatial domain's sensitivity limited to low-frequency variations only. By incorporating frequency transforms and token-level alignment, we expand CILP's single supervision into multi-domain and multi-level supervision, enabling a more thorough exploration of informative image features. Additionally, we introduce a token merging method guided by comprehensive semantics from the frequency and spatial domains. This allows us to merge tokens to multi-granularity tokens with a controllable compression rate to accelerate CLIP. Extensive experiments validate the effectiveness of our design.
6/5/2024
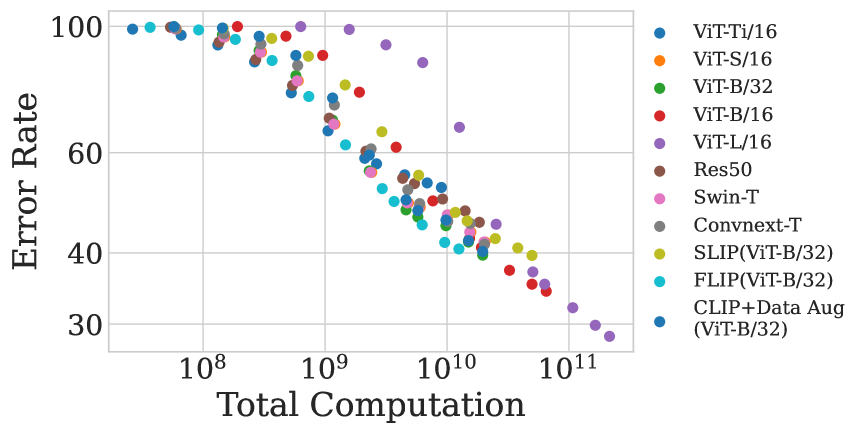
Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
Zichao Li, Cihang Xie, Ekin Dogus Cubuk
0
0
This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute. Additionally, we provide guidance on when to choose a CNN-based architecture or a ViT-based architecture for CLIP training. We compare four CLIP training strategies - SLIP, FLIP, CLIP, and CLIP+Data Augmentation - and show that the choice of training strategy depends on the available compute resource. Our analysis reveals that CLIP+Data Augmentation can achieve comparable performance to CLIP using only half of the training data. This work provides practical insights into how to effectively train and deploy CLIP models, making them more accessible and affordable for practical use in various applications.
4/17/2024