MLLM-Bench: Evaluating Multimodal LLMs with Per-sample Criteria
2311.13951
0
0

Abstract
Multimodal large language models (MLLMs) (e.g., GPT-4V, LLaVA, and Claude-3) have broadened the scope of AI applications. Yet, evaluating their performance presents a significant challenge owing to the inherently subjective nature of tasks that do not yield clear-cut solutions especially for those open-ended queries. Existing automatic evaluation methodologies are mainly limited in evaluating objective queries without considering real-world user experiences, inadequately addressing the nuances of creative and associative multimodal tasks. In our paper, we propose a new evaluation paradigm for MLLMs, which is evaluating MLLMs with textit{per-sample criteria} using potent MLLM as the judge. To validate the feasibility and effectiveness of this paradigm, we design a benchmark, dubbed textit{MLLM-Bench}, with the evaluation samples across six critical levels following the revised Bloom's Taxonomy with the ethical consideration. We benchmark 21 popular MLLMs in a pairwise-comparison fashion, showing diverse performance across models. Moreover, the validity of our benchmark manifests itself in reaching 88.02% agreement with human evaluation. We contend that the proposed paradigm explores the potential of MLLMs as effective evaluation tools with the help of per-sample criteria, and that MLLM-Bench will serve as a catalyst for encouraging the development of user-centric MLLMs tailored to real-world applications. Our benchmark data, online leaderboard and submission entry are at https://mllm-bench.llmzoo.com.
Create account to get full access
Overview
- This paper introduces MLLM-Bench, a new benchmark for evaluating multi-modal large language models (LLMs) using GPT-4V.
- MLLM-Bench is designed to assess the performance of multi-modal LLMs across a variety of tasks, including visual reasoning, long-context understanding, and cross-lingual generalization.
- The benchmark aims to provide a comprehensive and standardized way to evaluate the capabilities of multi-modal LLMs, helping to track progress in this rapidly evolving field.
Plain English Explanation
MLLM-Bench is a new tool that allows researchers to test how well large AI language models that can handle both text and images (called "multi-modal" models) perform on a variety of tasks. These tasks include:
- Visual Reasoning: Analyzing images and understanding their contents.
- Long-Context Understanding: Comprehending and reasoning about information spread across long passages of text.
- Cross-Lingual Generalization: Applying knowledge learned in one language to tasks in other languages.
By having a standardized way to evaluate these models, the researchers hope to help track the progress of multi-modal AI as the technology continues to evolve. This will allow them to better understand the current capabilities and limitations of these advanced language models.
Technical Explanation
The MLLM-Bench benchmark is designed to comprehensively evaluate the performance of multi-modal large language models (LLMs) across a range of tasks and modalities. The benchmark is structured around a taxonomy that covers different categories of multi-modal capabilities, including visual reasoning, long-context understanding, and cross-lingual generalization.
Each task in the benchmark is designed to test a specific aspect of multi-modal understanding, with a focus on challenging the models in ways that go beyond traditional language-only benchmarks. For example, the VisualWebBench task evaluates a model's ability to reason about the contents of web pages that combine text and images.
The benchmark also includes the MILEBench and MegaVerse tasks, which assess long-context understanding and cross-lingual generalization, respectively. These tasks are designed to push the boundaries of what current multi-modal LLMs are capable of.
By providing a comprehensive and standardized evaluation framework, the MLLM-Bench aims to help researchers and practitioners better understand the strengths and weaknesses of different multi-modal LLM architectures and training approaches. This, in turn, can inform the development of more capable and versatile multi-modal AI systems.
Critical Analysis
The MLLM-Bench represents a valuable contribution to the field of multi-modal AI, as it addresses the need for a standardized and rigorous evaluation framework. By covering a diverse range of tasks and modalities, the benchmark can provide a more comprehensive assessment of a model's capabilities than traditional language-only benchmarks.
However, the paper acknowledges that the MLLM-Bench is not without its limitations. For example, the benchmark may not capture all the nuances of real-world multi-modal interactions, and the selection of tasks and datasets could be biased or incomplete. Additionally, the authors note that the evaluation of multi-modal LLMs is an inherently challenging problem, as these models often exhibit complex and unexpected behaviors that can be difficult to measure.
Further research is needed to address these limitations and continue advancing the state of the art in multi-modal AI evaluation. Potential areas for future work include exploring more diverse and realistic task scenarios, developing better evaluation metrics and methodologies, and investigating the factors that contribute to a model's multi-modal performance.
Conclusion
The MLLM-Bench represents an important step forward in the evaluation of multi-modal large language models. By providing a comprehensive and standardized benchmark, the researchers hope to help drive progress in this rapidly evolving field, ultimately leading to the development of more capable and versatile multi-modal AI systems. As the technology continues to advance, the insights gained from MLLM-Bench can inform future research and help shape the future of multi-modal AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yinuo Liu, Yaochen Wang, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, Lichao Sun
0
0
Multimodal Large Language Models (MLLMs) have gained significant attention recently, showing remarkable potential in artificial general intelligence. However, assessing the utility of MLLMs presents considerable challenges, primarily due to the absence of multimodal benchmarks that align with human preferences. Drawing inspiration from the concept of LLM-as-a-Judge within LLMs, this paper introduces a novel benchmark, termed MLLM-as-a-Judge, to assess the ability of MLLMs in assisting judges across diverse modalities, encompassing three distinct tasks: Scoring Evaluation, Pair Comparison, and Batch Ranking. Our study reveals that, while MLLMs demonstrate remarkable human-like discernment in Pair Comparison, there is a significant divergence from human preferences in Scoring Evaluation and Batch Ranking. Furthermore, a closer examination reveals persistent challenges in the judgment capacities of LLMs, including diverse biases, hallucinatory responses, and inconsistencies in judgment, even in advanced models such as GPT-4V. These findings emphasize the pressing need for enhancements and further research efforts to be undertaken before regarding MLLMs as fully reliable evaluators. In light of this, we advocate for additional efforts dedicated to supporting the continuous development within the domain of MLLM functioning as judges. The code and dataset are publicly available at our project homepage: url{https://mllm-judge.github.io/}.
6/12/2024

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
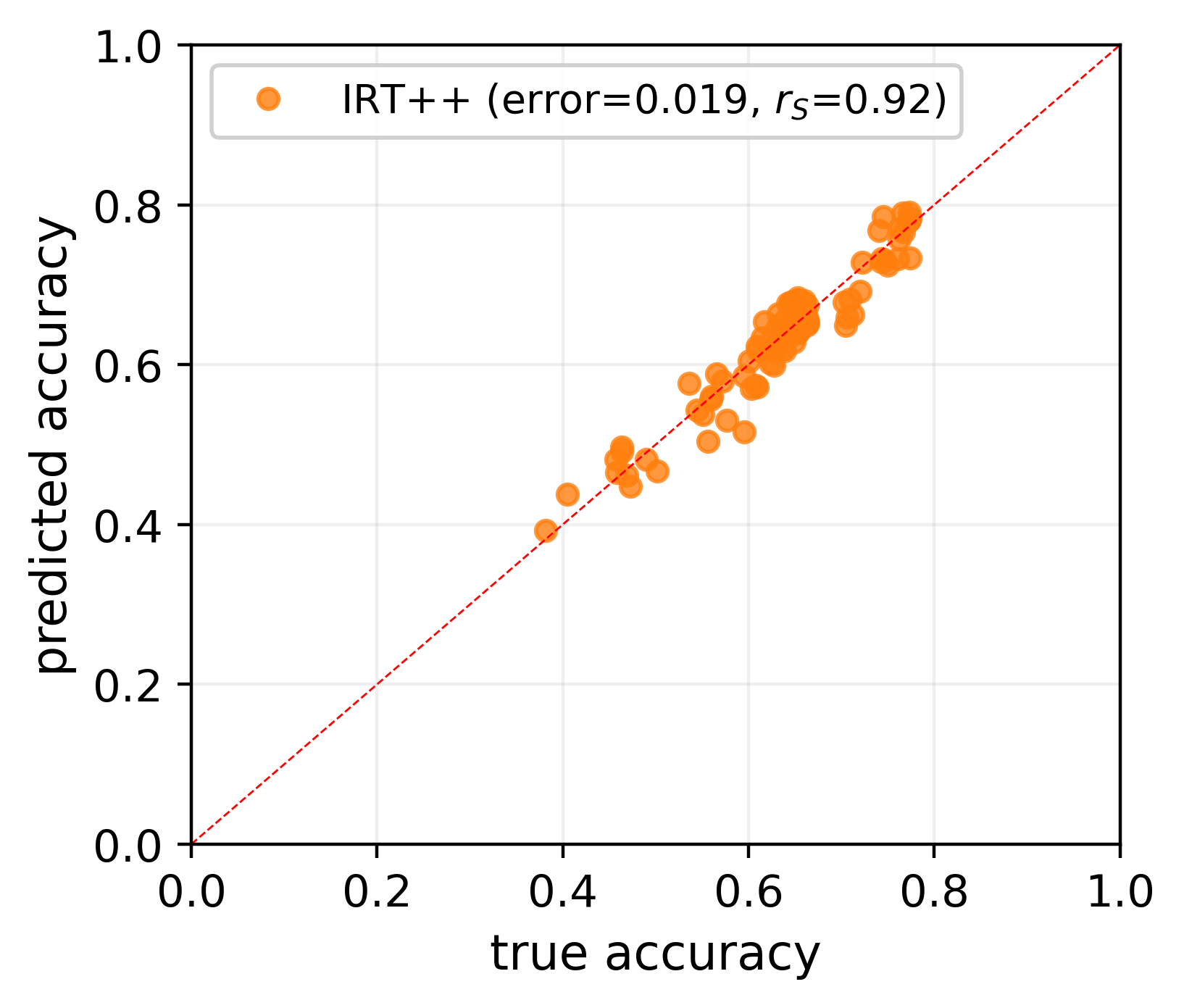
tinyBenchmarks: evaluating LLMs with fewer examples
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, Mikhail Yurochkin
0
0
The versatility of large language models (LLMs) led to the creation of diverse benchmarks that thoroughly test a variety of language models' abilities. These benchmarks consist of tens of thousands of examples making evaluation of LLMs very expensive. In this paper, we investigate strategies to reduce the number of evaluations needed to assess the performance of an LLM on several key benchmarks. For example, we show that to accurately estimate the performance of an LLM on MMLU, a popular multiple-choice QA benchmark consisting of 14K examples, it is sufficient to evaluate this LLM on 100 curated examples. We release evaluation tools and tiny versions of popular benchmarks: Open LLM Leaderboard, MMLU, HELM, and AlpacaEval 2.0. Our empirical analysis demonstrates that these tools and tiny benchmarks are sufficient to reliably and efficiently reproduce the original evaluation results.
5/28/2024

VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
Junpeng Liu, Yifan Song, Bill Yuchen Lin, Wai Lam, Graham Neubig, Yuanzhi Li, Xiang Yue
0
0
Multimodal Large Language models (MLLMs) have shown promise in web-related tasks, but evaluating their performance in the web domain remains a challenge due to the lack of comprehensive benchmarks. Existing benchmarks are either designed for general multimodal tasks, failing to capture the unique characteristics of web pages, or focus on end-to-end web agent tasks, unable to measure fine-grained abilities such as OCR, understanding, and grounding. In this paper, we introduce bench{}, a multimodal benchmark designed to assess the capabilities of MLLMs across a variety of web tasks. bench{} consists of seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude-3 series, and GPT-4V(ision) on bench{}, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe bench{} will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
4/10/2024