tinyBenchmarks: evaluating LLMs with fewer examples
2402.14992
0
0
Abstract
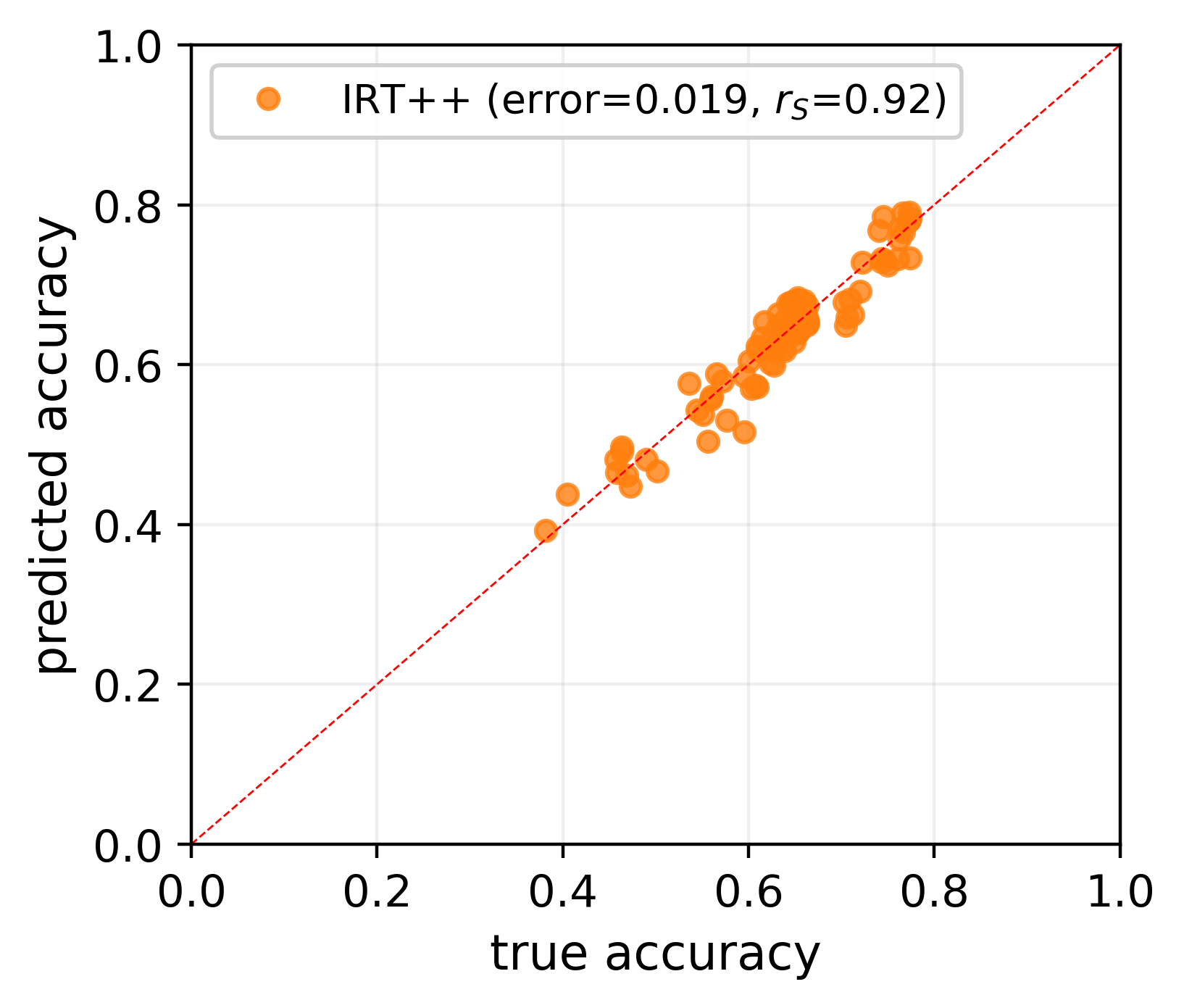
The versatility of large language models (LLMs) led to the creation of diverse benchmarks that thoroughly test a variety of language models' abilities. These benchmarks consist of tens of thousands of examples making evaluation of LLMs very expensive. In this paper, we investigate strategies to reduce the number of evaluations needed to assess the performance of an LLM on several key benchmarks. For example, we show that to accurately estimate the performance of an LLM on MMLU, a popular multiple-choice QA benchmark consisting of 14K examples, it is sufficient to evaluate this LLM on 100 curated examples. We release evaluation tools and tiny versions of popular benchmarks: Open LLM Leaderboard, MMLU, HELM, and AlpacaEval 2.0. Our empirical analysis demonstrates that these tools and tiny benchmarks are sufficient to reliably and efficiently reproduce the original evaluation results.
Create account to get full access
Overview
• This paper presents tinyBenchmarks, a new approach to efficiently evaluating the performance of large language models (LLMs) using fewer examples. • The authors argue that current benchmarking approaches are computationally expensive and may not accurately reflect real-world performance. • tinyBenchmarks aims to provide a more efficient and representative way to assess LLM capabilities with limited data.
Plain English Explanation
The paper introduces a new method called tinyBenchmarks for evaluating the capabilities of large language models (LLMs), which are a type of artificial intelligence system that can understand and generate human-like text.
Current approaches to testing LLMs often require a large number of examples, which can be computationally expensive and may not fully capture how the models would perform in real-world scenarios. The researchers behind tinyBenchmarks believe there is a better way to assess LLM capabilities using fewer examples, making the evaluation process more efficient and representative of real-world use cases.
The key idea behind tinyBenchmarks is to use a technique called Item Response Theory (IRT) to get more insights from a smaller number of test samples. IRT is a statistical method that can estimate a model's abilities based on how it performs on a few carefully selected tasks, rather than requiring a large, comprehensive set of tests.
By adopting this IRT-based approach, the researchers hope to provide a more practical and informative way to benchmark LLMs, which could lead to better model development and deployment decisions.
Technical Explanation
The paper introduces a new benchmarking framework called tinyBenchmarks that leverages Item Response Theory (IRT) to efficiently evaluate the performance of large language models (LLMs) using fewer examples.
The authors argue that current LLM benchmarking practices, which often rely on large, comprehensive test sets, are computationally expensive and may not accurately reflect real-world performance. tinyBenchmarks aims to address this by using IRT to extract more insights from a smaller number of carefully selected test samples.
IRT is a statistical modeling technique that can estimate a model's abilities based on how it performs on a few tasks, rather than requiring a large set of tests. By applying IRT to LLM benchmarking, the researchers hypothesize that they can obtain reliable performance estimates with fewer examples, making the evaluation process more efficient and representative of real-world use cases.
The paper describes the tinyBenchmarks framework, including details on the IRT-based model selection and performance estimation. The authors also present experiments comparing tinyBenchmarks to traditional benchmarking approaches, demonstrating the efficiency and efficacy of their proposed method.
Critical Analysis
The tinyBenchmarks approach presented in this paper offers a promising solution to the challenges of LLM benchmarking, such as the high computational cost and potential mismatch between test settings and real-world applications. The authors' use of Item Response Theory to extract more insights from fewer examples is a clever and well-justified strategy.
However, the paper does not deeply explore potential limitations or caveats of the tinyBenchmarks framework. For example, the authors do not discuss how the method might perform with different types of LLMs or tasks, or how it could be affected by factors like model size or training data composition. Additionally, the paper could benefit from a more thorough comparison to other efficient benchmarking approaches, such as MLLM-Bench or user-centric benchmarks, to better situate tinyBenchmarks within the broader landscape of LLM evaluation.
Further research exploring the robustness and generalizability of tinyBenchmarks, as well as potential biases or inconsistencies in its evaluation process, would help strengthen the case for its adoption. Additionally, investigating ways to quantify uncertainty in tinyBenchmarks' performance estimates could enhance its practical utility.
Conclusion
The tinyBenchmarks framework presented in this paper offers a promising approach to efficiently evaluating the capabilities of large language models (LLMs) using fewer examples. By leveraging Item Response Theory, the authors aim to provide a more practical and representative way to benchmark LLM performance, addressing the limitations of current computationally expensive and potentially misaligned benchmarking practices.
While the paper demonstrates the potential of the tinyBenchmarks method, further research is needed to fully explore its robustness, generalizability, and potential biases. Nonetheless, this work represents an important step towards more efficient and insightful LLM evaluation, which could ultimately lead to the development and deployment of more capable and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Examining the robustness of LLM evaluation to the distributional assumptions of benchmarks
Melissa Ailem, Katerina Marazopoulou, Charlotte Siska, James Bono
0
0
Benchmarks have emerged as the central approach for evaluating Large Language Models (LLMs). The research community often relies on a model's average performance across the test prompts of a benchmark to evaluate the model's performance. This is consistent with the assumption that the test prompts within a benchmark represent a random sample from a real-world distribution of interest. We note that this is generally not the case; instead, we hold that the distribution of interest varies according to the specific use case. We find that (1) the correlation in model performance across test prompts is non-random, (2) accounting for correlations across test prompts can change model rankings on major benchmarks, (3) explanatory factors for these correlations include semantic similarity and common LLM failure points.
6/7/2024

MLLM-Bench: Evaluating Multimodal LLMs with Per-sample Criteria
Wentao Ge, Shunian Chen, Guiming Hardy Chen, Zhihong Chen, Junying Chen, Shuo Yan, Chenghao Zhu, Ziyue Lin, Wenya Xie, Xinyi Zhang, Yichen Chai, Xiaoyu Liu, Dingjie Song, Xidong Wang, Anningzhe Gao, Zhiyi Zhang, Jianquan Li, Xiang Wan, Benyou Wang
0
0
Multimodal large language models (MLLMs) (e.g., GPT-4V, LLaVA, and Claude-3) have broadened the scope of AI applications. Yet, evaluating their performance presents a significant challenge owing to the inherently subjective nature of tasks that do not yield clear-cut solutions especially for those open-ended queries. Existing automatic evaluation methodologies are mainly limited in evaluating objective queries without considering real-world user experiences, inadequately addressing the nuances of creative and associative multimodal tasks. In our paper, we propose a new evaluation paradigm for MLLMs, which is evaluating MLLMs with textit{per-sample criteria} using potent MLLM as the judge. To validate the feasibility and effectiveness of this paradigm, we design a benchmark, dubbed textit{MLLM-Bench}, with the evaluation samples across six critical levels following the revised Bloom's Taxonomy with the ethical consideration. We benchmark 21 popular MLLMs in a pairwise-comparison fashion, showing diverse performance across models. Moreover, the validity of our benchmark manifests itself in reaching 88.02% agreement with human evaluation. We contend that the proposed paradigm explores the potential of MLLMs as effective evaluation tools with the help of per-sample criteria, and that MLLM-Bench will serve as a catalyst for encouraging the development of user-centric MLLMs tailored to real-world applications. Our benchmark data, online leaderboard and submission entry are at https://mllm-bench.llmzoo.com.
4/30/2024

A User-Centric Benchmark for Evaluating Large Language Models
Jiayin Wang, Fengran Mo, Weizhi Ma, Peijie Sun, Min Zhang, Jian-Yun Nie
0
0
Large Language Models (LLMs) are essential tools to collaborate with users on different tasks. Evaluating their performance to serve users' needs in real-world scenarios is important. While many benchmarks have been created, they mainly focus on specific predefined model abilities. Few have covered the intended utilization of LLMs by real users. To address this oversight, we propose benchmarking LLMs from a user perspective in both dataset construction and evaluation designs. We first collect 1846 real-world use cases with 15 LLMs from a user study with 712 participants from 23 countries. These self-reported cases form the User Reported Scenarios(URS) dataset with a categorization of 7 user intents. Secondly, on this authentic multi-cultural dataset, we benchmark 10 LLM services on their efficacy in satisfying user needs. Thirdly, we show that our benchmark scores align well with user-reported experience in LLM interactions across diverse intents, both of which emphasize the overlook of subjective scenarios. In conclusion, our study proposes to benchmark LLMs from a user-centric perspective, aiming to facilitate evaluations that better reflect real user needs. The benchmark dataset and code are available at https://github.com/Alice1998/URS.
4/24/2024
MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Huan Wang, Caiming Xiong, Silvio Savarese
0
0
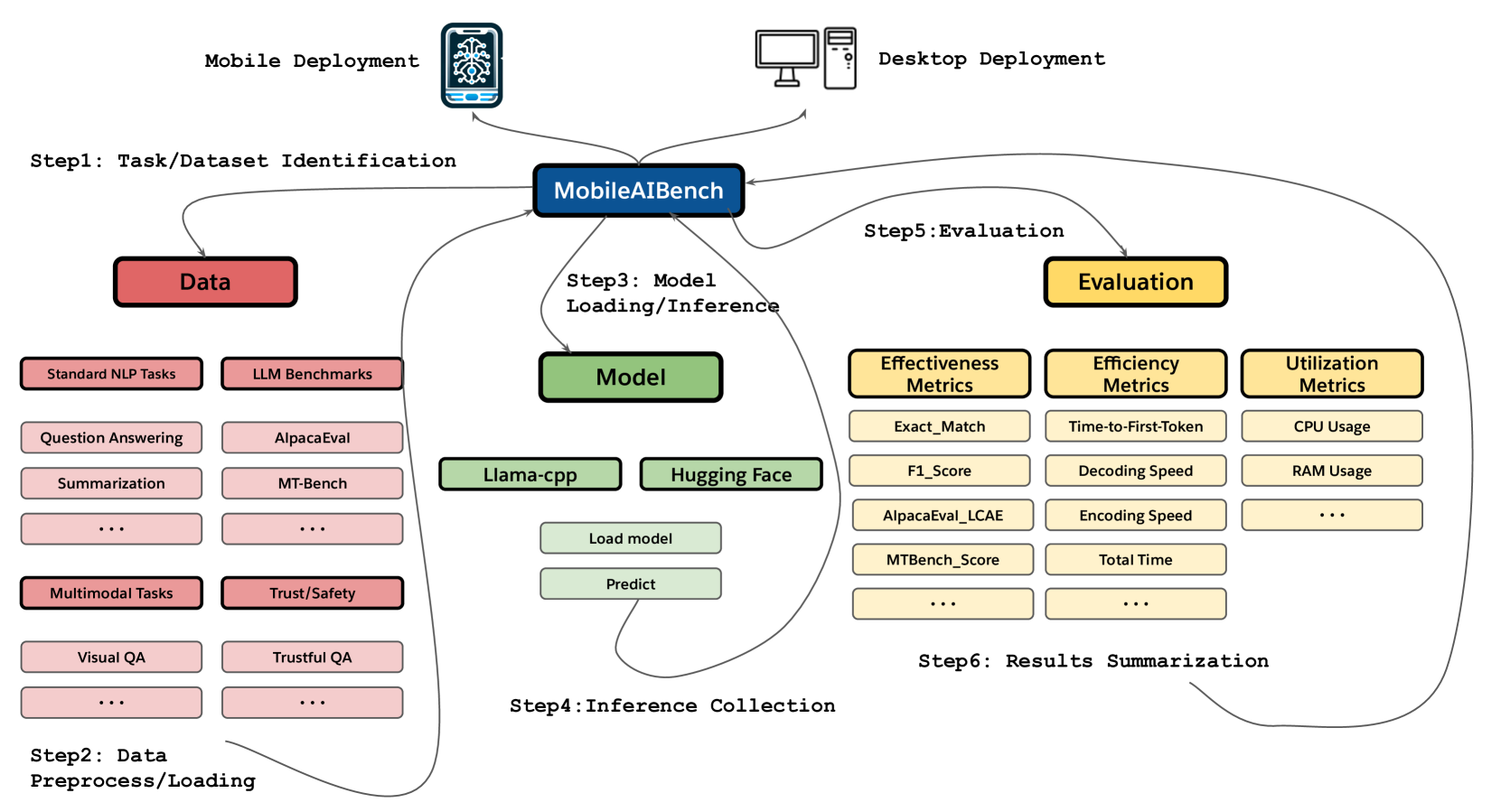
The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
6/18/2024