MLR-Copilot: Autonomous Machine Learning Research based on Large Language Models Agents

0

Sign in to get full access
Overview
- Introduces a framework called "MLR-Copilot" for autonomous machine learning research using large language models
- Describes how MLR-Copilot uses multiple AI agents to collaborate on the research process, from idea generation to experiment design and analysis
- Presents the results of experiments demonstrating the capabilities of the MLR-Copilot system
Plain English Explanation
The paper presents a new approach to machine learning research called MLR-Copilot, which uses a team of AI agents to automate various aspects of the research process. The key idea is to leverage the capabilities of large language models to enable these agents to perform tasks like brainstorming research ideas, designing experiments, and analyzing results.
The MLR-Copilot framework consists of several specialized agents, each with a particular role to play in the research workflow. For example, one agent might be responsible for generating new research ideas by exploring the existing literature and identifying promising avenues for exploration. Another agent might focus on designing experiments to test these ideas, while a third agent could analyze the results and draw conclusions.
By coordinating the efforts of these agents, the MLR-Copilot system is able to rapidly iterate through the research process, exploring multiple ideas and conducting experiments in parallel. This allows the system to uncover insights and make discoveries that might be difficult for a human researcher to achieve on their own.
The paper presents the results of several experiments demonstrating the capabilities of the MLR-Copilot system, showing how it can generate novel research ideas, design effective experiments, and draw meaningful conclusions from the data.
Technical Explanation
The MLR-Copilot framework is built on a multi-agent architecture, where each agent is responsible for a specific task in the research process. The agents communicate and collaborate using large language models, which allow them to understand natural language, generate text, and reason about complex concepts.
The key components of the MLR-Copilot system include:
-
Idea Generation Agent: This agent is tasked with generating novel research ideas by exploring the existing literature, identifying gaps or unexplored areas, and proposing new hypotheses or experiments.
-
Experiment Design Agent: This agent is responsible for designing experiments to test the ideas generated by the Idea Generation Agent. This includes selecting appropriate datasets, defining experimental protocols, and specifying the necessary infrastructure and resources.
-
Analysis Agent: The Analysis Agent is tasked with interpreting the results of the experiments conducted by the Experiment Design Agent. This includes identifying patterns, drawing conclusions, and suggesting next steps for the research.
-
Coordination Agent: The Coordination Agent oversees the entire research workflow, ensuring that the various agents are working together effectively and that the overall research process is progressing as planned.
The agents in the MLR-Copilot system communicate using a shared knowledge base, which stores information about the research domain, experimental results, and other relevant data. The agents can query this knowledge base, update it with new information, and use it to inform their decision-making and generate new ideas.
The paper presents the results of several experiments demonstrating the capabilities of the MLR-Copilot system. These experiments show how the system can generate novel research ideas, design effective experiments, and draw meaningful conclusions from the data, often outperforming human researchers in terms of speed and efficiency.
Critical Analysis
The MLR-Copilot framework presented in this paper represents a promising approach to automating the machine learning research process. By leveraging the capabilities of large language models and multi-agent architectures, the system is able to rapidly explore a wide range of research ideas and conduct experiments in parallel, potentially uncovering insights that would be difficult for human researchers to discover on their own.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the current implementation of the MLR-Copilot system relies heavily on the quality and breadth of the underlying knowledge base, and that further work is needed to ensure that this knowledge base is comprehensive and up-to-date.
Additionally, the paper does not address the potential ethical concerns associated with autonomous research systems, such as the potential for bias, the difficulty of interpreting the system's decision-making process, and the potential for these systems to be misused or abused.
Overall, the MLR-Copilot framework represents an exciting step forward in the field of automated machine learning research. However, continued research and development will be needed to address the challenges and limitations identified in this paper, and to ensure that these systems are developed and deployed in a responsible and ethical manner.
Conclusion
The MLR-Copilot framework presented in this paper represents a novel approach to automating the machine learning research process using a team of specialized AI agents. By leveraging the capabilities of large language models, the system is able to rapidly generate research ideas, design experiments, and analyze results, potentially uncovering insights that would be difficult for human researchers to discover on their own.
While the paper demonstrates the promising capabilities of the MLR-Copilot system, it also highlights several areas for further research and development, including the need to address ethical concerns and ensure the robustness and reliability of the underlying knowledge base.
Overall, the MLR-Copilot framework represents an exciting step forward in the field of autonomous machine learning research, and its continued development and refinement could have significant implications for the pace and direction of scientific discovery in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MLR-Copilot: Autonomous Machine Learning Research based on Large Language Models Agents
Ruochen Li, Teerth Patel, Qingyun Wang, Xinya Du
Machine learning research, crucial for technological advancements and innovation, often faces significant challenges due to its inherent complexity, slow pace of experimentation, and the necessity for specialized expertise. Motivated by this, we present a new systematic framework, autonomous Machine Learning Research with large language models (MLR-Copilot), designed to enhance machine learning research productivity through the automatic generation and implementation of research ideas using Large Language Model (LLM) agents. The framework consists of three phases: research idea generation, experiment implementation, and implementation execution. First, existing research papers are used to generate hypotheses and experimental plans vis IdeaAgent powered by LLMs. Next, the implementation generation phase translates these plans into executables with ExperimentAgent. This phase leverages retrieved prototype code and optionally retrieves candidate models and data. Finally, the execution phase, also managed by ExperimentAgent, involves running experiments with mechanisms for human feedback and iterative debugging to enhance the likelihood of achieving executable research outcomes. We evaluate our framework on five machine learning research tasks and the experimental results show the framework's potential to facilitate the research progress and innovations.
Read more9/4/2024
💬
0
A Survey on Large Language Model based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen
Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and thus makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of web knowledge, large language models (LLMs) have demonstrated remarkable potential in achieving human-level intelligence. This has sparked an upsurge in studies investigating LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of the field of LLM-based autonomous agents from a holistic perspective. More specifically, we first discuss the construction of LLM-based autonomous agents, for which we propose a unified framework that encompasses a majority of the previous work. Then, we present a comprehensive overview of the diverse applications of LLM-based autonomous agents in the fields of social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field. To keep track of this field and continuously update our survey, we maintain a repository of relevant references at https://github.com/Paitesanshi/LLM-Agent-Survey.
Read more4/5/2024
0
Exploring Autonomous Agents through the Lens of Large Language Models: A Review
Saikat Barua
Large Language Models (LLMs) are transforming artificial intelligence, enabling autonomous agents to perform diverse tasks across various domains. These agents, proficient in human-like text comprehension and generation, have the potential to revolutionize sectors from customer service to healthcare. However, they face challenges such as multimodality, human value alignment, hallucinations, and evaluation. Techniques like prompting, reasoning, tool utilization, and in-context learning are being explored to enhance their capabilities. Evaluation platforms like AgentBench, WebArena, and ToolLLM provide robust methods for assessing these agents in complex scenarios. These advancements are leading to the development of more resilient and capable autonomous agents, anticipated to become integral in our digital lives, assisting in tasks from email responses to disease diagnosis. The future of AI, with LLMs at the forefront, is promising.
Read more4/9/2024
0
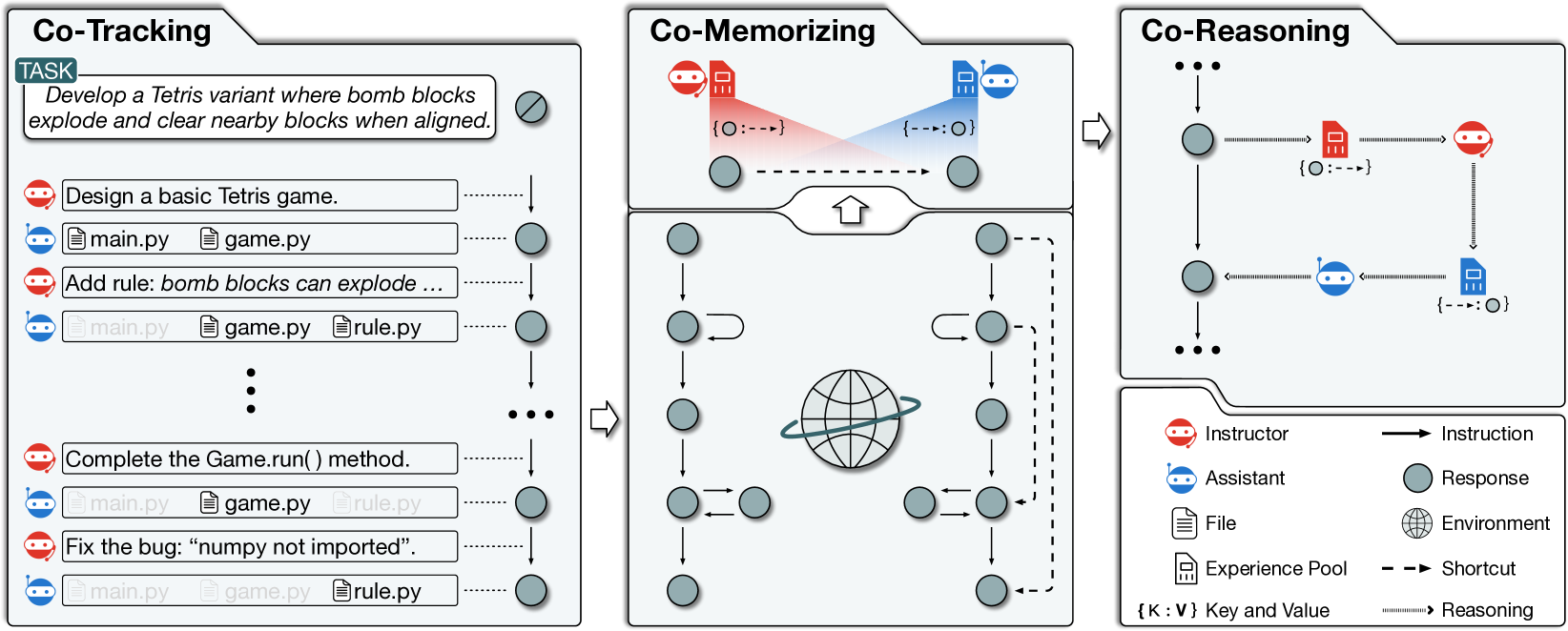
Experiential Co-Learning of Software-Developing Agents
Chen Qian, Yufan Dang, Jiahao Li, Wei Liu, Zihao Xie, Yifei Wang, Weize Chen, Cheng Yang, Xin Cong, Xiaoyin Che, Zhiyuan Liu, Maosong Sun
Recent advancements in large language models (LLMs) have brought significant changes to various domains, especially through LLM-driven autonomous agents. A representative scenario is in software development, where LLM agents demonstrate efficient collaboration, task division, and assurance of software quality, markedly reducing the need for manual involvement. However, these agents frequently perform a variety of tasks independently, without benefiting from past experiences, which leads to repeated mistakes and inefficient attempts in multi-step task execution. To this end, we introduce Experiential Co-Learning, a novel LLM-agent learning framework in which instructor and assistant agents gather shortcut-oriented experiences from their historical trajectories and use these past experiences for future task execution. The extensive experiments demonstrate that the framework enables agents to tackle unseen software-developing tasks more effectively. We anticipate that our insights will guide LLM agents towards enhanced autonomy and contribute to their evolutionary growth in cooperative learning. The code and data are available at https://github.com/OpenBMB/ChatDev.
Read more6/6/2024