ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models
2404.07738
123
0
🛸
Abstract
Scientific Research, vital for improving human life, is hindered by its inherent complexity, slow pace, and the need for specialized experts. To enhance its productivity, we propose a ResearchAgent, a large language model-powered research idea writing agent, which automatically generates problems, methods, and experiment designs while iteratively refining them based on scientific literature. Specifically, starting with a core paper as the primary focus to generate ideas, our ResearchAgent is augmented not only with relevant publications through connecting information over an academic graph but also entities retrieved from an entity-centric knowledge store based on their underlying concepts, mined and shared across numerous papers. In addition, mirroring the human approach to iteratively improving ideas with peer discussions, we leverage multiple ReviewingAgents that provide reviews and feedback iteratively. Further, they are instantiated with human preference-aligned large language models whose criteria for evaluation are derived from actual human judgments. We experimentally validate our ResearchAgent on scientific publications across multiple disciplines, showcasing its effectiveness in generating novel, clear, and valid research ideas based on human and model-based evaluation results.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes a ResearchAgent, a large language model-powered research idea writing agent
- Automatically generates problems, methods, and experiment designs, refining them based on scientific literature
- Leverages an academic graph and entity-centric knowledge store to connect relevant publications and entities
- Utilizes multiple ReviewingAgents to provide iterative feedback, based on human preference-aligned large language models
- Experimentally validates the ResearchAgent's effectiveness in generating novel, clear, and valid research ideas
Plain English Explanation
The paper discusses a ResearchAgent - a system that uses large language models to automatically generate and refine research ideas. The key idea is to start with a core paper and then expand on it by connecting relevant publications and entities from a knowledge base. This allows the system to come up with new problems, methods, and experiment designs.
To mirror the human approach of improving ideas through peer discussions, the paper also introduces ReviewingAgents that provide iterative feedback. These ReviewingAgents are based on large language models that have been trained to evaluate research ideas in a way that aligns with human preferences.
The researchers experimentally validated the ResearchAgent on publications across multiple disciplines and found that it can generate novel, clear, and valid research ideas, as assessed by both human and model-based evaluations. This suggests that such AI-powered research assistants have the potential to enhance the productivity and creativity of the scientific research process.
Technical Explanation
The paper proposes a ResearchAgent that leverages large language models to automatically generate and refine research ideas. The system starts with a core paper as the primary focus and then expands on it by connecting relevant publications through an academic graph. It also retrieves relevant entities from an entity-centric knowledge store based on their underlying concepts, which are mined and shared across numerous papers.
To mimic the human approach of iteratively improving ideas through peer discussions, the paper introduces ReviewingAgents that provide feedback on the generated research ideas. These ReviewingAgents are instantiated with human preference-aligned large language models, whose evaluation criteria are derived from actual human judgments.
The researchers validate the ResearchAgent experimentally on scientific publications across multiple disciplines. They assess the effectiveness of the system in generating novel, clear, and valid research ideas, using both human and model-based evaluation methods.
Critical Analysis
The paper presents a promising approach to enhancing the productivity and creativity of scientific research through the use of large language model-based research assistants. However, it is important to consider the potential limitations and areas for further research.
One potential concern is the reliability and bias of the large language models used in the ReviewingAgents. While the researchers have aligned the models with human preferences, there may still be inherent biases or limitations in the underlying language models that could influence the feedback and evaluation of research ideas.
Additionally, the paper focuses on generating novel ideas, but it does not address the potential challenges of translating these ideas into feasible and impactful research projects. Further work may be needed to explore how the ResearchAgent could be integrated into the overall research workflow, including factors such as funding, resource allocation, and real-world application.
Finally, the paper does not discuss the potential ethical implications of such large language model-based game agents in the context of scientific research. Careful consideration should be given to ensuring that the use of these systems does not introduce unintended biases, misuse of resources, or other negative consequences.
Conclusion
The proposed ResearchAgent represents a significant step forward in the use of large language model-based research assistants to enhance the productivity and creativity of scientific research. By automatically generating and refining research ideas, the system has the potential to accelerate the pace of scientific discovery and unlock new avenues of exploration.
While the paper presents promising results, further research is needed to address the potential limitations and ethical considerations of such systems. As the field of language model evolution continues to advance, the integration of large language models into the scientific research process may become an increasingly valuable tool for researchers and institutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
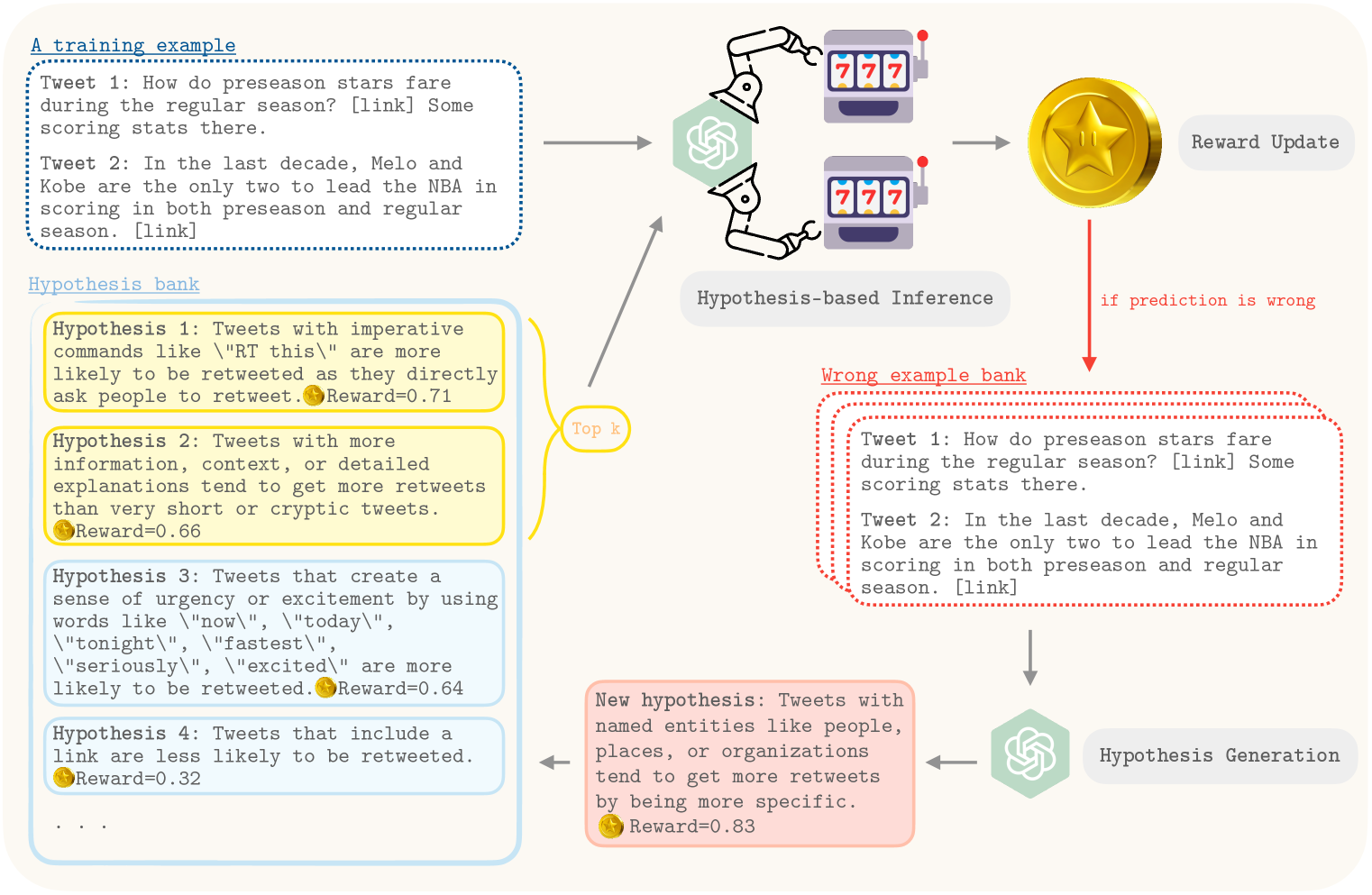
Hypothesis Generation with Large Language Models
Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, Chenhao Tan
0
0
Effective generation of novel hypotheses is instrumental to scientific progress. So far, researchers have been the main powerhouse behind hypothesis generation by painstaking data analysis and thinking (also known as the Eureka moment). In this paper, we examine the potential of large language models (LLMs) to generate hypotheses. We focus on hypothesis generation based on data (i.e., labeled examples). To enable LLMs to handle arbitrarily long contexts, we generate initial hypotheses from a small number of examples and then update them iteratively to improve the quality of hypotheses. Inspired by multi-armed bandits, we design a reward function to inform the exploitation-exploration tradeoff in the update process. Our algorithm is able to generate hypotheses that enable much better predictive performance than few-shot prompting in classification tasks, improving accuracy by 31.7% on a synthetic dataset and by 13.9%, 3.3% and, 24.9% on three real-world datasets. We also outperform supervised learning by 12.8% and 11.2% on two challenging real-world datasets. Furthermore, we find that the generated hypotheses not only corroborate human-verified theories but also uncover new insights for the tasks.
4/9/2024
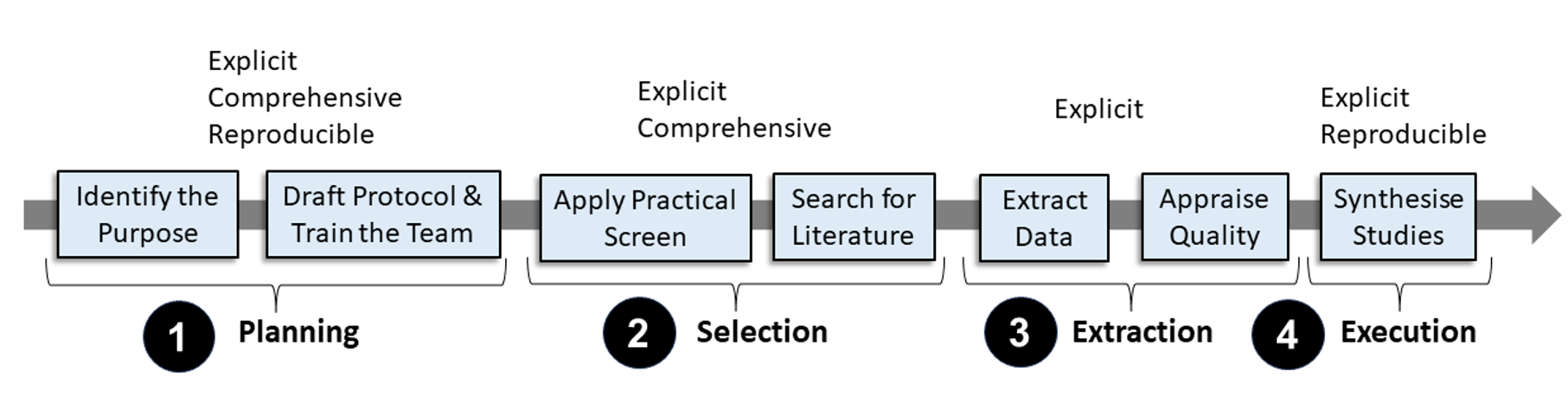
Automating Research Synthesis with Domain-Specific Large Language Model Fine-Tuning
Teo Susnjak, Peter Hwang, Napoleon H. Reyes, Andre L. C. Barczak, Timothy R. McIntosh, Surangika Ranathunga
0
0
This research pioneers the use of fine-tuned Large Language Models (LLMs) to automate Systematic Literature Reviews (SLRs), presenting a significant and novel contribution in integrating AI to enhance academic research methodologies. Our study employed the latest fine-tuning methodologies together with open-sourced LLMs, and demonstrated a practical and efficient approach to automating the final execution stages of an SLR process that involves knowledge synthesis. The results maintained high fidelity in factual accuracy in LLM responses, and were validated through the replication of an existing PRISMA-conforming SLR. Our research proposed solutions for mitigating LLM hallucination and proposed mechanisms for tracking LLM responses to their sources of information, thus demonstrating how this approach can meet the rigorous demands of scholarly research. The findings ultimately confirmed the potential of fine-tuned LLMs in streamlining various labor-intensive processes of conducting literature reviews. Given the potential of this approach and its applicability across all research domains, this foundational study also advocated for updating PRISMA reporting guidelines to incorporate AI-driven processes, ensuring methodological transparency and reliability in future SLRs. This study broadens the appeal of AI-enhanced tools across various academic and research fields, setting a new standard for conducting comprehensive and accurate literature reviews with more efficiency in the face of ever-increasing volumes of academic studies.
4/16/2024
👀
REASONS: A benchmark for REtrieval and Automated citationS Of scieNtific Sentences using Public and Proprietary LLMs
Deepa Tilwani, Yash Saxena, Ali Mohammadi, Edward Raff, Amit Sheth, Srinivasan Parthasarathy, Manas Gaur
0
0
Automatic citation generation for sentences in a document or report is paramount for intelligence analysts, cybersecurity, news agencies, and education personnel. In this research, we investigate whether large language models (LLMs) are capable of generating references based on two forms of sentence queries: (a) Direct Queries, LLMs are asked to provide author names of the given research article, and (b) Indirect Queries, LLMs are asked to provide the title of a mentioned article when given a sentence from a different article. To demonstrate where LLM stands in this task, we introduce a large dataset called REASONS comprising abstracts of the 12 most popular domains of scientific research on arXiv. From around 20K research articles, we make the following deductions on public and proprietary LLMs: (a) State-of-the-art, often called anthropomorphic GPT-4 and GPT-3.5, suffers from high pass percentage (PP) to minimize the hallucination rate (HR). When tested with Perplexity.ai (7B), they unexpectedly made more errors; (b) Augmenting relevant metadata lowered the PP and gave the lowest HR; (c) Advance retrieval-augmented generation (RAG) using Mistral demonstrates consistent and robust citation support on indirect queries and matched performance to GPT-3.5 and GPT-4. The HR across all domains and models decreased by an average of 41.93%, and the PP was reduced to 0% in most cases. In terms of generation quality, the average F1 Score and BLEU were 68.09% and 57.51%, respectively; (d) Testing with adversarial samples showed that LLMs, including the Advance RAG Mistral, struggle to understand context, but the extent of this issue was small in Mistral and GPT-4-Preview. Our study contributes valuable insights into the reliability of RAG for automated citation generation tasks.
5/10/2024
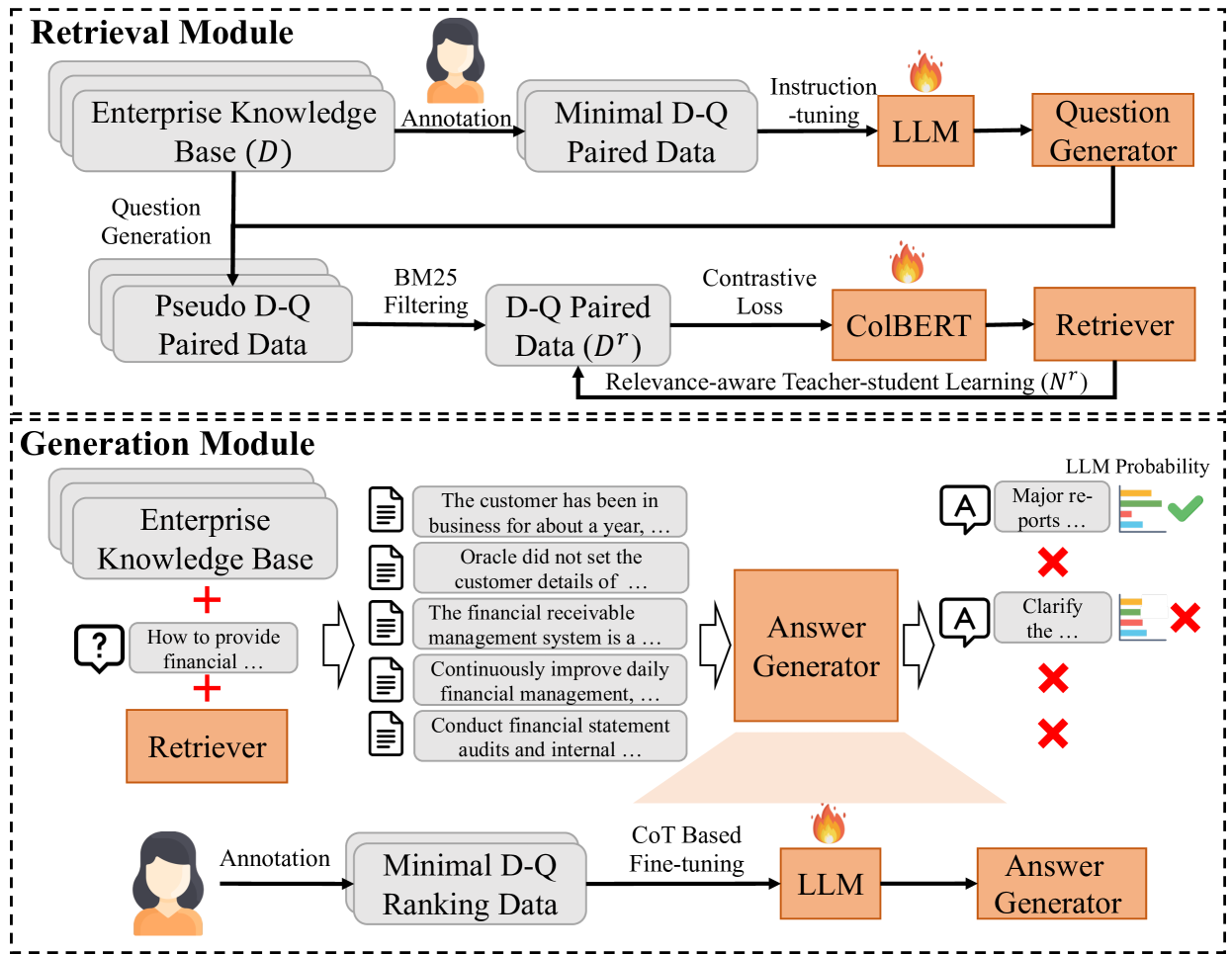
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024