MM-Conv: A Multi-modal Conversational Dataset for Virtual Humans

0

Sign in to get full access
Overview
- The paper presents a new multi-modal conversational dataset called MM-Conv, which was created for virtual human applications.
- The dataset includes audio, video, motion capture, and language data from human-to-human conversations involving gestures and interactions with a physical scene.
- The goal is to enable the development of more realistic and engaging virtual humans that can participate in natural multi-modal conversations.
Plain English Explanation
The researchers have created a new dataset called MM-Conv that contains information from real human conversations. This includes audio, video, motion capture data (to track body movements), and the actual words that were spoken. The conversations involved people talking to each other and also interacting with physical objects in the room.
The main purpose of this dataset is to help researchers and developers create more lifelike virtual humans that can have natural conversations. Virtual humans are computer-generated characters that can interact with people, and this dataset provides a lot of realistic examples to train them on.
By having access to all the different types of data - the speech, the visuals, the body movements - the hope is that virtual humans will be able to have more engaging and authentic conversations, just like real people do. This can be used for things like virtual assistants, interactive avatars, or even digital characters in movies and games.
Overall, the MM-Conv dataset aims to advance the state of the art in multi-modal interaction for virtual humans, making them seem more natural and lifelike when they talk and move.
Technical Explanation
The MM-Conv dataset was collected by having pairs of human participants engage in freeform conversations while interacting with a physical scene. This scene contained various objects that the participants could manipulate and refer to during their discussions.
The dataset captures multi-modal data including:
- Audio recordings of the spoken dialogue
- Video footage of the participants' facial expressions and body movements
- Motion capture data tracking the 3D positions of the participants' joints and limbs
- Transcripts of the spoken language
By providing all these modalities - audio, video, motion, and text - the researchers aim to enable the development of virtual human systems that can engage in natural, multi-modal conversations. This could involve things like generating realistic 3D talking heads, understanding and responding to gestures, and reasoning about the physical context.
The dataset contains over 6 hours of conversation data from 40 participants, making it one of the largest publicly available multi-modal conversational datasets to date. The researchers hope that this resource will catalyze further progress in the field of multi-modal AI and interactive virtual characters.
Critical Analysis
The MM-Conv dataset represents an important contribution to the field of multi-modal interaction for virtual humans. By providing rich, real-world data spanning speech, vision, and physical interactions, it enables the training of more sophisticated AI systems.
However, the paper does acknowledge some limitations of the dataset. For example, the conversations are limited to a specific task-oriented scenario involving a physical scene. It remains to be seen how well models trained on this data will generalize to more open-ended, free-flowing conversations.
Additionally, the dataset only covers a relatively small number of participants. Expanding the diversity of speakers and interaction styles would be valuable to ensure the resulting virtual human systems are robust and inclusive.
Overall, the MM-Conv dataset is a valuable resource that should accelerate progress in multi-modal conversational AI. But continued work is needed to further enhance the realism and generalization capabilities of virtual human technologies.
Conclusion
The MM-Conv dataset provides a rich source of real-world data to support the development of more natural and engaging virtual humans. By capturing multi-modal interactions involving speech, gestures, and physical context, it enables the training of AI systems that can participate in lifelike conversations.
This dataset represents an important step forward in the quest to create virtual humans that can interact with people in a truly seamless and intuitive way. As the field of multi-modal AI continues to advance, resources like MM-Conv will be crucial for pushing the boundaries of what is possible in virtual characters and interactive experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!MM-Conv: A Multi-modal Conversational Dataset for Virtual Humans
Anna Deichler, Jim O'Regan, Jonas Beskow
In this paper, we present a novel dataset captured using a VR headset to record conversations between participants within a physics simulator (AI2-THOR). Our primary objective is to extend the field of co-speech gesture generation by incorporating rich contextual information within referential settings. Participants engaged in various conversational scenarios, all based on referential communication tasks. The dataset provides a rich set of multimodal recordings such as motion capture, speech, gaze, and scene graphs. This comprehensive dataset aims to enhance the understanding and development of gesture generation models in 3D scenes by providing diverse and contextually rich data.
Read more10/2/2024

0
MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset
Kim Sung-Bin, Lee Chae-Yeon, Gihun Son, Oh Hyun-Bin, Janghoon Ju, Suekyeong Nam, Tae-Hyun Oh
Recent studies in speech-driven 3D talking head generation have achieved convincing results in verbal articulations. However, generating accurate lip-syncs degrades when applied to input speech in other languages, possibly due to the lack of datasets covering a broad spectrum of facial movements across languages. In this work, we introduce a novel task to generate 3D talking heads from speeches of diverse languages. We collect a new multilingual 2D video dataset comprising over 420 hours of talking videos in 20 languages. With our proposed dataset, we present a multilingually enhanced model that incorporates language-specific style embeddings, enabling it to capture the unique mouth movements associated with each language. Additionally, we present a metric for assessing lip-sync accuracy in multilingual settings. We demonstrate that training a 3D talking head model with our proposed dataset significantly enhances its multilingual performance. Codes and datasets are available at https://multi-talk.github.io/.
Read more6/21/2024
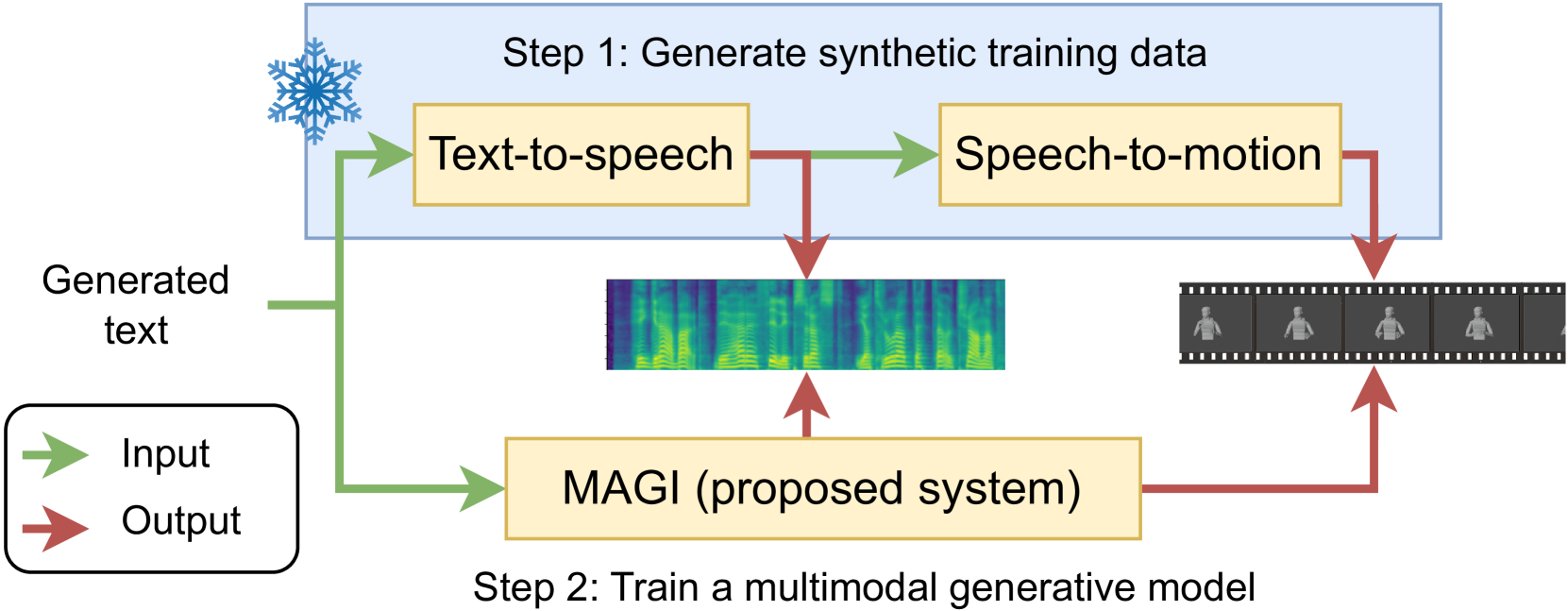
0
Fake it to make it: Using synthetic data to remedy the data shortage in joint multimodal speech-and-gesture synthesis
Shivam Mehta, Anna Deichler, Jim O'Regan, Birger Moell, Jonas Beskow, Gustav Eje Henter, Simon Alexanderson
Although humans engaged in face-to-face conversation simultaneously communicate both verbally and non-verbally, methods for joint and unified synthesis of speech audio and co-speech 3D gesture motion from text are a new and emerging field. These technologies hold great promise for more human-like, efficient, expressive, and robust synthetic communication, but are currently held back by the lack of suitably large datasets, as existing methods are trained on parallel data from all constituent modalities. Inspired by student-teacher methods, we propose a straightforward solution to the data shortage, by simply synthesising additional training material. Specifically, we use unimodal synthesis models trained on large datasets to create multimodal (but synthetic) parallel training data, and then pre-train a joint synthesis model on that material. In addition, we propose a new synthesis architecture that adds better and more controllable prosody modelling to the state-of-the-art method in the field. Our results confirm that pre-training on large amounts of synthetic data improves the quality of both the speech and the motion synthesised by the multimodal model, with the proposed architecture yielding further benefits when pre-trained on the synthetic data. See https://shivammehta25.github.io/MAGI/ for example output.
Read more5/1/2024

0
MMScan: A Multi-Modal 3D Scene Dataset with Hierarchical Grounded Language Annotations
Ruiyuan Lyu, Tai Wang, Jingli Lin, Shuai Yang, Xiaohan Mao, Yilun Chen, Runsen Xu, Haifeng Huang, Chenming Zhu, Dahua Lin, Jiangmiao Pang
With the emergence of LLMs and their integration with other data modalities, multi-modal 3D perception attracts more attention due to its connectivity to the physical world and makes rapid progress. However, limited by existing datasets, previous works mainly focus on understanding object properties or inter-object spatial relationships in a 3D scene. To tackle this problem, this paper builds the first largest ever multi-modal 3D scene dataset and benchmark with hierarchical grounded language annotations, MMScan. It is constructed based on a top-down logic, from region to object level, from a single target to inter-target relationships, covering holistic aspects of spatial and attribute understanding. The overall pipeline incorporates powerful VLMs via carefully designed prompts to initialize the annotations efficiently and further involve humans' correction in the loop to ensure the annotations are natural, correct, and comprehensive. Built upon existing 3D scanning data, the resulting multi-modal 3D dataset encompasses 1.4M meta-annotated captions on 109k objects and 7.7k regions as well as over 3.04M diverse samples for 3D visual grounding and question-answering benchmarks. We evaluate representative baselines on our benchmarks, analyze their capabilities in different aspects, and showcase the key problems to be addressed in the future. Furthermore, we use this high-quality dataset to train state-of-the-art 3D visual grounding and LLMs and obtain remarkable performance improvement both on existing benchmarks and in-the-wild evaluation. Codes, datasets, and benchmarks will be available at https://github.com/OpenRobotLab/EmbodiedScan.
Read more6/14/2024