Fake it to make it: Using synthetic data to remedy the data shortage in joint multimodal speech-and-gesture synthesis

0
Sign in to get full access
Overview
- Addresses the data shortage in joint multimodal speech-and-gesture synthesis
- Proposes using synthetic data to train models and improve performance
- Demonstrates the effectiveness of synthetic data for improving speech-and-gesture synthesis
Plain English Explanation
The paper discusses the challenge of creating artificial intelligence (AI) systems that can generate realistic speech and accompanying body movements, like hand gestures. This is known as "joint multimodal speech-and-gesture synthesis." However, one of the main obstacles is the lack of high-quality training data - real-world examples of people speaking and gesturing at the same time.
To overcome this data shortage, the researchers explored using synthetic data - artificially generated examples of speech and gestures. They developed a system to create these synthetic samples and used them to train a machine learning model for speech-and-gesture synthesis. The results showed that the model trained on the synthetic data performed better than one trained only on limited real-world data.
The key insight is that by generating large amounts of high-quality synthetic data, the researchers were able to supplement the scarce real-world training examples. This allowed the model to learn the patterns and relationships between speech and gesture more effectively, leading to more natural and convincing synthesized outputs.
Technical Explanation
The paper presents a novel approach to address the data shortage in joint multimodal speech-and-gesture synthesis. The researchers developed a framework to generate high-quality synthetic data, which they then used to train a machine learning model for this task.
The synthetic data generation process involved several steps:
- Extracting speech and gesture features from real-world examples
- Learning the statistical relationships between speech and gesture using generative models
- Sampling new synthetic examples that preserve these learned patterns
The researchers then used the synthetic data, along with any available real-world data, to train a sequence-to-sequence model for speech-and-gesture synthesis. Experiments showed that models trained on the combined real and synthetic data achieved significantly better performance compared to models trained only on limited real-world data.
Critical Analysis
The researchers acknowledge several caveats and limitations in their work. First, while the synthetic data was able to improve model performance, there may still be some important differences between the synthetic and real-world examples that limit the model's ability to generalize. Additionally, the paper does not provide a comprehensive analysis of the generated synthetic data to ensure it fully captures the complexity and nuance of real-world speech and gesture interactions.
Another potential issue is the computational cost and complexity of the synthetic data generation process. Scaling this approach to larger datasets or more diverse scenarios may require significant engineering effort and resources.
That said, the researchers make a compelling case for the value of synthetic data in addressing the data shortage for joint multimodal synthesis tasks. Their work demonstrates the potential of this approach and encourages further research into more advanced synthetic data generation techniques.
Conclusion
This paper presents a promising approach to leveraging synthetic data to improve joint multimodal speech-and-gesture synthesis, a task that has been hampered by the lack of high-quality real-world training data. By generating realistic synthetic examples and using them to supplement limited real-world data, the researchers were able to train more effective models for this task.
The findings of this work could have significant implications for the development of more natural and expressive human-AI interaction systems, as well as broader applications in areas like virtual characters, augmented reality, and human-robot interaction. As the field of multimodal AI continues to advance, the strategic use of synthetic data may become an increasingly important tool for overcoming data-related challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fake it to make it: Using synthetic data to remedy the data shortage in joint multimodal speech-and-gesture synthesis
Shivam Mehta, Anna Deichler, Jim O'Regan, Birger Moell, Jonas Beskow, Gustav Eje Henter, Simon Alexanderson
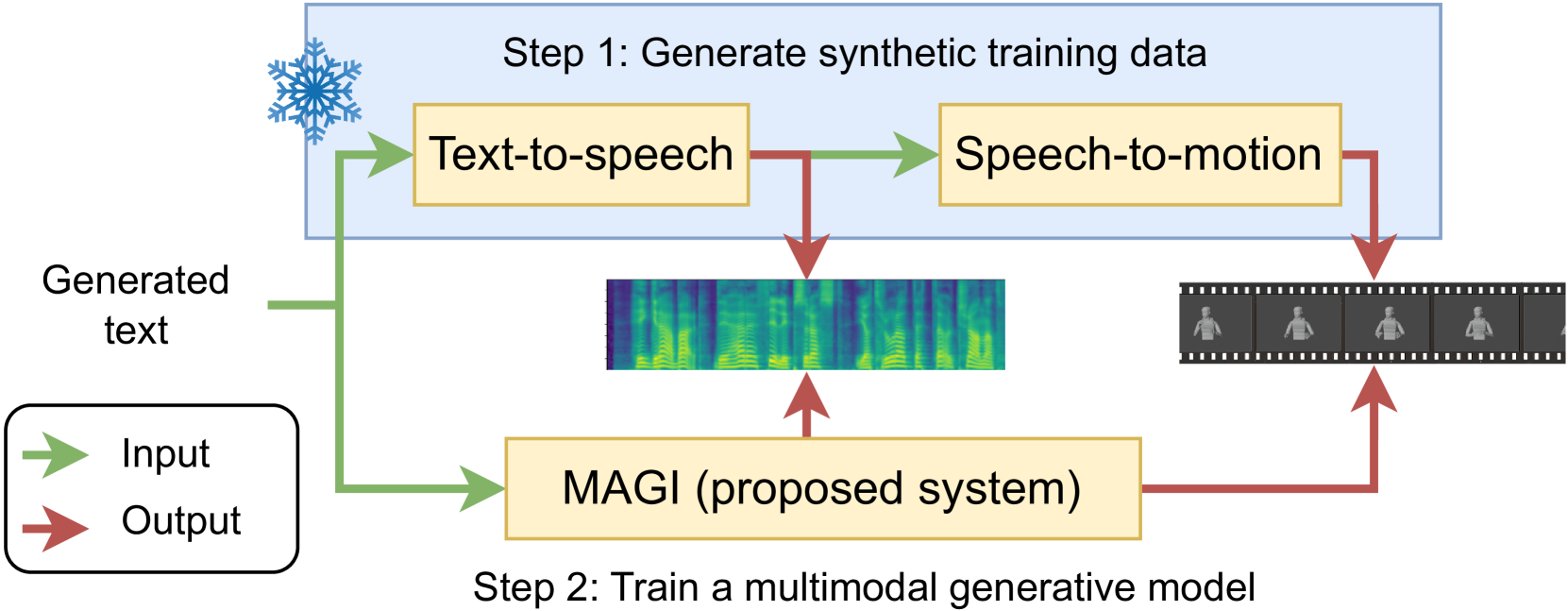
Although humans engaged in face-to-face conversation simultaneously communicate both verbally and non-verbally, methods for joint and unified synthesis of speech audio and co-speech 3D gesture motion from text are a new and emerging field. These technologies hold great promise for more human-like, efficient, expressive, and robust synthetic communication, but are currently held back by the lack of suitably large datasets, as existing methods are trained on parallel data from all constituent modalities. Inspired by student-teacher methods, we propose a straightforward solution to the data shortage, by simply synthesising additional training material. Specifically, we use unimodal synthesis models trained on large datasets to create multimodal (but synthetic) parallel training data, and then pre-train a joint synthesis model on that material. In addition, we propose a new synthesis architecture that adds better and more controllable prosody modelling to the state-of-the-art method in the field. Our results confirm that pre-training on large amounts of synthetic data improves the quality of both the speech and the motion synthesised by the multimodal model, with the proposed architecture yielding further benefits when pre-trained on the synthetic data. See https://shivammehta25.github.io/MAGI/ for example output.
Read more5/1/2024
📊
0
Instruction Data Generation and Unsupervised Adaptation for Speech Language Models
Vahid Noroozi, Zhehuai Chen, Somshubra Majumdar, Steve Huang, Jagadeesh Balam, Boris Ginsburg
In this paper, we propose three methods for generating synthetic samples to train and evaluate multimodal large language models capable of processing both text and speech inputs. Addressing the scarcity of samples containing both modalities, synthetic data generation emerges as a crucial strategy to enhance the performance of such systems and facilitate the modeling of cross-modal relationships between the speech and text domains. Our process employs large language models to generate textual components and text-to-speech systems to generate speech components. The proposed methods offer a practical and effective means to expand the training dataset for these models. Experimental results show progress in achieving an integrated understanding of text and speech. We also highlight the potential of using unlabeled speech data to generate synthetic samples comparable in quality to those with available transcriptions, enabling the expansion of these models to more languages.
Read more6/21/2024

0
Speech2UnifiedExpressions: Synchronous Synthesis of Co-Speech Affective Face and Body Expressions from Affordable Inputs
Uttaran Bhattacharya, Aniket Bera, Dinesh Manocha
We present a multimodal learning-based method to simultaneously synthesize co-speech facial expressions and upper-body gestures for digital characters using RGB video data captured using commodity cameras. Our approach learns from sparse face landmarks and upper-body joints, estimated directly from video data, to generate plausible emotive character motions. Given a speech audio waveform and a token sequence of the speaker's face landmark motion and body-joint motion computed from a video, our method synthesizes the motion sequences for the speaker's face landmarks and body joints to match the content and the affect of the speech. We design a generator consisting of a set of encoders to transform all the inputs into a multimodal embedding space capturing their correlations, followed by a pair of decoders to synthesize the desired face and pose motions. To enhance the plausibility of synthesis, we use an adversarial discriminator that learns to differentiate between the face and pose motions computed from the original videos and our synthesized motions based on their affective expressions. To evaluate our approach, we extend the TED Gesture Dataset to include view-normalized, co-speech face landmarks in addition to body gestures. We demonstrate the performance of our method through thorough quantitative and qualitative experiments on multiple evaluation metrics and via a user study. We observe that our method results in low reconstruction error and produces synthesized samples with diverse facial expressions and body gestures for digital characters.
Read more6/27/2024
0
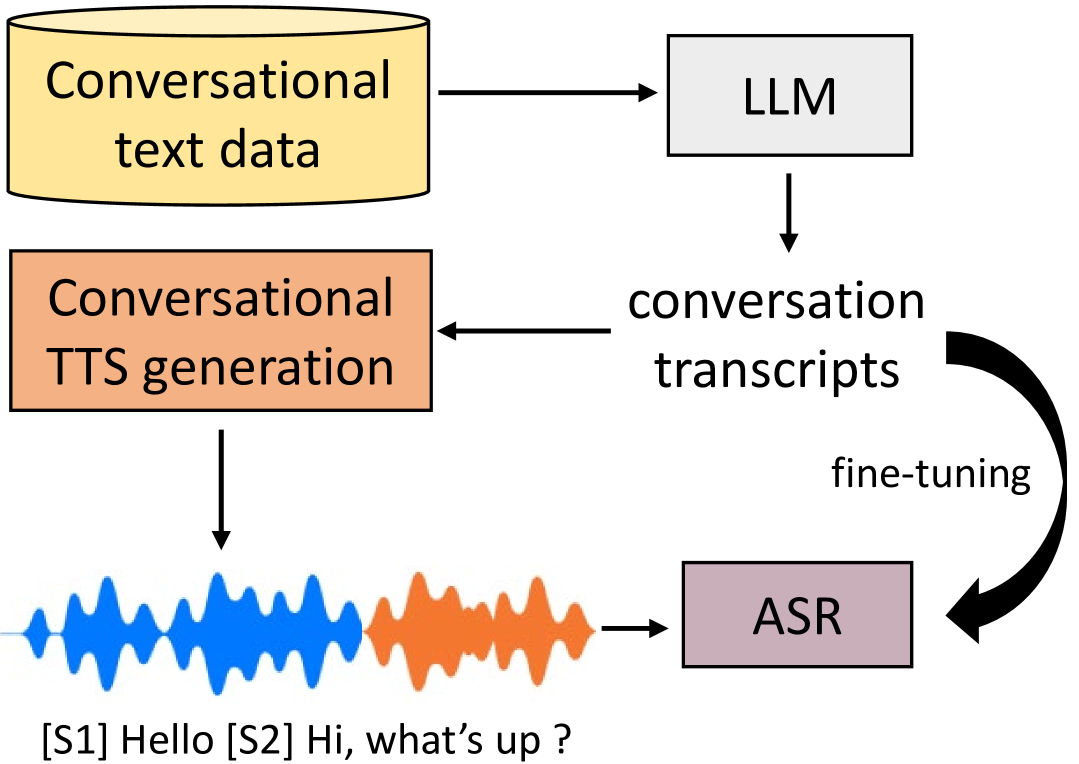
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024