MMBench: Is Your Multi-modal Model an All-around Player?
2307.06281
0
0

Abstract
Large vision-language models have recently achieved remarkable progress, exhibiting great perception and reasoning abilities concerning visual information. However, how to effectively evaluate these large vision-language models remains a major obstacle, hindering future model development. Traditional benchmarks like VQAv2 or COCO Caption provide quantitative performance measurements but suffer from a lack of fine-grained ability assessment and non-robust evaluation metrics. Recent subjective benchmarks, such as OwlEval, offer comprehensive evaluations of a model's abilities by incorporating human labor, but they are not scalable and display significant bias. In response to these challenges, we propose MMBench, a novel multi-modality benchmark. MMBench methodically develops a comprehensive evaluation pipeline, primarily comprised of two elements. The first element is a meticulously curated dataset that surpasses existing similar benchmarks in terms of the number and variety of evaluation questions and abilities. The second element introduces a novel CircularEval strategy and incorporates the use of ChatGPT. This implementation is designed to convert free-form predictions into pre-defined choices, thereby facilitating a more robust evaluation of the model's predictions. MMBench is a systematically-designed objective benchmark for robustly evaluating the various abilities of vision-language models. We hope MMBench will assist the research community in better evaluating their models and encourage future advancements in this domain. Project page: https://opencompass.org.cn/mmbench.
Create account to get full access
Overview
- This paper introduces MMBench, a comprehensive evaluation framework for assessing the multi-modal capabilities of large language models (LLMs).
- MMBench includes a diverse set of benchmarks that cover a wide range of multi-modal tasks, such as visual-linguistic reasoning, 3D understanding, multi-turn conversation, and per-sample evaluation.
- The authors use MMBench to evaluate the performance of several prominent multi-modal LLMs, providing insights into their strengths and weaknesses across different task domains.
Plain English Explanation
The paper introduces a comprehensive evaluation framework called MMBench to assess the multi-modal capabilities of large language models (LLMs). These models are designed to understand and process various types of data, including text, images, and even 3D objects.
MMBench includes a diverse set of benchmarks that cover a wide range of multi-modal tasks. For example, it tests the models' ability to reason about visual and linguistic information together, understand 3D shapes and structures, engage in multi-turn conversations, and perform well on a per-sample basis.
By using MMBench to evaluate several prominent multi-modal LLMs, the researchers gain insights into the strengths and weaknesses of these models across different task domains. This information can help researchers and developers improve the overall capabilities of multi-modal LLMs and ensure they are well-rounded, "all-around players" in the field of artificial intelligence.
Technical Explanation
The paper introduces MMBench, a comprehensive evaluation framework designed to assess the multi-modal capabilities of large language models (LLMs). MMBench includes a diverse set of benchmarks that cover a wide range of multi-modal tasks, including visual-linguistic reasoning, 3D understanding, multi-turn conversation, and per-sample evaluation.
The authors use MMBench to evaluate the performance of several prominent multi-modal LLMs, including BLIP, VL-T5, and CLIP+GPT-3. The evaluation results provide insights into the strengths and weaknesses of these models across different task domains. For example, the authors find that the models excel at visual-linguistic reasoning but struggle with 3D understanding and multi-turn conversation.
The paper also highlights the importance of comprehensive multi-modal benchmarking, as it can help identify the limitations of current multi-modal LLMs and guide future research and development efforts to address these limitations.
Critical Analysis
The MMBench framework presented in the paper is a valuable contribution to the field of multi-modal AI, as it provides a standardized way to evaluate the capabilities of large language models across a diverse set of tasks.
One potential limitation of the research is that the benchmarks included in MMBench, while comprehensive, may not capture the full breadth of multi-modal tasks that LLMs are expected to handle in real-world applications. Additional benchmarks that assess long-context understanding or the ability to adapt to new domains could further enhance the evaluation framework.
Furthermore, the paper primarily focuses on the performance of existing multi-modal LLMs, but does not delve deeply into the design choices and architectural differences that may contribute to their varying capabilities. A more in-depth analysis of the models' internal mechanisms could provide valuable insights for future model development.
Despite these potential limitations, the MMBench framework and the insights gleaned from its application represent an important step forward in understanding the current state of multi-modal LLMs and guiding future research in this rapidly evolving field of AI.
Conclusion
The MMBench evaluation framework introduced in this paper is a significant contribution to the field of multi-modal artificial intelligence. By providing a comprehensive set of benchmarks that cover a wide range of multi-modal tasks, MMBench enables a thorough assessment of the capabilities of large language models.
The authors' use of MMBench to evaluate several prominent multi-modal LLMs reveals both the strengths and weaknesses of these models, highlighting areas where they excel (such as visual-linguistic reasoning) and areas where they fall short (such as 3D understanding and multi-turn conversation). This information is invaluable for researchers and developers working to advance the state of the art in multi-modal AI.
As the field of multi-modal AI continues to evolve, frameworks like MMBench will play a crucial role in guiding research and development efforts, ensuring that the next generation of multi-modal LLMs are true "all-around players" capable of handling a diverse range of real-world tasks and challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AlignMMBench: Evaluating Chinese Multimodal Alignment in Large Vision-Language Models
Yuhang Wu, Wenmeng Yu, Yean Cheng, Yan Wang, Xiaohan Zhang, Jiazheng Xu, Ming Ding, Yuxiao Dong
0
0
Evaluating the alignment capabilities of large Vision-Language Models (VLMs) is essential for determining their effectiveness as helpful assistants. However, existing benchmarks primarily focus on basic abilities using nonverbal methods, such as yes-no and multiple-choice questions. In this paper, we address this gap by introducing AlignMMBench, a comprehensive alignment benchmark specifically designed for emerging Chinese VLMs. This benchmark is meticulously curated from real-world scenarios and Chinese Internet sources, encompassing thirteen specific tasks across three categories, and includes both single-turn and multi-turn dialogue scenarios. Incorporating a prompt rewrite strategy, AlignMMBench encompasses 1,054 images and 4,978 question-answer pairs. To facilitate the evaluation pipeline, we propose CritiqueVLM, a rule-calibrated evaluator that exceeds GPT-4's evaluation ability. Finally, we report the performance of representative VLMs on AlignMMBench, offering insights into the capabilities and limitations of different VLM architectures. All evaluation codes and data are available on https://alignmmbench.github.io.
6/17/2024
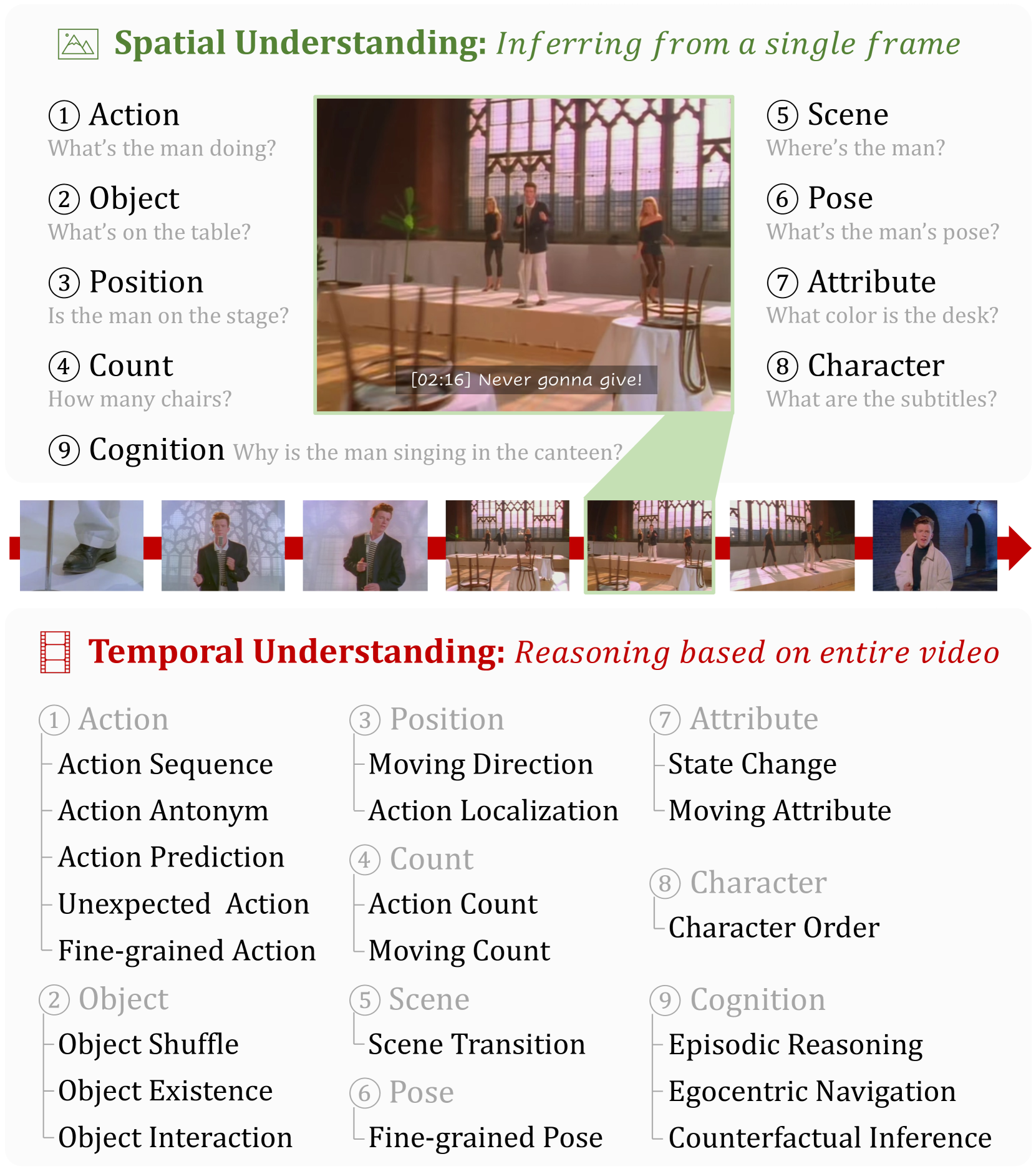
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, Yu Qiao
0
0
With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.
5/24/2024

MMBench-Video: A Long-Form Multi-Shot Benchmark for Holistic Video Understanding
Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, Kai Chen
0
0
The advent of large vision-language models (LVLMs) has spurred research into their applications in multi-modal contexts, particularly in video understanding. Traditional VideoQA benchmarks, despite providing quantitative metrics, often fail to encompass the full spectrum of video content and inadequately assess models' temporal comprehension. To address these limitations, we introduce MMBench-Video, a quantitative benchmark designed to rigorously evaluate LVLMs' proficiency in video understanding. MMBench-Video incorporates lengthy videos from YouTube and employs free-form questions, mirroring practical use cases. The benchmark is meticulously crafted to probe the models' temporal reasoning skills, with all questions human-annotated according to a carefully constructed ability taxonomy. We employ GPT-4 for automated assessment, demonstrating superior accuracy and robustness over earlier LLM-based evaluations. Utilizing MMBench-Video, we have conducted comprehensive evaluations that include both proprietary and open-source LVLMs for images and videos. MMBench-Video stands as a valuable resource for the research community, facilitating improved evaluation of LVLMs and catalyzing progress in the field of video understanding. The evalutation code of MMBench-Video will be integrated into VLMEvalKit: https://github.com/open-compass/VLMEvalKit.
6/21/2024

VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
Junpeng Liu, Yifan Song, Bill Yuchen Lin, Wai Lam, Graham Neubig, Yuanzhi Li, Xiang Yue
0
0
Multimodal Large Language models (MLLMs) have shown promise in web-related tasks, but evaluating their performance in the web domain remains a challenge due to the lack of comprehensive benchmarks. Existing benchmarks are either designed for general multimodal tasks, failing to capture the unique characteristics of web pages, or focus on end-to-end web agent tasks, unable to measure fine-grained abilities such as OCR, understanding, and grounding. In this paper, we introduce bench{}, a multimodal benchmark designed to assess the capabilities of MLLMs across a variety of web tasks. bench{} consists of seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude-3 series, and GPT-4V(ision) on bench{}, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe bench{} will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
4/10/2024