MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
2311.17005
0
0
Abstract
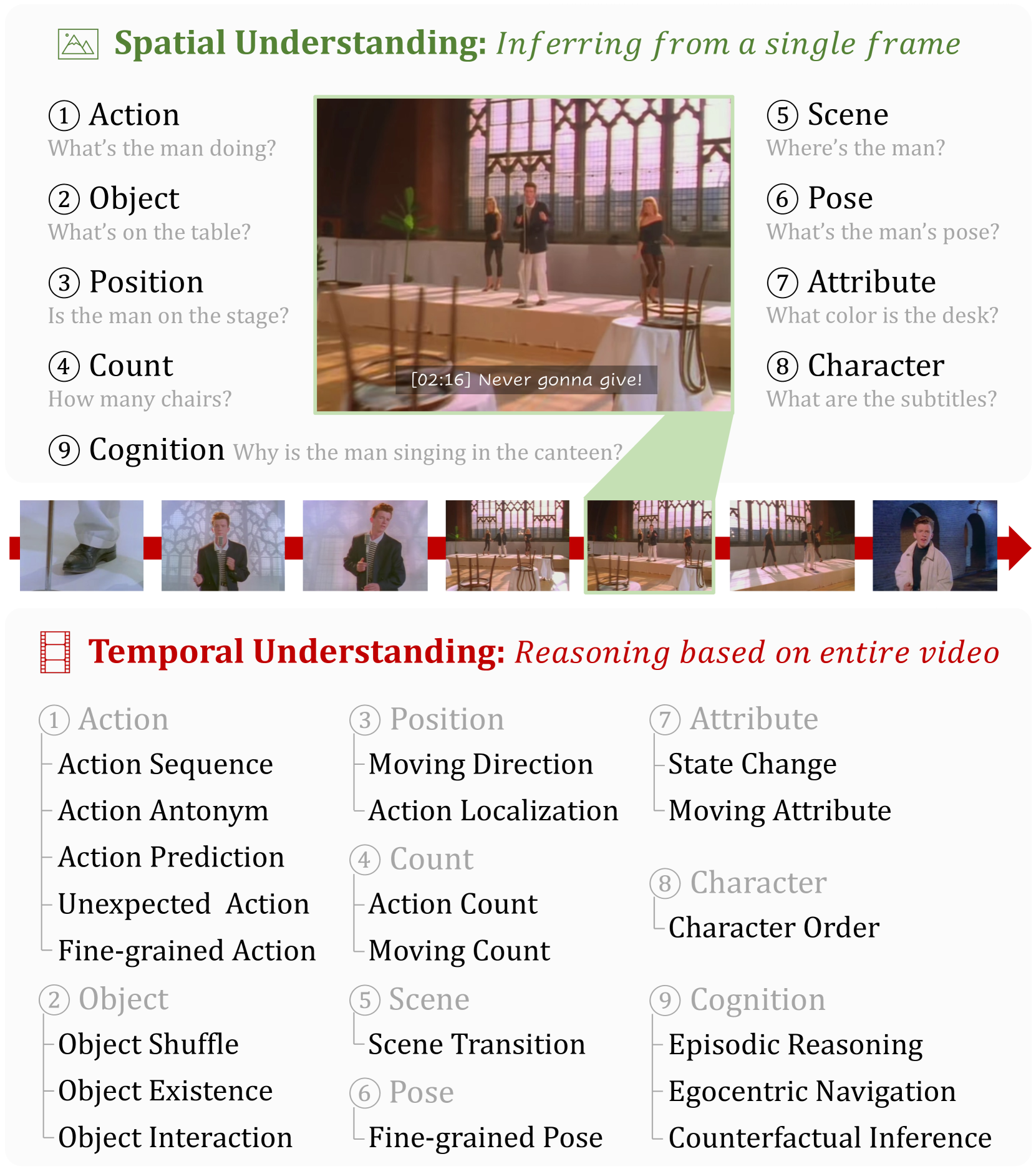
With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.
Create account to get full access
Overview
• This paper introduces MVBench, a comprehensive benchmark for evaluating multi-modal video understanding models.
• MVBench covers a diverse set of tasks, including video classification, video question answering, and video grounding, across various domains like sports, movies, and daily activities.
• The benchmark aims to assess the performance, robustness, and generalization capabilities of multi-modal video understanding models.
Plain English Explanation
MVBench is a new tool that helps researchers and developers test how well their AI models can understand and process videos with multiple types of information, like video, audio, and text.
The researchers who created MVBench wanted to build a benchmark that covers a wide range of video-based tasks, from classifying the type of video to answering questions about what's happening in the video to identifying specific objects or events. This diversity of tasks is important because it allows them to get a more comprehensive understanding of how well these multi-modal AI models are performing.
By using MVBench, researchers can see how their models handle different types of videos, like sports, movies, and everyday activities. This helps them identify the strengths and weaknesses of their models and make improvements where needed. The goal is to push the boundaries of what's possible with AI-powered video understanding, which could have important applications in areas like video search, video summarization, and automated video analysis.
Technical Explanation
MVBench is a new benchmark designed to evaluate the performance, robustness, and generalization capabilities of multi-modal video understanding models. The benchmark covers a diverse set of tasks, including video classification, video question answering, and video grounding, across various domains like sports, movies, and daily activities.
The researchers carefully curated a large-scale dataset to support these tasks, drawing from existing video datasets and adding new annotations. This dataset includes a wide range of video content, along with associated textual information like captions, questions, and grounding annotations.
To establish a strong baseline, the researchers evaluated several state-of-the-art multi-modal models on the MVBench tasks. The results show that while these models perform well on certain tasks, there is still significant room for improvement, particularly in terms of robustness and generalization.
Critical Analysis
The researchers acknowledge that MVBench is not an exhaustive evaluation of multi-modal video understanding, and there are still areas for further development. For example, the dataset could be expanded to include more diverse video content and annotations, and the benchmark could be extended to cover additional tasks or modalities.
Additionally, the researchers note that the performance of multi-modal models on MVBench may be influenced by factors like model architecture, training data, and optimization techniques. As such, further research is needed to understand the specific strengths and weaknesses of different approaches and how they can be improved.
Despite these limitations, MVBench represents an important step forward in the evaluation of multi-modal video understanding models. By providing a comprehensive and challenging benchmark, the researchers hope to drive progress in this rapidly evolving field and ultimately enable more advanced and capable AI systems for real-world video analysis tasks.
Conclusion
MVBench is a valuable new tool for evaluating the performance, robustness, and generalization of multi-modal video understanding models. By covering a diverse range of tasks and domains, the benchmark aims to push the boundaries of what's possible with AI-powered video analysis.
The results of the initial baseline evaluations suggest that while current state-of-the-art models show promising performance, there is still significant room for improvement, particularly in terms of robustness and generalization. The researchers hope that MVBench will serve as a catalyst for further advancements in this field, ultimately leading to more powerful and versatile AI systems that can better understand and process the rich information contained in videos.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MMBench-Video: A Long-Form Multi-Shot Benchmark for Holistic Video Understanding
Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, Kai Chen
0
0
The advent of large vision-language models (LVLMs) has spurred research into their applications in multi-modal contexts, particularly in video understanding. Traditional VideoQA benchmarks, despite providing quantitative metrics, often fail to encompass the full spectrum of video content and inadequately assess models' temporal comprehension. To address these limitations, we introduce MMBench-Video, a quantitative benchmark designed to rigorously evaluate LVLMs' proficiency in video understanding. MMBench-Video incorporates lengthy videos from YouTube and employs free-form questions, mirroring practical use cases. The benchmark is meticulously crafted to probe the models' temporal reasoning skills, with all questions human-annotated according to a carefully constructed ability taxonomy. We employ GPT-4 for automated assessment, demonstrating superior accuracy and robustness over earlier LLM-based evaluations. Utilizing MMBench-Video, we have conducted comprehensive evaluations that include both proprietary and open-source LVLMs for images and videos. MMBench-Video stands as a valuable resource for the research community, facilitating improved evaluation of LVLMs and catalyzing progress in the field of video understanding. The evalutation code of MMBench-Video will be integrated into VLMEvalKit: https://github.com/open-compass/VLMEvalKit.
6/21/2024

LVBench: An Extreme Long Video Understanding Benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Shiyu Huang, Bin Xu, Yuxiao Dong, Ming Ding, Jie Tang
0
0
Recent progress in multimodal large language models has markedly enhanced the understanding of short videos (typically under one minute), and several evaluation datasets have emerged accordingly. However, these advancements fall short of meeting the demands of real-world applications such as embodied intelligence for long-term decision-making, in-depth movie reviews and discussions, and live sports commentary, all of which require comprehension of long videos spanning several hours. To address this gap, we introduce LVBench, a benchmark specifically designed for long video understanding. Our dataset comprises publicly sourced videos and encompasses a diverse set of tasks aimed at long video comprehension and information extraction. LVBench is designed to challenge multimodal models to demonstrate long-term memory and extended comprehension capabilities. Our extensive evaluations reveal that current multimodal models still underperform on these demanding long video understanding tasks. Through LVBench, we aim to spur the development of more advanced models capable of tackling the complexities of long video comprehension. Our data and code are publicly available at: https://lvbench.github.io.
6/13/2024

MMBench: Is Your Multi-modal Model an All-around Player?
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, Dahua Lin
0
0
Large vision-language models have recently achieved remarkable progress, exhibiting great perception and reasoning abilities concerning visual information. However, how to effectively evaluate these large vision-language models remains a major obstacle, hindering future model development. Traditional benchmarks like VQAv2 or COCO Caption provide quantitative performance measurements but suffer from a lack of fine-grained ability assessment and non-robust evaluation metrics. Recent subjective benchmarks, such as OwlEval, offer comprehensive evaluations of a model's abilities by incorporating human labor, but they are not scalable and display significant bias. In response to these challenges, we propose MMBench, a novel multi-modality benchmark. MMBench methodically develops a comprehensive evaluation pipeline, primarily comprised of two elements. The first element is a meticulously curated dataset that surpasses existing similar benchmarks in terms of the number and variety of evaluation questions and abilities. The second element introduces a novel CircularEval strategy and incorporates the use of ChatGPT. This implementation is designed to convert free-form predictions into pre-defined choices, thereby facilitating a more robust evaluation of the model's predictions. MMBench is a systematically-designed objective benchmark for robustly evaluating the various abilities of vision-language models. We hope MMBench will assist the research community in better evaluating their models and encourage future advancements in this domain. Project page: https://opencompass.org.cn/mmbench.
4/30/2024
MLVU: A Comprehensive Benchmark for Multi-Task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, Zheng Liu
0
0
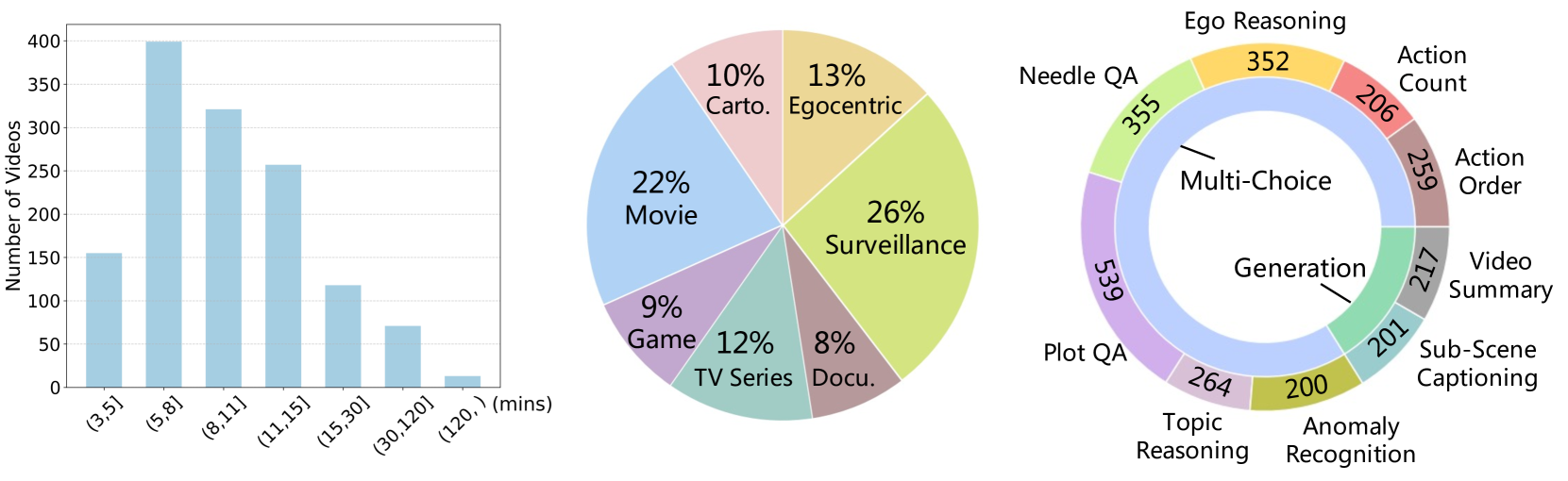
The evaluation of Long Video Understanding (LVU) performance poses an important but challenging research problem. Despite previous efforts, the existing video understanding benchmarks are severely constrained by several issues, especially the insufficient lengths of videos, a lack of diversity in video types and evaluation tasks, and the inappropriateness for evaluating LVU performances. To address the above problems, we propose a new benchmark, called MLVU (Multi-task Long Video Understanding Benchmark), for the comprehensive and in-depth evaluation of LVU. MLVU presents the following critical values: 1) The substantial and flexible extension of video lengths, which enables the benchmark to evaluate LVU performance across a wide range of durations. 2) The inclusion of various video genres, e.g., movies, surveillance footage, egocentric videos, cartoons, game videos, etc., which reflects the models' LVU performances in different scenarios. 3) The development of diversified evaluation tasks, which enables a comprehensive examination of MLLMs' key abilities in long-video understanding. The empirical study with 20 latest MLLMs reveals significant room for improvement in today's technique, as all existing methods struggle with most of the evaluation tasks and exhibit severe performance degradation when handling longer videos. Additionally, it suggests that factors such as context length, image-understanding quality, and the choice of LLM backbone can play critical roles in future advancements. We anticipate that MLVU will advance the research of long video understanding by providing a comprehensive and in-depth analysis of MLLMs.
6/21/2024