MMGRec: Multimodal Generative Recommendation with Transformer Model
2404.16555
0
0
Abstract
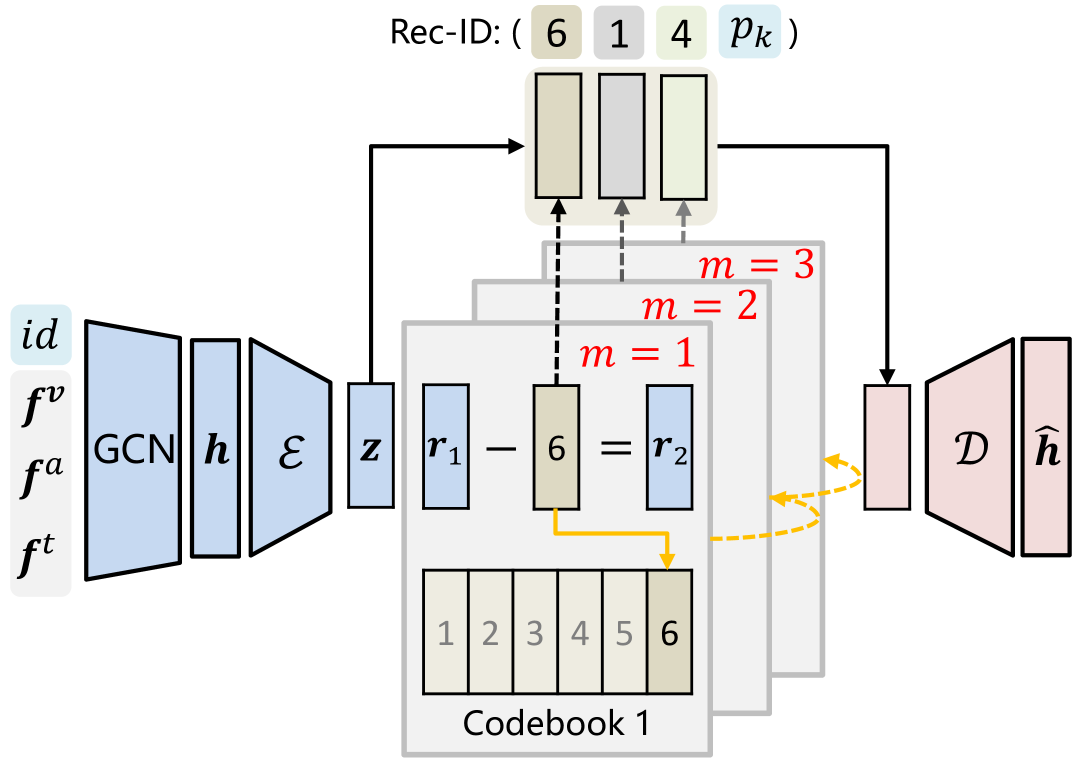
Multimodal recommendation aims to recommend user-preferred candidates based on her/his historically interacted items and associated multimodal information. Previous studies commonly employ an embed-and-retrieve paradigm: learning user and item representations in the same embedding space, then retrieving similar candidate items for a user via embedding inner product. However, this paradigm suffers from inference cost, interaction modeling, and false-negative issues. Toward this end, we propose a new MMGRec model to introduce a generative paradigm into multimodal recommendation. Specifically, we first devise a hierarchical quantization method Graph RQ-VAE to assign Rec-ID for each item from its multimodal and CF information. Consisting of a tuple of semantically meaningful tokens, Rec-ID serves as the unique identifier of each item. Afterward, we train a Transformer-based recommender to generate the Rec-IDs of user-preferred items based on historical interaction sequences. The generative paradigm is qualified since this model systematically predicts the tuple of tokens identifying the recommended item in an autoregressive manner. Moreover, a relation-aware self-attention mechanism is devised for the Transformer to handle non-sequential interaction sequences, which explores the element pairwise relation to replace absolute positional encoding. Extensive experiments evaluate MMGRec's effectiveness compared with state-of-the-art methods.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces MMGRec, a multimodal generative recommendation model that uses transformer architecture to generate personalized item recommendations.
- MMGRec aims to capture the complex relationships between users, items, and multimodal content (e.g., images, text) to provide more accurate and diverse recommendations.
- The model is trained in an end-to-end fashion, allowing it to jointly learn feature representations and generate recommendations.
Plain English Explanation
MMGRec is a new kind of recommendation system that uses advanced AI technology to make better suggestions for things you might like, such as products, videos, or other content. Typical recommendation systems look at your past preferences and actions to guess what you might want next. But MMGRec goes further by also considering the actual content of the items, like the images and text associated with them.
By using a powerful machine learning model called a transformer, MMGRec can understand the complex relationships between you, the items you interact with, and the multimodal (text and visual) information about those items. This allows it to make more personalized and diverse recommendations that are tailored to your unique interests and tastes.
The key innovation of MMGRec is that it is trained end-to-end, meaning the model learns how to extract relevant features from the data and generate the recommendations all in one unified process. This can lead to better performance compared to approaches that separate these steps.
Technical Explanation
The core of MMGRec is a transformer-based architecture that takes as input a user's profile, item metadata (e.g., images, text descriptions), and interaction history. The model learns to encode this multimodal information into compact representations, which are then used to generate personalized item recommendations.
A key aspect of the architecture is its end-to-end training approach, where the feature extraction and recommendation generation components are jointly optimized. This is in contrast to traditional two-stage recommender systems that first learn item and user representations, then use those representations for recommendation. The authors argue the end-to-end approach allows MMGRec to better capture the complex relationships between users, items, and multimodal content.
The authors evaluate MMGRec on several standard recommendation benchmarks, comparing it to state-of-the-art multimodal and unimodal recommendation methods. The results show MMGRec outperforms these baselines in terms of recommendation accuracy and diversity, demonstrating the value of its multimodal, generative approach.
Critical Analysis
The paper provides a thorough technical description of the MMGRec model and its training procedure. The end-to-end architecture is an interesting innovation that could lead to improved recommendation performance by allowing the model to jointly optimize feature learning and generation.
However, the paper does not delve deeply into the limitations or potential issues with the proposed approach. For example, it's unclear how MMGRec would scale to very large datasets with millions of users and items, or how it would handle cold-start situations where little user or item information is available.
Additionally, the authors only evaluate MMGRec on standard benchmark datasets, which may not fully reflect real-world recommendation challenges. Further testing on more diverse, industry-relevant datasets could provide additional insights into the model's strengths and weaknesses.
That said, the strong empirical results demonstrate the potential of MMGRec's multimodal, generative approach to recommendation. Future work exploring ways to improve the model's scalability and robustness would be a valuable contribution to the field of recommender systems and multimodal recommendation.
Conclusion
The MMGRec paper introduces a novel transformer-based recommendation model that leverages multimodal item information, such as images and text, to generate personalized item recommendations. By taking an end-to-end training approach, the model is able to better capture the complex relationships between users, items, and multimodal content, leading to improved recommendation accuracy and diversity.
While the paper does not address all the potential limitations of the approach, the strong empirical results suggest MMGRec is a promising direction for advancing the state-of-the-art in multimodal recommendation. Further research exploring ways to improve the model's scalability and robustness could lead to significant breakthroughs in the field of personalized recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LGMRec: Local and Global Graph Learning for Multimodal Recommendation
Zhiqiang Guo, Jianjun Li, Guohui Li, Chaoyang Wang, Si Shi, Bin Ruan
0
0
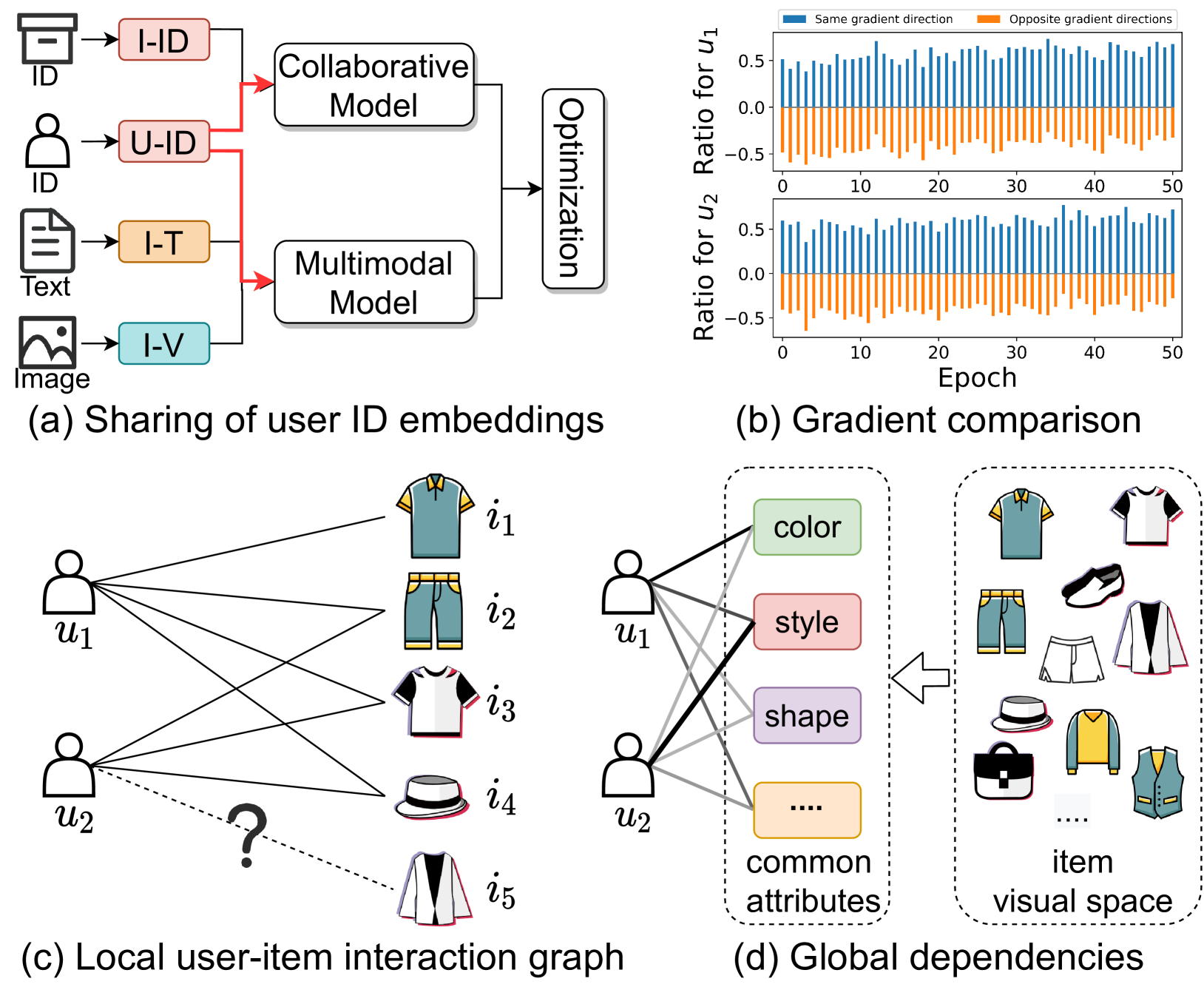
The multimodal recommendation has gradually become the infrastructure of online media platforms, enabling them to provide personalized service to users through a joint modeling of user historical behaviors (e.g., purchases, clicks) and item various modalities (e.g., visual and textual). The majority of existing studies typically focus on utilizing modal features or modal-related graph structure to learn user local interests. Nevertheless, these approaches encounter two limitations: (1) Shared updates of user ID embeddings result in the consequential coupling between collaboration and multimodal signals; (2) Lack of exploration into robust global user interests to alleviate the sparse interaction problems faced by local interest modeling. To address these issues, we propose a novel Local and Global Graph Learning-guided Multimodal Recommender (LGMRec), which jointly models local and global user interests. Specifically, we present a local graph embedding module to independently learn collaborative-related and modality-related embeddings of users and items with local topological relations. Moreover, a global hypergraph embedding module is designed to capture global user and item embeddings by modeling insightful global dependency relations. The global embeddings acquired within the hypergraph embedding space can then be combined with two decoupled local embeddings to improve the accuracy and robustness of recommendations. Extensive experiments conducted on three benchmark datasets demonstrate the superiority of our LGMRec over various state-of-the-art recommendation baselines, showcasing its effectiveness in modeling both local and global user interests.
4/19/2024
🛸
Multimodal Pretraining and Generation for Recommendation: A Tutorial
Jieming Zhu, Chuhan Wu, Rui Zhang, Zhenhua Dong
0
0
Personalized recommendation stands as a ubiquitous channel for users to explore information or items aligned with their interests. Nevertheless, prevailing recommendation models predominantly rely on unique IDs and categorical features for user-item matching. While this ID-centric approach has witnessed considerable success, it falls short in comprehensively grasping the essence of raw item contents across diverse modalities, such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, particularly in the realm of multimedia services like news, music, and short-video platforms. The recent surge in pretraining and generation techniques presents both opportunities and challenges in the development of multimodal recommender systems. This tutorial seeks to provide a thorough exploration of the latest advancements and future trajectories in multimodal pretraining and generation techniques within the realm of recommender systems. The tutorial comprises three parts: multimodal pretraining, multimodal generation, and industrial applications and open challenges in the field of recommendation. Our target audience encompasses scholars, practitioners, and other parties interested in this domain. By providing a succinct overview of the field, we aspire to facilitate a swift understanding of multimodal recommendation and foster meaningful discussions on the future development of this evolving landscape.
5/14/2024
PMG : Personalized Multimodal Generation with Large Language Models
Xiaoteng Shen, Rui Zhang, Xiaoyan Zhao, Jieming Zhu, Xi Xiao
0
0
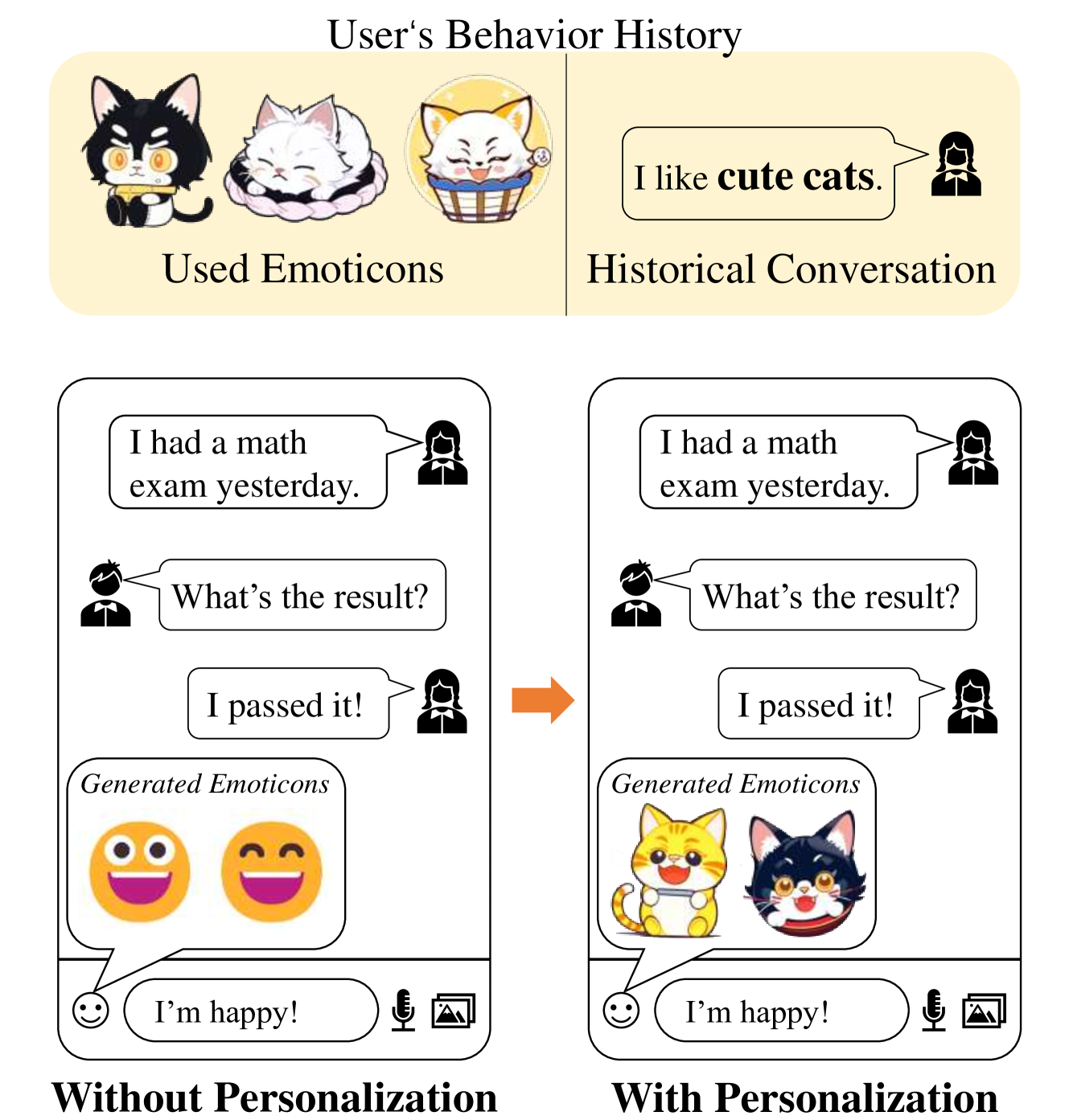
The emergence of large language models (LLMs) has revolutionized the capabilities of text comprehension and generation. Multi-modal generation attracts great attention from both the industry and academia, but there is little work on personalized generation, which has important applications such as recommender systems. This paper proposes the first method for personalized multimodal generation using LLMs, showcases its applications and validates its performance via an extensive experimental study on two datasets. The proposed method, Personalized Multimodal Generation (PMG for short) first converts user behaviors (e.g., clicks in recommender systems or conversations with a virtual assistant) into natural language to facilitate LLM understanding and extract user preference descriptions. Such user preferences are then fed into a generator, such as a multimodal LLM or diffusion model, to produce personalized content. To capture user preferences comprehensively and accurately, we propose to let the LLM output a combination of explicit keywords and implicit embeddings to represent user preferences. Then the combination of keywords and embeddings are used as prompts to condition the generator. We optimize a weighted sum of the accuracy and preference scores so that the generated content has a good balance between them. Compared to a baseline method without personalization, PMG has a significant improvement on personalization for up to 8% in terms of LPIPS while retaining the accuracy of generation.
4/16/2024

Contrastive Quantization based Semantic Code for Generative Recommendation
Mengqun Jin, Zexuan Qiu, Jieming Zhu, Zhenhua Dong, Xiu Li
0
0
With the success of large language models, generative retrieval has emerged as a new retrieval technique for recommendation. It can be divided into two stages: the first stage involves constructing discrete Codes (i.e., codes), and the second stage involves decoding the code sequentially via the transformer architecture. Current methods often construct item semantic codes by reconstructing based quantization on item textual representation, but they fail to capture item discrepancy that is essential in modeling item relationships in recommendation sytems. In this paper, we propose to construct the code representation of items by simultaneously considering both item relationships and semantic information. Specifically, we employ a pre-trained language model to extract item's textual description and translate it into item's embedding. Then we propose to enhance the encoder-decoder based RQVAE model with contrastive objectives to learn item code. To be specific, we employ the embeddings generated by the decoder from the samples themselves as positive instances and those from other samples as negative instances. Thus we effectively enhance the item discrepancy across all items, better preserving the item neighbourhood. Finally, we train and test semantic code with with generative retrieval on a sequential recommendation model. Our experiments demonstrate that our method improves NDCG@5 with 43.76% on the MIND dataset and Recall@10 with 80.95% on the Office dataset compared to the previous baselines.
4/24/2024