LGMRec: Local and Global Graph Learning for Multimodal Recommendation
2312.16400
0
0
Abstract
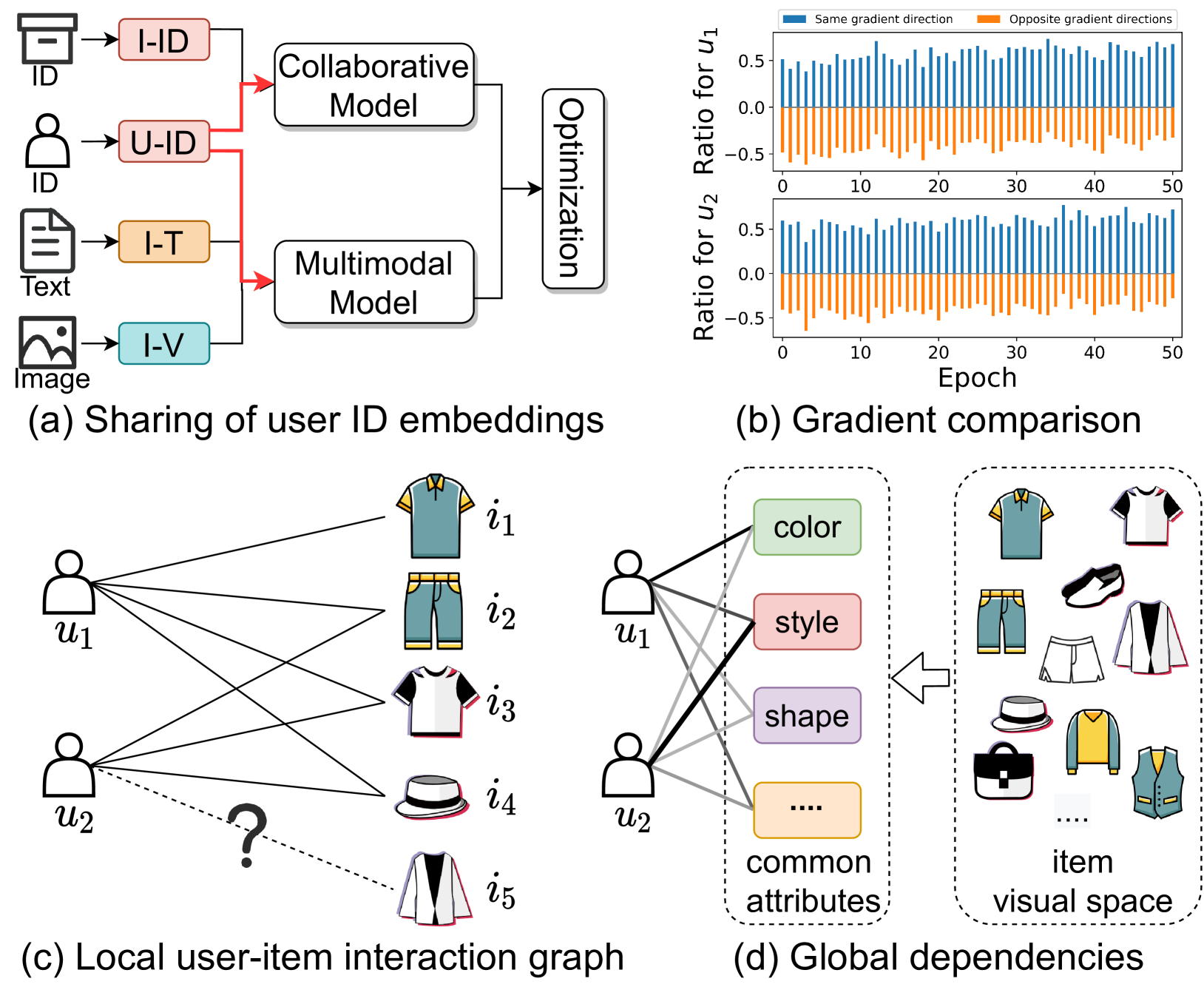
The multimodal recommendation has gradually become the infrastructure of online media platforms, enabling them to provide personalized service to users through a joint modeling of user historical behaviors (e.g., purchases, clicks) and item various modalities (e.g., visual and textual). The majority of existing studies typically focus on utilizing modal features or modal-related graph structure to learn user local interests. Nevertheless, these approaches encounter two limitations: (1) Shared updates of user ID embeddings result in the consequential coupling between collaboration and multimodal signals; (2) Lack of exploration into robust global user interests to alleviate the sparse interaction problems faced by local interest modeling. To address these issues, we propose a novel Local and Global Graph Learning-guided Multimodal Recommender (LGMRec), which jointly models local and global user interests. Specifically, we present a local graph embedding module to independently learn collaborative-related and modality-related embeddings of users and items with local topological relations. Moreover, a global hypergraph embedding module is designed to capture global user and item embeddings by modeling insightful global dependency relations. The global embeddings acquired within the hypergraph embedding space can then be combined with two decoupled local embeddings to improve the accuracy and robustness of recommendations. Extensive experiments conducted on three benchmark datasets demonstrate the superiority of our LGMRec over various state-of-the-art recommendation baselines, showcasing its effectiveness in modeling both local and global user interests.
Create account to get full access
Overview
- This paper introduces LGMRec, a multimodal recommendation system that leverages both local and global graph learning to improve recommendation performance.
- LGMRec models user-item interactions and item-item relationships using a heterogeneous graph, and learns representations that capture both local and global graph structures.
- The authors demonstrate the effectiveness of LGMRec on several benchmark datasets, showing improvements over state-of-the-art multimodal recommendation methods.
Plain English Explanation
Recommendation systems are algorithms that suggest products, content, or other items that a user might like, based on their past preferences and behaviors. LGMRec: Personalized Recommendation via Prompting Large Language Models is a new approach for building these kinds of recommendation systems.
The key idea behind LGMRec is to model the relationships between users, items, and other relevant information (like item attributes or user demographics) as a graph. A graph is a way of representing connections between different entities. In this case, the graph might show how users interact with different items, or how items are related to each other.
LGMRec learns two types of representations from this graph:
- Local representations, which capture the immediate neighborhood of each user or item in the graph. This helps the model understand the specific preferences and characteristics of individual users and items.
- Global representations, which capture the overall structure and patterns in the entire graph. This allows the model to understand broader trends and relationships across the whole dataset.
By combining these local and global representations, LGMRec can make more accurate and personalized recommendations for each user. The authors show that this approach outperforms other state-of-the-art multimodal recommendation methods on several benchmark datasets.
Technical Explanation
The core of LGMRec is a heterogeneous graph that models the relationships between users, items, and other relevant entities (e.g., item attributes, user demographics). This graph captures both user-item interactions and item-item relationships, which are important signals for making effective recommendations.
To learn representations from this graph, LGMRec uses a two-stage graph learning approach:
-
Local Graph Learning: This stage learns node-level representations that capture the local neighborhood structure around each user and item. The authors use a graph neural network (GNN) to aggregate information from each node's immediate neighbors, allowing the model to learn personalized representations.
-
Global Graph Learning: This stage learns graph-level representations that capture the overall structure and patterns in the entire graph. The authors use a pooling-based graph neural network to aggregate information across the whole graph, allowing the model to discover global relationships and trends.
The local and global representations are then combined and passed through a series of fully connected layers to produce the final recommendation scores for each user-item pair.
The authors evaluate LGMRec on several benchmark datasets for multimodal recommendation, including Amazon reviews, Yelp, and MovieLens. They compare LGMRec to a range of state-of-the-art baselines, including PMG: Personalized Multimodal Generation with Large Language Models, Zero-Shot Relational Learning for Multimodal Knowledge Graphs, and LLM-Guided Multi-View Hypergraph Learning for Human Activity Recognition. The results show that LGMRec consistently outperforms these baselines, demonstrating the effectiveness of the local and global graph learning approach.
Critical Analysis
One potential limitation of LGMRec is that it relies on the availability of a well-structured heterogeneous graph, which may not always be the case in real-world scenarios. The authors do not discuss how the graph is constructed or how sensitive the model's performance is to the quality of the graph data.
Additionally, the authors do not provide a detailed analysis of the computational complexity or runtime of LGMRec, which could be an important consideration for deploying the model in production environments. End-to-End Training of a Multimodal Model for Ranking may provide some insights on these practical considerations.
Overall, LGMRec presents a promising approach for multimodal recommendation by leveraging both local and global graph representations. However, further research is needed to understand the model's robustness and practical deployment considerations.
Conclusion
The LGMRec paper introduces a novel multimodal recommendation system that combines local and global graph learning to improve recommendation performance. By modeling user-item interactions and item-item relationships as a heterogeneous graph, LGMRec is able to learn personalized representations while also capturing broader trends and patterns in the data.
The authors demonstrate the effectiveness of this approach on several benchmark datasets, showing that LGMRec outperforms state-of-the-art multimodal recommendation methods. This suggests that the integration of local and global graph learning can be a valuable technique for building highly accurate and personalized recommendation systems.
While the paper presents a compelling approach, there are still some open questions and potential areas for further research, such as the robustness of the model to different graph structures and the practical considerations for deploying LGMRec in real-world scenarios. Nevertheless, the LGMRec framework represents an important step forward in the field of multimodal recommendation and could inspire future work in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Enhancing Collaborative Semantics of Language Model-Driven Recommendations via Graph-Aware Learning
Zhong Guan, Likang Wu, Hongke Zhao, Ming He, Jianpin Fan
0
0
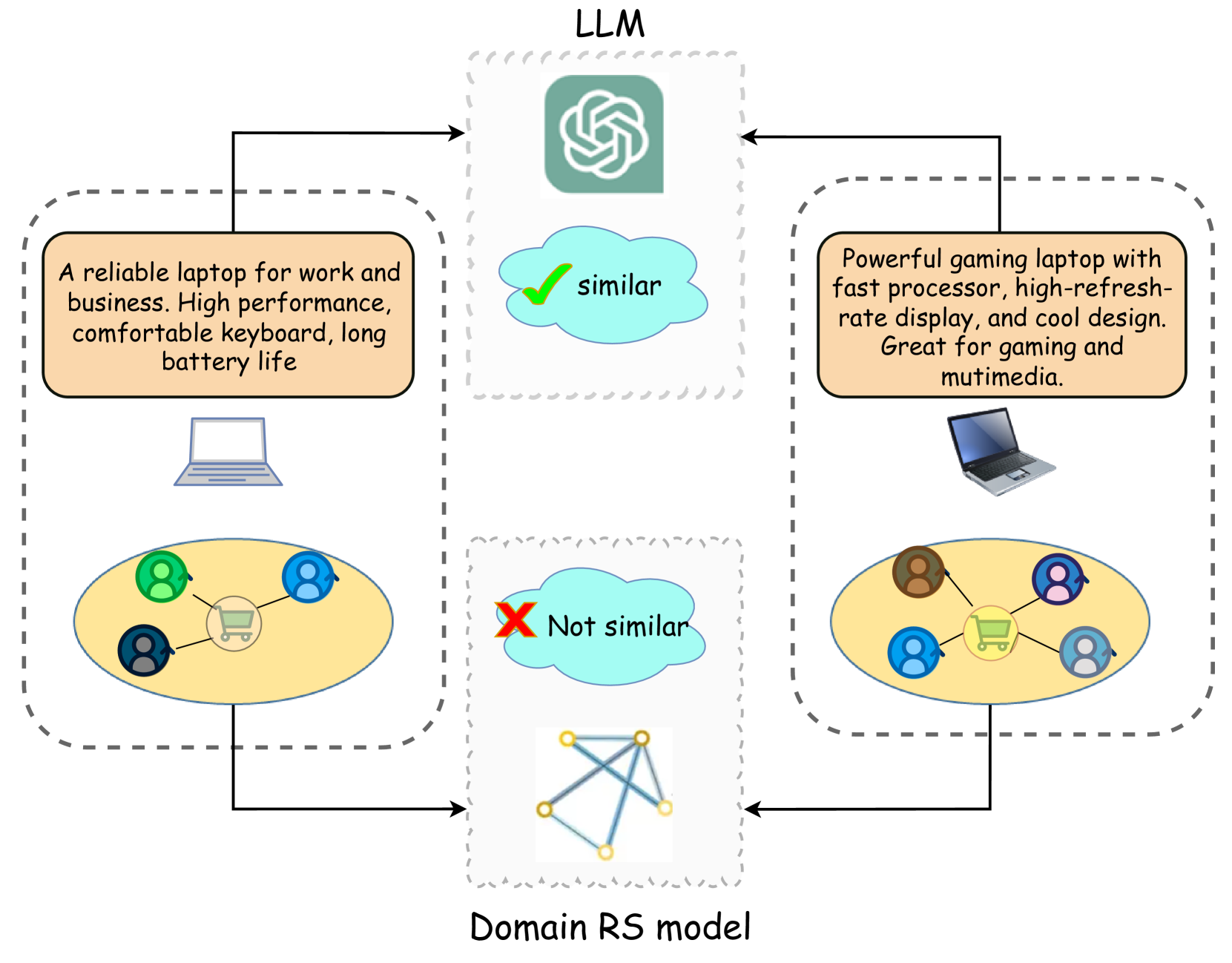
Large Language Models (LLMs) are increasingly prominent in the recommendation systems domain. Existing studies usually utilize in-context learning or supervised fine-tuning on task-specific data to align LLMs into recommendations. However, the substantial bias in semantic spaces between language processing tasks and recommendation tasks poses a nonnegligible challenge. Specifically, without the adequate capturing ability of collaborative information, existing modeling paradigms struggle to capture behavior patterns within community groups, leading to LLMs' ineffectiveness in discerning implicit interaction semantic in recommendation scenarios. To address this, we consider enhancing the learning capability of language model-driven recommendation models for structured data, specifically by utilizing interaction graphs rich in collaborative semantics. We propose a Graph-Aware Learning for Language Model-Driven Recommendations (GAL-Rec). GAL-Rec enhances the understanding of user-item collaborative semantics by imitating the intent of Graph Neural Networks (GNNs) to aggregate multi-hop information, thereby fully exploiting the substantial learning capacity of LLMs to independently address the complex graphs in the recommendation system. Sufficient experimental results on three real-world datasets demonstrate that GAL-Rec significantly enhances the comprehension of collaborative semantics, and improves recommendation performance.
6/21/2024
MMGRec: Multimodal Generative Recommendation with Transformer Model
Han Liu, Yinwei Wei, Xuemeng Song, Weili Guan, Yuan-Fang Li, Liqiang Nie
0
0
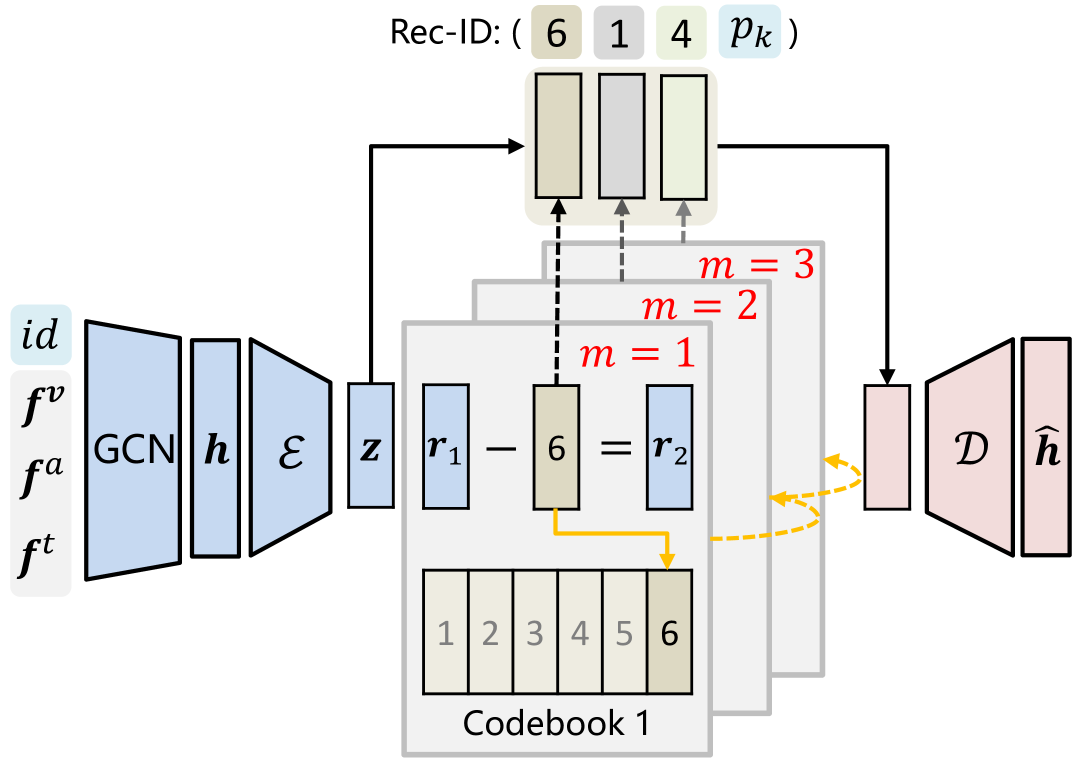
Multimodal recommendation aims to recommend user-preferred candidates based on her/his historically interacted items and associated multimodal information. Previous studies commonly employ an embed-and-retrieve paradigm: learning user and item representations in the same embedding space, then retrieving similar candidate items for a user via embedding inner product. However, this paradigm suffers from inference cost, interaction modeling, and false-negative issues. Toward this end, we propose a new MMGRec model to introduce a generative paradigm into multimodal recommendation. Specifically, we first devise a hierarchical quantization method Graph RQ-VAE to assign Rec-ID for each item from its multimodal and CF information. Consisting of a tuple of semantically meaningful tokens, Rec-ID serves as the unique identifier of each item. Afterward, we train a Transformer-based recommender to generate the Rec-IDs of user-preferred items based on historical interaction sequences. The generative paradigm is qualified since this model systematically predicts the tuple of tokens identifying the recommended item in an autoregressive manner. Moreover, a relation-aware self-attention mechanism is devised for the Transformer to handle non-sequential interaction sequences, which explores the element pairwise relation to replace absolute positional encoding. Extensive experiments evaluate MMGRec's effectiveness compared with state-of-the-art methods.
4/26/2024
🛸
Multimodal Pretraining and Generation for Recommendation: A Tutorial
Jieming Zhu, Chuhan Wu, Rui Zhang, Zhenhua Dong
0
0
Personalized recommendation stands as a ubiquitous channel for users to explore information or items aligned with their interests. Nevertheless, prevailing recommendation models predominantly rely on unique IDs and categorical features for user-item matching. While this ID-centric approach has witnessed considerable success, it falls short in comprehensively grasping the essence of raw item contents across diverse modalities, such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, particularly in the realm of multimedia services like news, music, and short-video platforms. The recent surge in pretraining and generation techniques presents both opportunities and challenges in the development of multimodal recommender systems. This tutorial seeks to provide a thorough exploration of the latest advancements and future trajectories in multimodal pretraining and generation techniques within the realm of recommender systems. The tutorial comprises three parts: multimodal pretraining, multimodal generation, and industrial applications and open challenges in the field of recommendation. Our target audience encompasses scholars, practitioners, and other parties interested in this domain. By providing a succinct overview of the field, we aspire to facilitate a swift understanding of multimodal recommendation and foster meaningful discussions on the future development of this evolving landscape.
5/14/2024
NoteLLM-2: Multimodal Large Representation Models for Recommendation
Chao Zhang, Haoxin Zhang, Shiwei Wu, Di Wu, Tong Xu, Yan Gao, Yao Hu, Enhong Chen
0
0
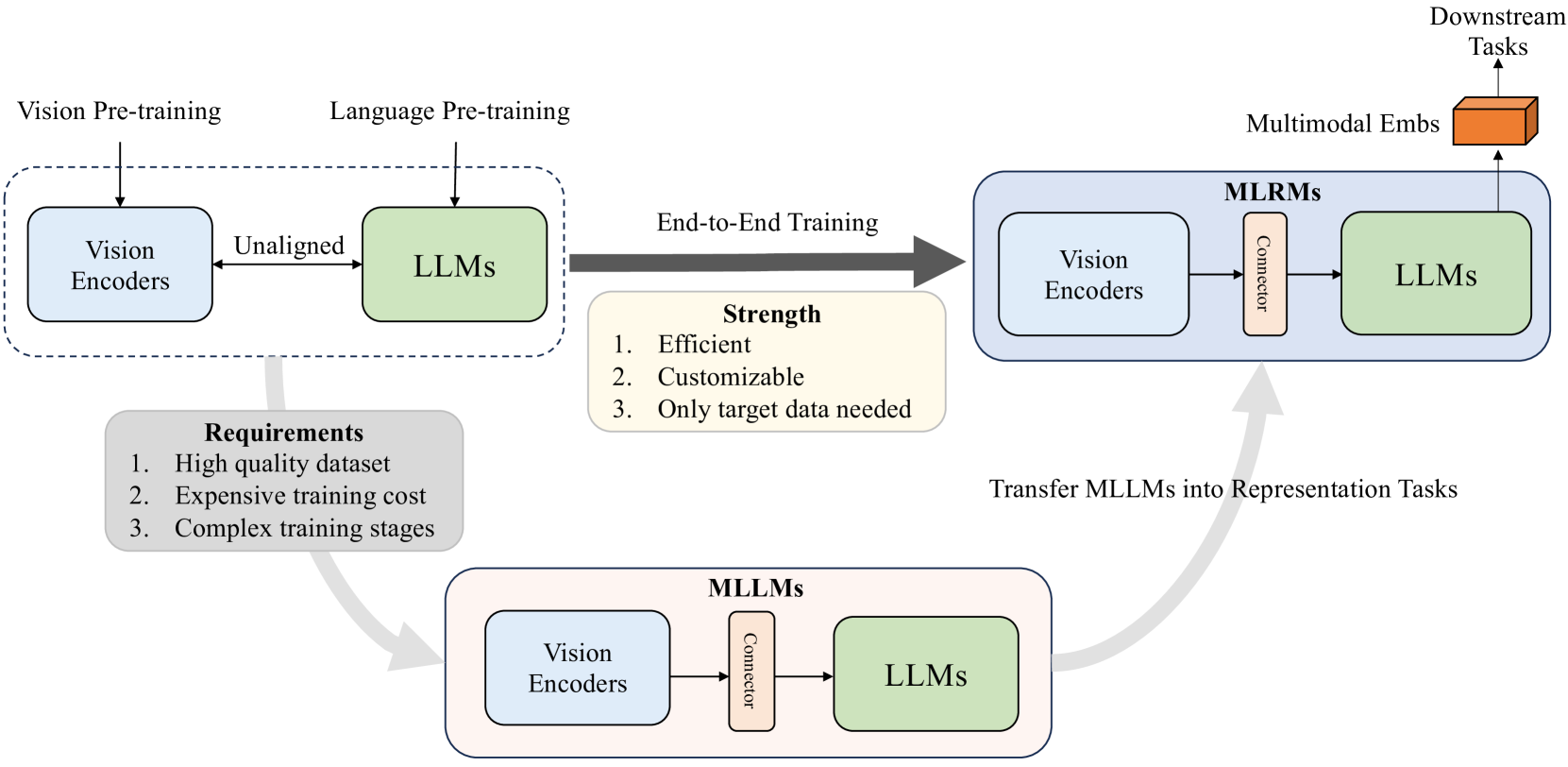
Large Language Models (LLMs) have demonstrated exceptional text understanding. Existing works explore their application in text embedding tasks. However, there are few works utilizing LLMs to assist multimodal representation tasks. In this work, we investigate the potential of LLMs to enhance multimodal representation in multimodal item-to-item (I2I) recommendations. One feasible method is the transfer of Multimodal Large Language Models (MLLMs) for representation tasks. However, pre-training MLLMs usually requires collecting high-quality, web-scale multimodal data, resulting in complex training procedures and high costs. This leads the community to rely heavily on open-source MLLMs, hindering customized training for representation scenarios. Therefore, we aim to design an end-to-end training method that customizes the integration of any existing LLMs and vision encoders to construct efficient multimodal representation models. Preliminary experiments show that fine-tuned LLMs in this end-to-end method tend to overlook image content. To overcome this challenge, we propose a novel training framework, NoteLLM-2, specifically designed for multimodal representation. We propose two ways to enhance the focus on visual information. The first method is based on the prompt viewpoint, which separates multimodal content into visual content and textual content. NoteLLM-2 adopts the multimodal In-Content Learning method to teach LLMs to focus on both modalities and aggregate key information. The second method is from the model architecture, utilizing a late fusion mechanism to directly fuse visual information into textual information. Extensive experiments have been conducted to validate the effectiveness of our method.
5/28/2024