PMG : Personalized Multimodal Generation with Large Language Models
2404.08677
0
0
Abstract
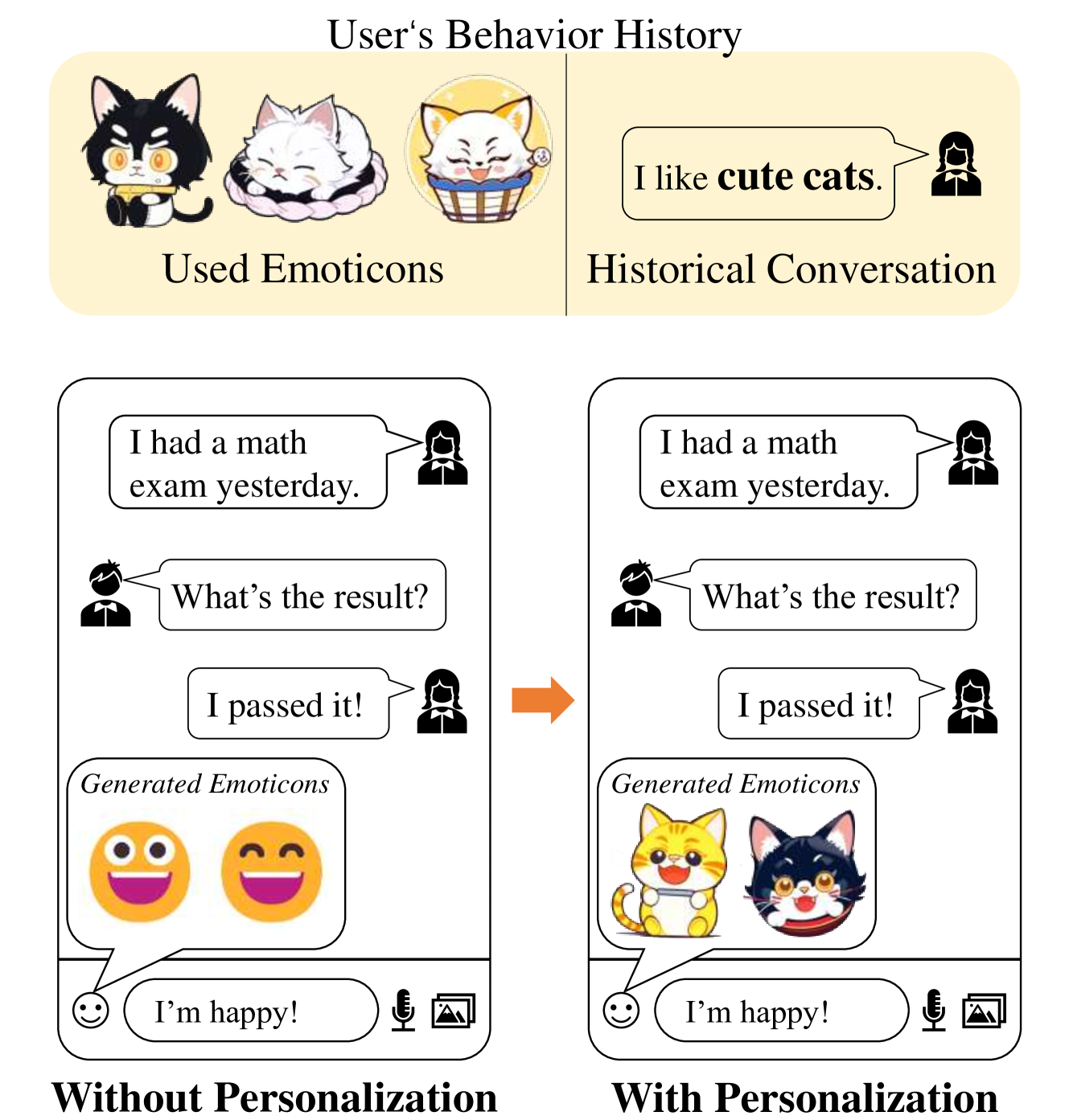
The emergence of large language models (LLMs) has revolutionized the capabilities of text comprehension and generation. Multi-modal generation attracts great attention from both the industry and academia, but there is little work on personalized generation, which has important applications such as recommender systems. This paper proposes the first method for personalized multimodal generation using LLMs, showcases its applications and validates its performance via an extensive experimental study on two datasets. The proposed method, Personalized Multimodal Generation (PMG for short) first converts user behaviors (e.g., clicks in recommender systems or conversations with a virtual assistant) into natural language to facilitate LLM understanding and extract user preference descriptions. Such user preferences are then fed into a generator, such as a multimodal LLM or diffusion model, to produce personalized content. To capture user preferences comprehensively and accurately, we propose to let the LLM output a combination of explicit keywords and implicit embeddings to represent user preferences. Then the combination of keywords and embeddings are used as prompts to condition the generator. We optimize a weighted sum of the accuracy and preference scores so that the generated content has a good balance between them. Compared to a baseline method without personalization, PMG has a significant improvement on personalization for up to 8% in terms of LPIPS while retaining the accuracy of generation.
Create account to get full access
Overview
• This paper introduces a novel approach called Personalized Multimodal Generation (PMG) that uses large language models to generate personalized multimodal content.
• PMG aims to address the challenge of creating diverse and engaging multimodal content tailored to individual users' preferences and needs.
• The approach leverages the power of large language models, which have shown remarkable capabilities in natural language processing and generation, and extends them to handle multimodal inputs and outputs.
Plain English Explanation
• PMG is a system that can create personalized content, like images, text, or even videos, based on an individual user's preferences and interests.
• It uses powerful language models, which are AI systems trained on vast amounts of text data, to understand and generate human-like language.
• PMG takes this a step further by allowing these language models to also work with other types of media, like images and videos, to produce unique, customized content for each user.
• This is useful for applications like personalized recommendation systems, where the system can generate content tailored to each individual's tastes, or personalized chatbots that can have more natural, engaging conversations.
Technical Explanation
• PMG builds on recent advancements in multimodal large language models that can handle and generate content across different modalities like text, images, and video.
• The key innovation of PMG is its ability to personalize the multimodal content generation process, taking into account the user's preferences, interests, and context.
• This is achieved through a modular architecture that includes a user-specific encoding module, a multimodal fusion module, and a personalized generation module.
• The user-specific encoding module learns a compact representation of the user's preferences, which is then used to condition the multimodal fusion and generation processes.
• The researchers explore different optimization techniques to effectively personalize the large language model, including gradient-based fine-tuning and prompt-based approaches.
Critical Analysis
• The paper provides a compelling approach to personalized multimodal generation, addressing an important challenge in the field of recommender systems and content creation.
• However, the authors acknowledge that further research is needed to fully understand the limits and potential biases of the PMG system, particularly when it comes to handling diverse user preferences and generating high-quality, unbiased content.
• Additionally, the computational and memory requirements of the personalization modules may pose challenges for deploying PMG at scale, especially on resource-constrained devices.
• It would be interesting to see how PMG performs compared to other personalization approaches, both in terms of content quality and user satisfaction, and how it can be extended to handle a wider range of modalities and applications.
Conclusion
• The PMG approach presented in this paper represents an important step forward in the field of personalized multimodal generation, leveraging the power of large language models to create tailored content for individual users.
• The ability to generate personalized multimedia content has significant implications for a wide range of applications, from personalized recommendation systems to personalized chatbots and beyond.
• While further research is needed to address the challenges and limitations of the PMG system, this work demonstrates the potential of large language models to enable more engaging and user-centric multimodal experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLMs Meet Multimodal Generation and Editing: A Survey
Yingqing He, Zhaoyang Liu, Jingye Chen, Zeyue Tian, Hongyu Liu, Xiaowei Chi, Runtao Liu, Ruibin Yuan, Yazhou Xing, Wenhai Wang, Jifeng Dai, Yong Zhang, Wei Xue, Qifeng Liu, Yike Guo, Qifeng Chen
0
0
With the recent advancement in large language models (LLMs), there is a growing interest in combining LLMs with multimodal learning. Previous surveys of multimodal large language models (MLLMs) mainly focus on multimodal understanding. This survey elaborates on multimodal generation and editing across various domains, comprising image, video, 3D, and audio. Specifically, we summarize the notable advancements with milestone works in these fields and categorize these studies into LLM-based and CLIP/T5-based methods. Then, we summarize the various roles of LLMs in multimodal generation and exhaustively investigate the critical technical components behind these methods and the multimodal datasets utilized in these studies. Additionally, we dig into tool-augmented multimodal agents that can leverage existing generative models for human-computer interaction. Lastly, we discuss the advancements in the generative AI safety field, investigate emerging applications, and discuss future prospects. Our work provides a systematic and insightful overview of multimodal generation and processing, which is expected to advance the development of Artificial Intelligence for Generative Content (AIGC) and world models. A curated list of all related papers can be found at https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation
6/11/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
Verbalized Probabilistic Graphical Modeling with Large Language Models
Hengguan Huang, Xing Shen, Songtao Wang, Dianbo Liu, Hao Wang
0
0
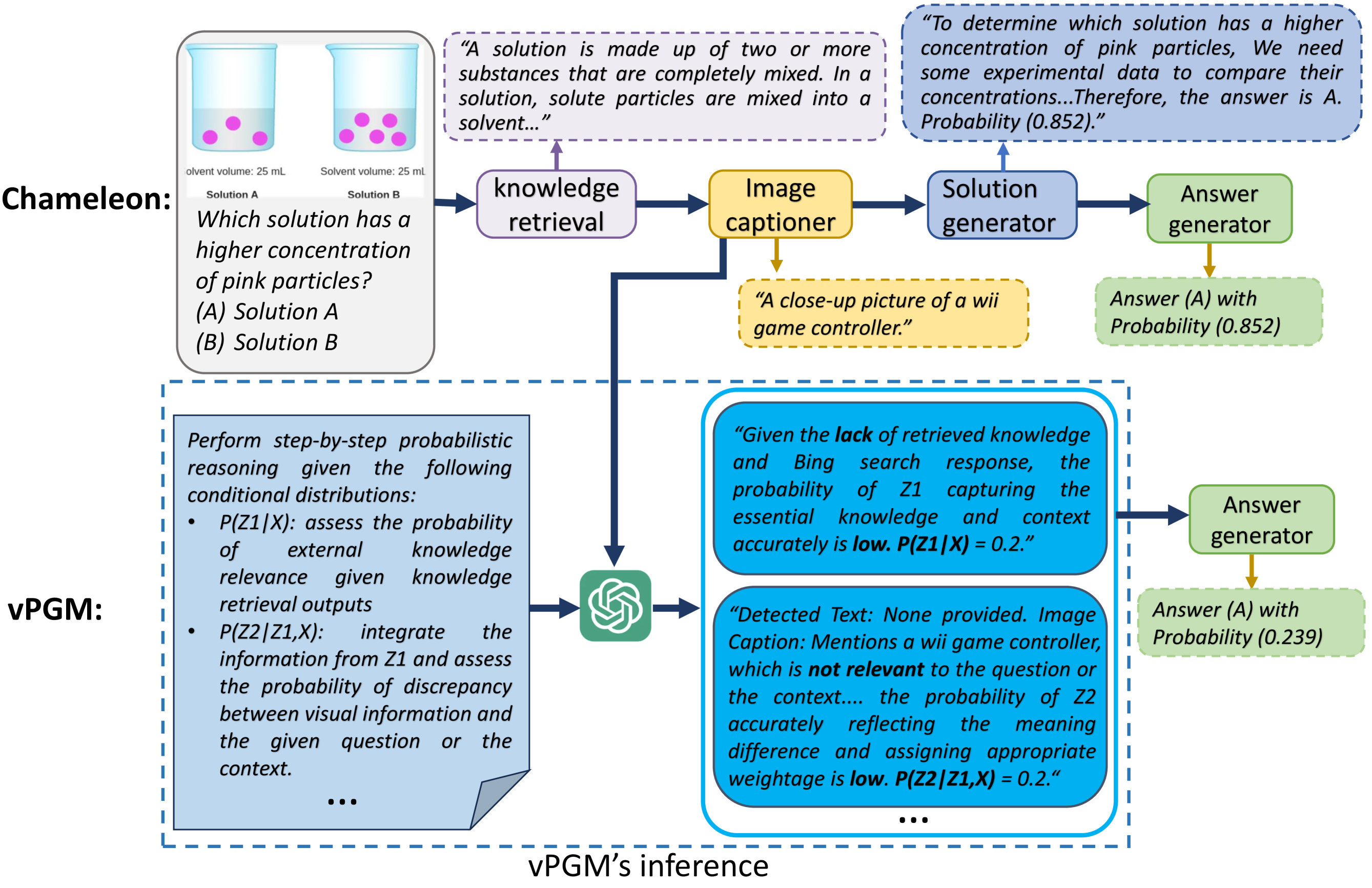
Faced with complex problems, the human brain demonstrates a remarkable capacity to transcend sensory input and form latent understandings of perceived world patterns. However, this cognitive capacity is not explicitly considered or encoded in current large language models (LLMs). As a result, LLMs often struggle to capture latent structures and model uncertainty in complex compositional reasoning tasks. This work introduces a novel Bayesian prompting approach that facilitates training-free Bayesian inference with LLMs by using a verbalized Probabilistic Graphical Model (PGM). While traditional Bayesian approaches typically depend on extensive data and predetermined mathematical structures for learning latent factors and dependencies, our approach efficiently reasons latent variables and their probabilistic dependencies by prompting LLMs to adhere to Bayesian principles. We evaluated our model on several compositional reasoning tasks, both close-ended and open-ended. Our results indicate that the model effectively enhances confidence elicitation and text generation quality, demonstrating its potential to improve AI language understanding systems, especially in modeling uncertainty.
6/11/2024
💬
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
0
0
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
4/3/2024