MMM: Multi-Layer Multi-Residual Multi-Stream Discrete Speech Representation from Self-supervised Learning Model

0
🗣️
Sign in to get full access
Overview
- The paper presents a novel self-supervised learning model called MMM (Multi-Layer Multi-Residual Multi-Stream Discrete Speech Representation) for learning discrete speech representations.
- MMM uses a multi-stream architecture with multiple residual connections to capture diverse speech features, and learns discrete speech tokens in a hierarchical manner.
- The model is evaluated on various speech tasks, including speech recognition, speaker identification, and emotion recognition, and achieves state-of-the-art performance.
Plain English Explanation
The researchers have developed a new machine learning model called MMM that can learn to understand and represent speech data in a very detailed way, without requiring a lot of human-labeled training data. This is done through a process called "self-supervised learning," where the model learns by exploring the patterns in the speech data itself, rather than being trained on manually annotated examples.
The key innovation in MMM is its multi-stream architecture, which means the model has multiple parallel 'streams' that each focus on different aspects of the speech signal, like the pitch, the tone, the rhythm, and so on. These streams are connected through "residual connections," which help the model build a rich and comprehensive representation of the speech. Additionally, MMM learns these representations in a hierarchical way, starting from low-level features and building up to higher-level abstractions.
By learning these detailed speech representations in a self-supervised way, MMM is able to achieve impressive performance on a variety of speech-related tasks, like speech recognition, speaker identification, and emotion detection. This suggests the model has captured meaningful and generalizable information about speech that can be useful for many real-world applications.
Technical Explanation
The MMM model uses a self-supervised learning approach to learn discrete speech representations from raw audio data. The key innovations in the model architecture include:
-
Multi-Stream Design: MMM has multiple parallel "streams" that each focus on extracting different types of speech features, such as pitch, timbre, and rhythm. This allows the model to build a more comprehensive representation of the speech signal.
-
Hierarchical Learning: MMM learns the speech representations in a hierarchical manner, starting from low-level acoustic features and progressively building up to higher-level, more abstract representations. This mirrors the way humans process speech.
-
Residual Connections: The model uses residual connections between the layers and streams, which helps to retain important information and facilitates the learning of deeper, more complex representations.
-
Discrete Tokens: The final output of MMM is a sequence of discrete speech tokens, which can be seen as a compressed, quantized representation of the original speech signal. This discrete representation is shown to be effective for downstream speech tasks.
The researchers evaluate MMM on a range of speech tasks, including automatic speech recognition, speaker identification, and emotion recognition. The model achieves state-of-the-art performance, demonstrating the effectiveness of the self-supervised learning approach and the rich speech representations captured by the multi-stream, multi-residual architecture.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the MMM model, exploring its performance on a diverse set of speech tasks. However, a few potential limitations or areas for further research are worth noting:
-
Dataset Scope: The model is evaluated on relatively standard speech datasets, but it would be interesting to see how it performs on more challenging, real-world speech data, such as conversational or accented speech.
-
Computational Complexity: While the multi-stream and hierarchical design of MMM likely contributes to its strong performance, these architectural choices also increase the model's computational complexity and training requirements. The authors could further explore ways to balance model capacity and efficiency.
-
Interpretability: As with many deep learning models, the inner workings of MMM may be difficult to interpret. Providing more insights into how the different streams and representations contribute to the overall performance could help users better understand the model's strengths and limitations.
-
Potential Bias and Fairness: The authors do not discuss potential issues related to bias or fairness in the model's performance across different demographic groups. This is an important consideration for real-world speech applications.
Overall, the MMM model represents a significant advancement in self-supervised speech representation learning, and the researchers have done a commendable job in rigorously evaluating its capabilities. Addressing the points above could further strengthen the research and its potential impact.
Conclusion
The MMM model introduced in this paper demonstrates the power of self-supervised learning for extracting rich and generalizable speech representations. By using a multi-stream, multi-residual architecture, the model is able to capture diverse speech features in a hierarchical manner, leading to state-of-the-art performance on a variety of speech-related tasks.
This work contributes to the growing body of research on self-supervised speech models and discrete speech representations, which have the potential to dramatically improve the performance and efficiency of speech applications, while reducing the need for large, manually-labeled datasets. As the field continues to evolve, the insights and techniques from this paper can help pave the way for even more advanced and capable speech understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
MMM: Multi-Layer Multi-Residual Multi-Stream Discrete Speech Representation from Self-supervised Learning Model
Jiatong Shi, Xutai Ma, Hirofumi Inaguma, Anna Sun, Shinji Watanabe
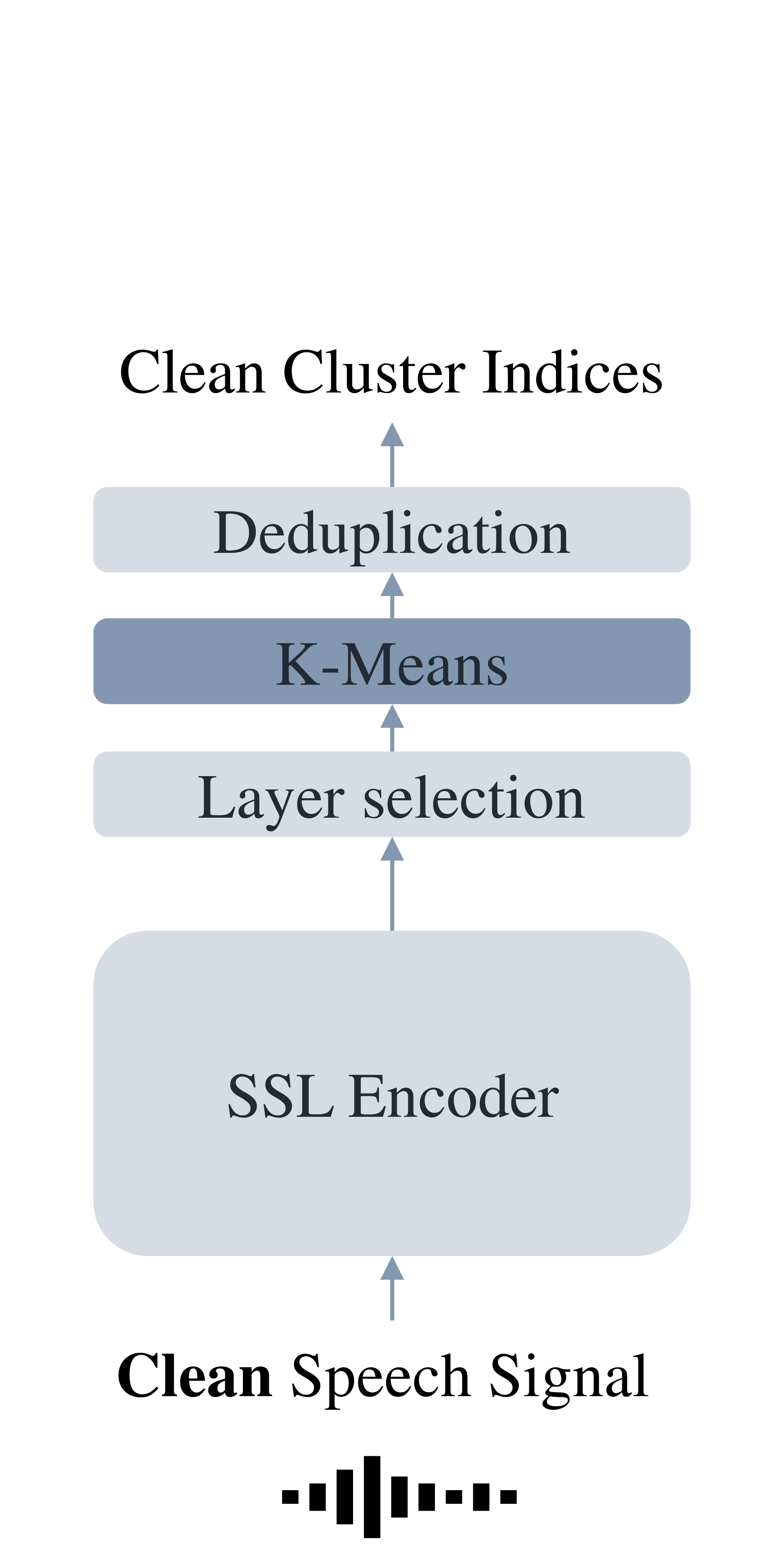
Speech discrete representation has proven effective in various downstream applications due to its superior compression rate of the waveform, fast convergence during training, and compatibility with other modalities. Discrete units extracted from self-supervised learning (SSL) models have emerged as a prominent approach for obtaining speech discrete representation. However, while discrete units have shown effectiveness compared to spectral features, they still lag behind continuous SSL representations. In this work, we propose MMM, a multi-layer multi-residual multi-stream discrete units extraction method from SSL. Specifically, we introduce iterative residual vector quantization with K-means for different layers in an SSL model to extract multi-stream speech discrete representation. Through extensive experiments in speech recognition, speech resynthesis, and text-to-speech, we demonstrate the proposed MMM can surpass or on-par with neural codec's performance under various conditions.
Read more6/17/2024
0
Efficient Extraction of Noise-Robust Discrete Units from Self-Supervised Speech Models
Jakob Poncelet, Yujun Wang, Hugo Van hamme
Continuous speech can be converted into a discrete sequence by deriving discrete units from the hidden features of self-supervised learned (SSL) speech models. Although SSL models are becoming larger and trained on more data, they are often sensitive to real-life distortions like additive noise or reverberation, which translates to a shift in discrete units. We propose a parameter-efficient approach to generate noise-robust discrete units from pre-trained SSL models by training a small encoder-decoder model, with or without adapters, to simultaneously denoise and discretise the hidden features of the SSL model. The model learns to generate a clean discrete sequence for a noisy utterance, conditioned on the SSL features. The proposed denoiser outperforms several pre-training methods on the tasks of noisy discretisation and noisy speech recognition, and can be finetuned to the target environment with a few recordings of unlabeled target data.
Read more9/5/2024
🗣️
0
SSHR: Leveraging Self-supervised Hierarchical Representations for Multilingual Automatic Speech Recognition
Hongfei Xue, Qijie Shao, Kaixun Huang, Peikun Chen, Jie Liu, Lei Xie
Multilingual automatic speech recognition (ASR) systems have garnered attention for their potential to extend language coverage globally. While self-supervised learning (SSL) models, like MMS, have demonstrated their effectiveness in multilingual ASR, it is worth noting that various layers' representations potentially contain distinct information that has not been fully leveraged. In this study, we propose a novel method that leverages self-supervised hierarchical representations (SSHR) to fine-tune the MMS model. We first analyze the different layers of MMS and show that the middle layers capture language-related information, and the high layers encode content-related information, which gradually decreases in the final layers. Then, we extract a language-related frame from correlated middle layers and guide specific language extraction through self-attention mechanisms. Additionally, we steer the model toward acquiring more content-related information in the final layers using our proposed Cross-CTC. We evaluate SSHR on two multilingual datasets, Common Voice and ML-SUPERB, and the experimental results demonstrate that our method achieves state-of-the-art performance.
Read more4/30/2024

0
Discrete Multimodal Transformers with a Pretrained Large Language Model for Mixed-Supervision Speech Processing
Viet Anh Trinh, Rosy Southwell, Yiwen Guan, Xinlu He, Zhiyong Wang, Jacob Whitehill
Recent work on discrete speech tokenization has paved the way for models that can seamlessly perform multiple tasks across modalities, e.g., speech recognition, text to speech, speech to speech translation. Moreover, large language models (LLMs) pretrained from vast text corpora contain rich linguistic information that can improve accuracy in a variety of tasks. In this paper, we present a decoder-only Discrete Multimodal Language Model (DMLM), which can be flexibly applied to multiple tasks (ASR, T2S, S2TT, etc.) and modalities (text, speech, vision). We explore several critical aspects of discrete multi-modal models, including the loss function, weight initialization, mixed training supervision, and codebook. Our results show that DMLM benefits significantly, across multiple tasks and datasets, from a combination of supervised and unsupervised training. Moreover, for ASR, it benefits from initializing DMLM from a pretrained LLM, and from a codebook derived from Whisper activations.
Read more6/26/2024