MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
2311.16502
0
0
🤔
Abstract
We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. These questions span 30 subjects and 183 subfields, comprising 30 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of 14 open-source LMMs as well as the proprietary GPT-4V(ision) and Gemini highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V and Gemini Ultra only achieve accuracies of 56% and 59% respectively, indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
Create account to get full access
Overview
- Introduces a new benchmark called MMMU (Massive Multimodal Multidisciplinary University) to evaluate large language models on complex, college-level tasks
- MMMU includes over 11,500 carefully curated multimodal questions from college exams, quizzes, and textbooks across six core disciplines
- Questions cover a wide range of subjects and subfields, and include diverse image types like charts, diagrams, and chemical structures
- Aims to challenge models to perform tasks similar to what human experts would face, going beyond existing benchmarks
Plain English Explanation
MMMU is a new benchmark designed to test how well large language models can handle complex, college-level tasks that require knowledge from multiple fields. Unlike other benchmarks, MMMU includes over 11,000 questions pulled from real college materials, covering topics like Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering.
These questions require models to not only understand the text, but also interpret different types of visual information like charts, diagrams, and chemical structures. The goal is to see how well these models can perform tasks that are typically done by human experts, rather than just simple question-answering.
Technical Explanation
MMMU was created by collecting 11,500 multimodal questions from college exams, quizzes, and textbooks across six core disciplines. These questions cover 30 subjects and 183 different subfields, and involve 30 distinct types of visual information, ranging from common formats like charts and diagrams to more specialized content like music sheets and chemical structures.
The researchers evaluated 14 open-source large language models, as well as two proprietary models - GPT-4V(ision) and Gemini. Even the most advanced models, GPT-4V and Gemini Ultra, only achieved accuracies of 56% and 59% respectively on the MMMU benchmark. This indicates that current state-of-the-art models still struggle with the level of knowledge and reasoning required for these complex, college-level tasks.
Critical Analysis
The MMMU benchmark represents an important step forward in evaluating the capabilities of large language models. By focusing on advanced perception and reasoning with domain-specific knowledge, it challenges models to perform tasks that are more analogous to what human experts would face, going beyond simple question-answering.
However, the researchers acknowledge that MMMU is still limited in scope, covering only six core disciplines. There may be opportunities to expand the benchmark to include an even wider range of subjects and question types. Additionally, the researchers note that the dataset curation process, while meticulous, could introduce some biases or inconsistencies that could impact model performance.
Furthermore, the relatively low accuracies achieved by even the most advanced models suggest that there is still significant room for improvement in developing multimodal foundation models capable of expert-level reasoning and problem-solving. Researchers and developers will need to continue pushing the boundaries of what is possible with large language models to make progress towards true artificial general intelligence.
Conclusion
The MMMU benchmark represents a significant advancement in the field of multimodal AI evaluation. By providing a challenging, college-level dataset that covers a wide range of disciplines and visual information types, it pushes models to demonstrate more sophisticated understanding and reasoning abilities. The low performance of even state-of-the-art models on this benchmark highlights the substantial challenges that remain in developing truly capable artificial general intelligence systems. Researchers and developers will need to continue innovating to create the next generation of multimodal foundation models that can excel at the types of complex, real-world tasks captured by MMMU.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CMMU: A Benchmark for Chinese Multi-modal Multi-type Question Understanding and Reasoning
Zheqi He, Xinya Wu, Pengfei Zhou, Richeng Xuan, Guang Liu, Xi Yang, Qiannan Zhu, Hua Huang
0
0
Multi-modal large language models(MLLMs) have achieved remarkable progress and demonstrated powerful knowledge comprehension and reasoning abilities. However, the mastery of domain-specific knowledge, which is essential for evaluating the intelligence of MLLMs, continues to be a challenge. Current multi-modal benchmarks for domain-specific knowledge concentrate on multiple-choice questions and are predominantly available in English, which imposes limitations on the comprehensiveness of the evaluation. To this end, we introduce CMMU, a novel benchmark for multi-modal and multi-type question understanding and reasoning in Chinese. CMMU consists of 3,603 questions in 7 subjects, covering knowledge from primary to high school. The questions can be categorized into 3 types: multiple-choice, multiple-response, and fill-in-the-blank, bringing greater challenges to MLLMs. In addition, we propose an evaluation strategy called Positional Error Variance for assessing multiple-choice questions. The strategy aims to perform a quantitative analysis of position bias. We evaluate seven open-source MLLMs along with GPT4-V, Gemini-Pro, and Qwen-VL-Plus. The results demonstrate that CMMU poses a significant challenge to the recent MLLMs. The data and code are available at https://github.com/FlagOpen/CMMU.
5/9/2024

M4U: Evaluating Multilingual Understanding and Reasoning for Large Multimodal Models
Hongyu Wang, Jiayu Xu, Senwei Xie, Ruiping Wang, Jialin Li, Zhaojie Xie, Bin Zhang, Chuyan Xiong, Xilin Chen
0
0
Multilingual multimodal reasoning is a core component in achieving human-level intelligence. However, most existing benchmarks for multilingual multimodal reasoning struggle to differentiate between models of varying performance; even language models without visual capabilities can easily achieve high scores. This leaves a comprehensive evaluation of leading multilingual multimodal models largely unexplored. In this work, we introduce M4U, a novel and challenging benchmark for assessing the capability of multi-discipline multilingual multimodal understanding and reasoning. M4U contains 8,931 samples covering 64 disciplines across 16 subfields in Science, Engineering, and Healthcare in Chinese, English, and German. Using M4U, we conduct extensive evaluations of 21 leading Large Multimodal Models (LMMs) and Large Language Models (LLMs) with external tools. The evaluation results show that the state-of-the-art model, GPT-4o, achieves only 47.6% average accuracy on M4U. Additionally, we observe that the leading LMMs exhibit significant language preferences. Our in-depth analysis indicates that leading LMMs, including GPT-4o, suffer performance degradation when prompted with cross-lingual multimodal questions, such as images with key textual information in Chinese while the question is in German. We believe that M4U can serve as a crucial tool for systematically evaluating LMMs based on their multilingual multimodal reasoning capabilities and monitoring their development. The homepage, codes and data are public available.
5/27/2024
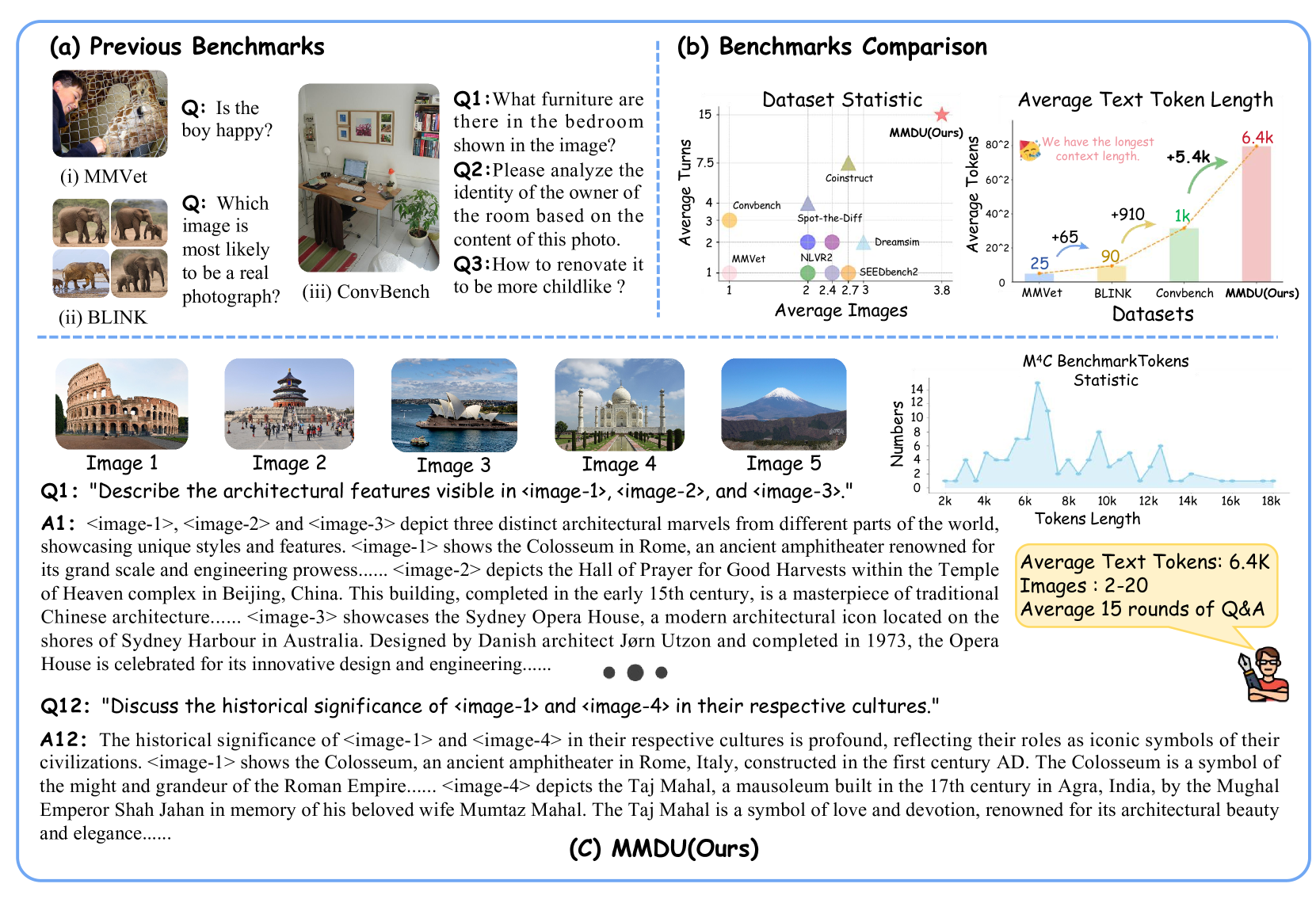
MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs
Ziyu Liu, Tao Chu, Yuhang Zang, Xilin Wei, Xiaoyi Dong, Pan Zhang, Zijian Liang, Yuanjun Xiong, Yu Qiao, Dahua Lin, Jiaqi Wang
0
0
Generating natural and meaningful responses to communicate with multi-modal human inputs is a fundamental capability of Large Vision-Language Models(LVLMs). While current open-source LVLMs demonstrate promising performance in simplified scenarios such as single-turn single-image input, they fall short in real-world conversation scenarios such as following instructions in a long context history with multi-turn and multi-images. Existing LVLM benchmarks primarily focus on single-choice questions or short-form responses, which do not adequately assess the capabilities of LVLMs in real-world human-AI interaction applications. Therefore, we introduce MMDU, a comprehensive benchmark, and MMDU-45k, a large-scale instruction tuning dataset, designed to evaluate and improve LVLMs' abilities in multi-turn and multi-image conversations. We employ the clustering algorithm to ffnd the relevant images and textual descriptions from the open-source Wikipedia and construct the question-answer pairs by human annotators with the assistance of the GPT-4o model. MMDU has a maximum of 18k image+text tokens, 20 images, and 27 turns, which is at least 5x longer than previous benchmarks and poses challenges to current LVLMs. Our in-depth analysis of 15 representative LVLMs using MMDU reveals that open-source LVLMs lag behind closed-source counterparts due to limited conversational instruction tuning data. We demonstrate that ffne-tuning open-source LVLMs on MMDU-45k signiffcantly address this gap, generating longer and more accurate conversations, and improving scores on MMDU and existing benchmarks (MMStar: +1.1%, MathVista: +1.5%, ChartQA:+1.2%). Our contributions pave the way for bridging the gap between current LVLM models and real-world application demands. This project is available at https://github.com/Liuziyu77/MMDU.
6/18/2024

MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, Wenhu Chen
0
0
In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities. This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates the trivial and noisy questions in MMLU. Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16% to 33% compared to MMLU but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5% in MMLU to just 2% in MMLU-Pro. Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our assessments confirm that MMLU-Pro is a more discriminative benchmark to better track progress in the field.
6/26/2024