MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
2406.09411
0
0

Abstract
We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). Comprising 11,264 images and 2,600 multiple-choice questions, MuirBench is created in a pairwise manner, where each standard instance is paired with an unanswerable variant that has minimal semantic differences, in order for a reliable assessment. Evaluated upon 20 recent multi-modal LLMs, our results reveal that even the best-performing models like GPT-4o and Gemini Pro find it challenging to solve MuirBench, achieving 68.0% and 49.3% in accuracy. Open-source multimodal LLMs trained on single images can hardly generalize to multi-image questions, hovering below 33.3% in accuracy. These results highlight the importance of MuirBench in encouraging the community to develop multimodal LLMs that can look beyond a single image, suggesting potential pathways for future improvements.
Create account to get full access
Overview
• The paper introduces MuirBench, a comprehensive benchmark for evaluating the robustness of multi-image understanding models. • MuirBench includes a diverse dataset of image pairs with a range of relationships, as well as challenging test cases that assess key capabilities like relational reasoning and compositional generalization. • The benchmark aims to spur progress in building multi-image models that can handle real-world complexity and generalize beyond narrow training distributions.
Plain English Explanation
The researchers have created a new benchmark called MuirBench to test the abilities of AI systems that work with multiple images at once. This is an important area of AI research, as being able to understand the relationships between images is crucial for many real-world applications like visual reasoning and scene understanding.
MuirBench includes a large and diverse dataset of image pairs, with various types of relationships between the images, such as spatial, semantic, and causal connections. The benchmark also includes challenging test cases that assess the models' ability to reason about these relationships in a robust and generalizable way, going beyond simple pattern matching.
By providing this comprehensive evaluation platform, the researchers hope to accelerate progress in building multi-image understanding models that can handle the complexity of the real world, rather than just performing well on narrow, curated datasets. This could lead to significant advances in areas like visual reasoning, multimodal perception, and multi-modal reasoning.
Technical Explanation
The paper introduces MuirBench, a new benchmark for evaluating the robustness of multi-image understanding models. MuirBench consists of a large, diverse dataset of image pairs with a range of relationships, including spatial, semantic, and causal connections. The benchmark also includes a suite of challenging test cases designed to assess key capabilities such as relational reasoning and compositional generalization.
The dataset is constructed by carefully curating image pairs from various sources, including existing visual relationship datasets, and annotating them with detailed relationship labels. The test cases are designed to go beyond simple pattern matching, presenting models with novel compositions of familiar concepts and requiring them to reason about higher-level relationships between the images.
By providing this comprehensive evaluation platform, the researchers aim to spur progress in building multi-image understanding models that can handle the complexity and diversity of real-world visual scenes. Compared to existing benchmarks that focus on single-image tasks or simple pairwise relationships, MuirBench is designed to drive the development of more robust and generalizable multi-image understanding capabilities.
Critical Analysis
The MuirBench paper presents a well-designed and much-needed benchmark for the field of multi-image understanding. The researchers have thoughtfully curated a diverse dataset and crafted challenging test cases that go beyond the limitations of existing benchmarks.
One potential limitation of the benchmark is the reliance on human-annotated relationship labels, which could introduce biases or inconsistencies. The researchers acknowledge this and suggest exploring automated or semi-automated approaches for label generation in future iterations of the benchmark.
Additionally, while MuirBench covers a broad range of relationship types, there may be other important dimensions of multi-image understanding, such as temporal or causal relationships, that are not fully explored. Expanding the benchmark to encompass a wider range of multimodal and multitemporal relationships could further strengthen its utility.
Overall, the MuirBench paper presents a valuable contribution to the field of multi-image understanding, and the availability of this comprehensive evaluation platform is likely to drive significant progress in building more robust and generalizable models for real-world visual reasoning tasks. As the field continues to evolve, it will be important to monitor the benchmark's performance and update it to keep pace with the advancing state of the art.
Conclusion
The MuirBench paper introduces a comprehensive benchmark for evaluating the robustness of multi-image understanding models. By providing a diverse dataset of image pairs with a range of relationships, as well as challenging test cases that assess key capabilities like relational reasoning and compositional generalization, the researchers aim to spur progress in building more capable and generalizable multi-image understanding systems.
The availability of this benchmark is a valuable contribution to the field, as it will enable researchers and developers to more rigorously assess the performance and limitations of their models, ultimately leading to significant advancements in areas like visual reasoning, multimodal perception, and multi-modal reasoning. As the field continues to evolve, the MuirBench benchmark will play a crucial role in driving the development of more robust and capable multi-image understanding models that can handle the complexity of the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Benchmarking Multi-Image Understanding in Vision and Language Models: Perception, Knowledge, Reasoning, and Multi-Hop Reasoning
Bingchen Zhao, Yongshuo Zong, Letian Zhang, Timothy Hospedales
0
0
The advancement of large language models (LLMs) has significantly broadened the scope of applications in natural language processing, with multi-modal LLMs extending these capabilities to integrate and interpret visual data. However, existing benchmarks for visual language models (VLMs) predominantly focus on single-image inputs, neglecting the crucial aspect of multi-image understanding. In this paper, we introduce a Multi-Image Relational Benchmark MIRB, designed to evaluate VLMs' ability to compare, analyze, and reason across multiple images. Our benchmark encompasses four categories: perception, visual world knowledge, reasoning, and multi-hop reasoning. Through a comprehensive evaluation of a wide range of open-source and closed-source models, we demonstrate that while open-source VLMs were shown to approach the performance of GPT-4V in single-image tasks, a significant performance gap remains in multi-image reasoning tasks. Our findings also reveal that even the state-of-the-art GPT-4V model struggles with our benchmark, underscoring the need for further research and development in this area. We believe our contribution of MIRB could serve as a testbed for developing the next-generation multi-modal models.
6/19/2024
🖼️
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Ziqiang Liu, Feiteng Fang, Xi Feng, Xinrun Du, Chenhao Zhang, Zekun Wang, Yuelin Bai, Qixuan Zhao, Liyang Fan, Chengguang Gan, Hongquan Lin, Jiaming Li, Yuansheng Ni, Haihong Wu, Yaswanth Narsupalli, Zhigang Zheng, Chengming Li, Xiping Hu, Ruifeng Xu, Xiaojun Chen, Min Yang, Jiaheng Liu, Ruibo Liu, Wenhao Huang, Ge Zhang, Shiwen Ni
0
0
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
6/12/2024
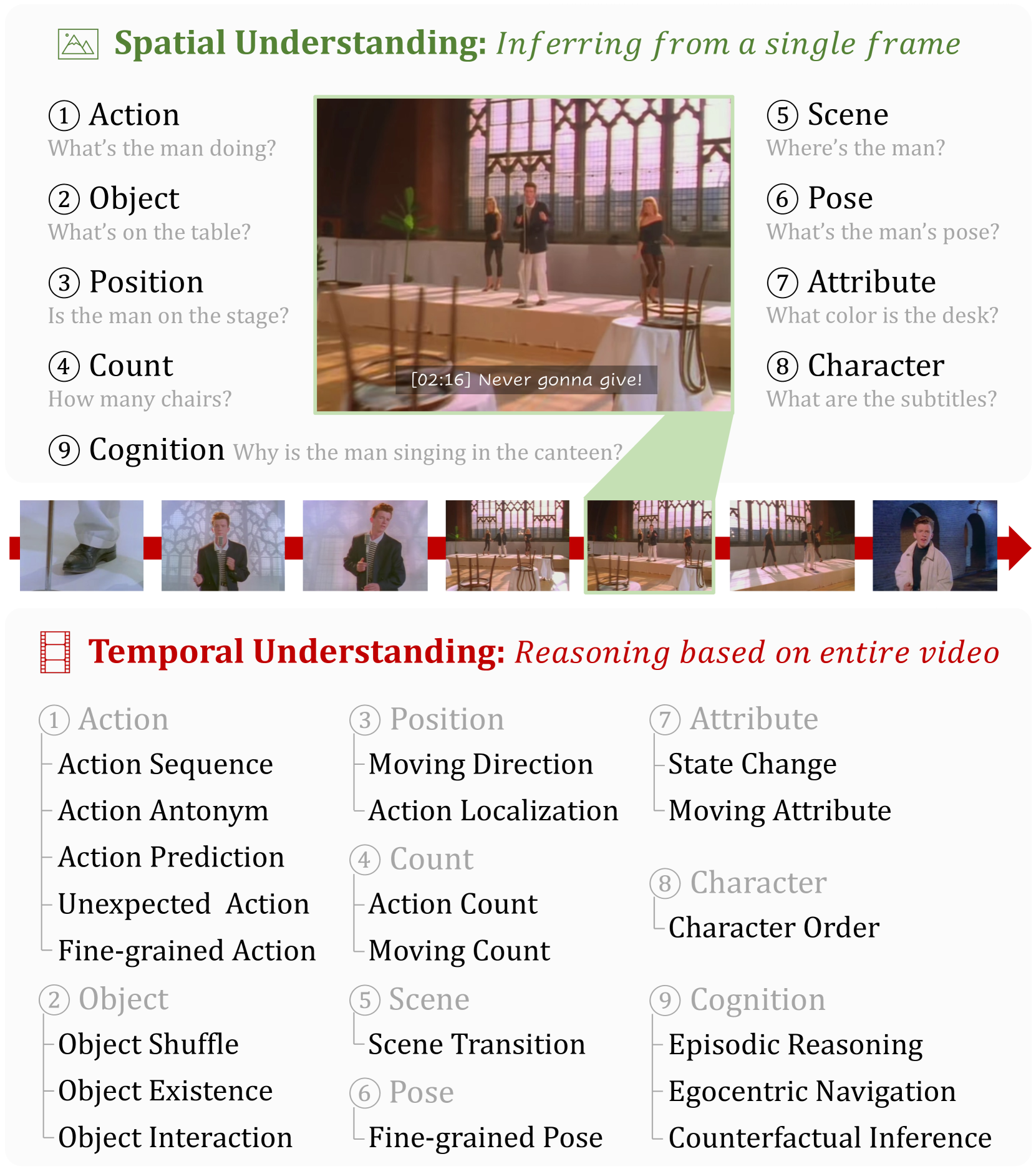
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, Yu Qiao
0
0
With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.
5/24/2024

MMBench: Is Your Multi-modal Model an All-around Player?
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, Dahua Lin
0
0
Large vision-language models have recently achieved remarkable progress, exhibiting great perception and reasoning abilities concerning visual information. However, how to effectively evaluate these large vision-language models remains a major obstacle, hindering future model development. Traditional benchmarks like VQAv2 or COCO Caption provide quantitative performance measurements but suffer from a lack of fine-grained ability assessment and non-robust evaluation metrics. Recent subjective benchmarks, such as OwlEval, offer comprehensive evaluations of a model's abilities by incorporating human labor, but they are not scalable and display significant bias. In response to these challenges, we propose MMBench, a novel multi-modality benchmark. MMBench methodically develops a comprehensive evaluation pipeline, primarily comprised of two elements. The first element is a meticulously curated dataset that surpasses existing similar benchmarks in terms of the number and variety of evaluation questions and abilities. The second element introduces a novel CircularEval strategy and incorporates the use of ChatGPT. This implementation is designed to convert free-form predictions into pre-defined choices, thereby facilitating a more robust evaluation of the model's predictions. MMBench is a systematically-designed objective benchmark for robustly evaluating the various abilities of vision-language models. We hope MMBench will assist the research community in better evaluating their models and encourage future advancements in this domain. Project page: https://opencompass.org.cn/mmbench.
4/30/2024