MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs

0
Sign in to get full access
Overview
- The paper introduces MMDU, a new benchmark for multi-turn, multi-image dialog understanding tasks, along with an instruction-tuning dataset for large vision-language models (LVLMs).
- MMDU is designed to evaluate a model's ability to comprehend and reason about multi-modal dialogs that involve multiple rounds of conversation and images.
- The instruction-tuning dataset provides a way to further train LVLMs on a broad range of tasks, potentially improving their performance on MMDU and other multi-modal understanding challenges.
Plain English Explanation
The MMDU benchmark is a new test for evaluating how well AI language models can understand and reason about multi-part conversations that involve both text and images. Unlike previous benchmarks that focused on single-turn, single-image tasks, MMDU simulates more realistic dialog scenarios where the meaning of each exchange depends on the full context of the conversation and the visual information provided.
To help train models to excel at these types of multi-modal understanding challenges, the researchers also created an instruction-tuning dataset. This dataset contains a wide variety of tasks that models can be fine-tuned on, similar to how humans learn by being given different instructions and examples to practice. By pre-training on this diverse set of tasks, the hope is that language models will develop more versatile and robust multi-modal reasoning capabilities.
The MMDU benchmark and instruction-tuning dataset represent an important step towards building AI assistants that can engage in more natural, contextual dialog and make use of visual information to better comprehend and respond to user queries. This type of multimodal understanding is a key frontier in AI research.
Technical Explanation
The MMDU benchmark consists of a large dataset of multi-turn dialogs, each accompanied by a series of images relevant to the conversation. The dialogs cover a diverse range of topics and require models to track the context and logic of the exchange, as well as interpret how the visual information relates to and informs the dialog.
To create the instruction-tuning dataset, the researchers crowdsourced a broad collection of natural language processing tasks, such as question answering, text summarization, and visual reasoning. These tasks are formatted as natural language instructions that can be used to fine-tune large language models and imbue them with more versatile multi-modal understanding capabilities.
In experiments, the researchers demonstrate that models pre-trained on the instruction-tuning dataset achieve significantly better performance on the MMDU benchmark compared to models trained only on traditional language modeling objectives. This highlights the value of this multi-task learning approach for developing multimodal understanding capabilities.
Critical Analysis
The MMDU benchmark represents an important step forward in evaluating the multi-modal reasoning abilities of language models. However, the dataset is limited to English-language dialogs, and it would be valuable to see similar benchmarks developed for other languages to assess cross-lingual generalization.
Additionally, while the instruction-tuning dataset covers a broad range of tasks, there may be opportunities to further diversify the types of instructions and visual inputs to make the training process even more comprehensive and challenging.
Some potential limitations of the research include the relatively small size of the MMDU dataset compared to the scale of modern language models, as well as the inherent biases and limitations of crowdsourcing task descriptions. Careful analysis of model performance and failure modes on MMDU will be crucial for understanding the strengths and weaknesses of current multimodal understanding capabilities.
Conclusion
The MMDU benchmark and instruction-tuning dataset represent an important advance in the field of multimodal understanding. By providing a more realistic and challenging evaluation of a model's ability to comprehend and reason about multi-modal dialog, MMDU can help drive progress towards building AI assistants that can engage in more natural, contextual interactions. The instruction-tuning dataset, in turn, offers a promising approach for further enhancing the multi-modal capabilities of large language models, which will be crucial for unlocking the full potential of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs
Ziyu Liu, Tao Chu, Yuhang Zang, Xilin Wei, Xiaoyi Dong, Pan Zhang, Zijian Liang, Yuanjun Xiong, Yu Qiao, Dahua Lin, Jiaqi Wang
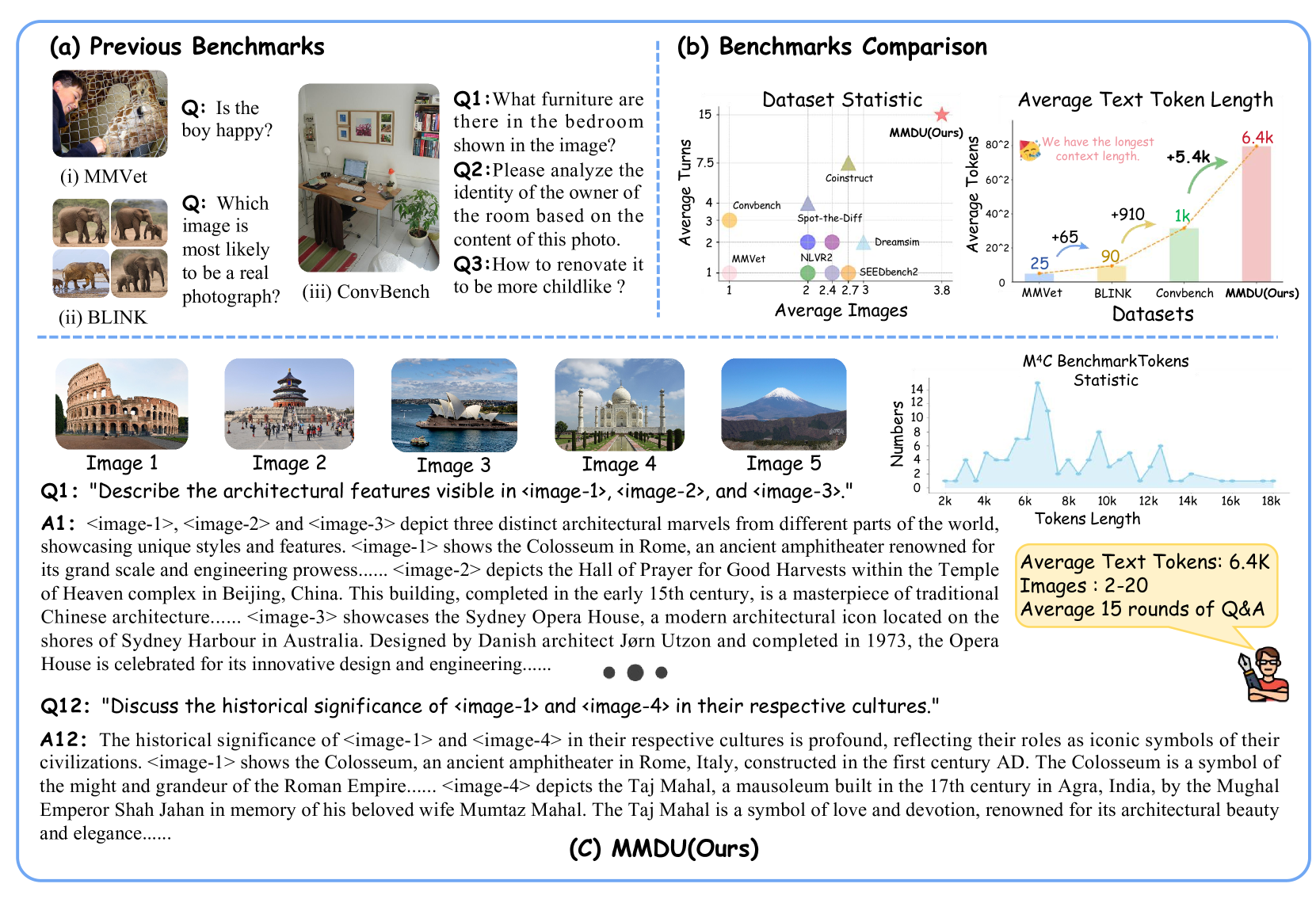
Generating natural and meaningful responses to communicate with multi-modal human inputs is a fundamental capability of Large Vision-Language Models(LVLMs). While current open-source LVLMs demonstrate promising performance in simplified scenarios such as single-turn single-image input, they fall short in real-world conversation scenarios such as following instructions in a long context history with multi-turn and multi-images. Existing LVLM benchmarks primarily focus on single-choice questions or short-form responses, which do not adequately assess the capabilities of LVLMs in real-world human-AI interaction applications. Therefore, we introduce MMDU, a comprehensive benchmark, and MMDU-45k, a large-scale instruction tuning dataset, designed to evaluate and improve LVLMs' abilities in multi-turn and multi-image conversations. We employ the clustering algorithm to ffnd the relevant images and textual descriptions from the open-source Wikipedia and construct the question-answer pairs by human annotators with the assistance of the GPT-4o model. MMDU has a maximum of 18k image+text tokens, 20 images, and 27 turns, which is at least 5x longer than previous benchmarks and poses challenges to current LVLMs. Our in-depth analysis of 15 representative LVLMs using MMDU reveals that open-source LVLMs lag behind closed-source counterparts due to limited conversational instruction tuning data. We demonstrate that ffne-tuning open-source LVLMs on MMDU-45k signiffcantly address this gap, generating longer and more accurate conversations, and improving scores on MMDU and existing benchmarks (MMStar: +1.1%, MathVista: +1.5%, ChartQA:+1.2%). Our contributions pave the way for bridging the gap between current LVLM models and real-world application demands. This project is available at https://github.com/Liuziyu77/MMDU.
Read more6/18/2024
🤔
0
MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models
Fanqing Meng, Jin Wang, Chuanhao Li, Quanfeng Lu, Hao Tian, Jiaqi Liao, Xizhou Zhu, Jifeng Dai, Yu Qiao, Ping Luo, Kaipeng Zhang, Wenqi Shao
The capability to process multiple images is crucial for Large Vision-Language Models (LVLMs) to develop a more thorough and nuanced understanding of a scene. Recent multi-image LVLMs have begun to address this need. However, their evaluation has not kept pace with their development. To fill this gap, we introduce the Multimodal Multi-image Understanding (MMIU) benchmark, a comprehensive evaluation suite designed to assess LVLMs across a wide range of multi-image tasks. MMIU encompasses 7 types of multi-image relationships, 52 tasks, 77K images, and 11K meticulously curated multiple-choice questions, making it the most extensive benchmark of its kind. Our evaluation of 24 popular LVLMs, including both open-source and proprietary models, reveals significant challenges in multi-image comprehension, particularly in tasks involving spatial understanding. Even the most advanced models, such as GPT-4o, achieve only 55.7% accuracy on MMIU. Through multi-faceted analytical experiments, we identify key performance gaps and limitations, providing valuable insights for future model and data improvements. We aim for MMIU to advance the frontier of LVLM research and development, moving us toward achieving sophisticated multimodal multi-image user interactions.
Read more8/7/2024
🤔
0
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, Wenhu Chen
We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. These questions span 30 subjects and 183 subfields, comprising 30 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of 14 open-source LMMs as well as the proprietary GPT-4V(ision) and Gemini highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V and Gemini Ultra only achieve accuracies of 56% and 59% respectively, indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
Read more6/14/2024

0
CMMU: A Benchmark for Chinese Multi-modal Multi-type Question Understanding and Reasoning
Zheqi He, Xinya Wu, Pengfei Zhou, Richeng Xuan, Guang Liu, Xi Yang, Qiannan Zhu, Hua Huang
Multi-modal large language models(MLLMs) have achieved remarkable progress and demonstrated powerful knowledge comprehension and reasoning abilities. However, the mastery of domain-specific knowledge, which is essential for evaluating the intelligence of MLLMs, continues to be a challenge. Current multi-modal benchmarks for domain-specific knowledge concentrate on multiple-choice questions and are predominantly available in English, which imposes limitations on the comprehensiveness of the evaluation. To this end, we introduce CMMU, a novel benchmark for multi-modal and multi-type question understanding and reasoning in Chinese. CMMU consists of 3,603 questions in 7 subjects, covering knowledge from primary to high school. The questions can be categorized into 3 types: multiple-choice, multiple-response, and fill-in-the-blank, bringing greater challenges to MLLMs. In addition, we propose an evaluation strategy called Positional Error Variance for assessing multiple-choice questions. The strategy aims to perform a quantitative analysis of position bias. We evaluate seven open-source MLLMs along with GPT4-V, Gemini-Pro, and Qwen-VL-Plus. The results demonstrate that CMMU poses a significant challenge to the recent MLLMs. The data and code are available at https://github.com/FlagOpen/CMMU.
Read more5/9/2024