MMoE: Enhancing Multimodal Models with Mixtures of Multimodal Interaction Experts

0
⚙️
Sign in to get full access
Overview
- Multimodal models have greatly improved how interactions relevant to various tasks are modeled, but they mainly focus on the correspondence between images and text.
- Novel interactions, such as sarcasm expressed through opposing spoken words and gestures or humor expressed through utterances and tone of voice, remain challenging for current multimodal models.
- This paper introduces an approach called Multimodal Mixtures of Experts (MMoE) to enhance multimodal models and tackle these novel interactions.
Plain English Explanation
The paper introduces a new approach called Multimodal Mixtures of Experts (MMoE) to improve multimodal models, which are models that can work with different types of data like images and text. Current multimodal models mainly focus on understanding the relationship between images and text, but they struggle with more complex interactions, like sarcasm or humor, where multiple modes of communication (like speech and body language) are used together.
The key idea of MMoE is to train separate "expert" models for each type of interaction, such as when the information in both modalities is the same, when one modality has unique information, or when the two modalities work together in a special way. By having these specialized experts, the model can better understand the nuanced ways that different modalities can be combined.
The paper shows that MMoE outperforms other approaches on two challenging tasks: sarcasm detection and humor detection. This suggests that MMoE is a promising way to make multimodal models more powerful and versatile, allowing them to handle a wider range of real-world interactions.
Technical Explanation
The paper introduces a new approach called Multimodal Mixtures of Experts (MMoE) to enhance the performance of multimodal models. Current multimodal models mainly focus on the correspondence between images and text, but they struggle with more complex multimodal interactions, such as sarcasm expressed through opposing spoken words and gestures or humor expressed through utterances and tone of voice.
The key idea behind MMoE is to train separate "expert" models for different types of multimodal interactions, such as:
- Redundancy: when the information is present in both modalities
- Uniqueness: when one modality has unique information
- Synergy: when the two modalities work together in a special way
By having these specialized experts, the model can better understand the nuanced ways that different modalities can be combined, allowing it to handle a wider range of real-world multimodal interactions.
The paper evaluates MMoE on two challenging tasks: sarcasm detection (using the MUStARD dataset) and humor detection (using the URFUNNY dataset). The results show that MMoE outperforms other state-of-the-art multimodal approaches on these tasks, demonstrating the effectiveness of this approach.
Critical Analysis
The paper presents a promising approach to enhancing multimodal models, but it also acknowledges some limitations and areas for further research:
-
Dataset Limitations: The evaluation was conducted on two specific datasets (MUStARD and URFUNNY) that may not be representative of all types of multimodal interactions. Further testing on a broader range of datasets would help validate the generalizability of the MMoE approach.
-
Computational Complexity: Training separate expert models for each type of interaction may increase the computational complexity of the overall system. The authors note that techniques like parameter sharing could be explored to mitigate this issue.
-
Interpretability: The paper does not delve into the interpretability of the expert models within the MMoE framework. Understanding how each expert model contributes to the final prediction could provide valuable insights and help with model debugging and development.
-
Real-world Deployment: The paper focuses on the technical aspects of the MMoE approach, but it does not discuss the practical challenges of deploying such a system in real-world applications, such as data collection, annotation, and model maintenance.
Despite these limitations, the paper presents a compelling approach to enhancing multimodal models and opens up several directions for future research in this area.
Conclusion
This paper introduces a novel approach called Multimodal Mixtures of Experts (MMoE) to improve the performance of multimodal models, particularly in handling complex multimodal interactions like sarcasm and humor. By training separate expert models for different types of multimodal interactions, MMoE is able to outperform other state-of-the-art methods on challenging tasks.
The significance of this work lies in its potential to expand the capabilities of multimodal models, allowing them to better understand and respond to the nuanced ways that people communicate in the real world. As multimodal interactions become increasingly important in fields like human-computer interaction, entertainment, and social media, approaches like MMoE could play a crucial role in developing more robust and versatile AI systems.
While the paper identifies some limitations and areas for further research, the overall contribution of MMoE is a valuable step forward in the ongoing efforts to push the boundaries of multimodal AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
MMoE: Enhancing Multimodal Models with Mixtures of Multimodal Interaction Experts
Haofei Yu, Zhengyang Qi, Lawrence Jang, Ruslan Salakhutdinov, Louis-Philippe Morency, Paul Pu Liang
Advances in multimodal models have greatly improved how interactions relevant to various tasks are modeled. Today's multimodal models mainly focus on the correspondence between images and text, using this for tasks like image-text matching. However, this covers only a subset of real-world interactions. Novel interactions, such as sarcasm expressed through opposing spoken words and gestures or humor expressed through utterances and tone of voice, remain challenging. In this paper, we introduce an approach to enhance multimodal models, which we call Multimodal Mixtures of Experts (MMoE). The key idea in MMoE is to train separate expert models for each type of multimodal interaction, such as redundancy present in both modalities, uniqueness in one modality, or synergy that emerges when both modalities are fused. On a sarcasm detection task (MUStARD) and a humor detection task (URFUNNY), we obtain new state-of-the-art results. MMoE is also able to be applied to various types of models to gain improvement.
Read more9/27/2024
0
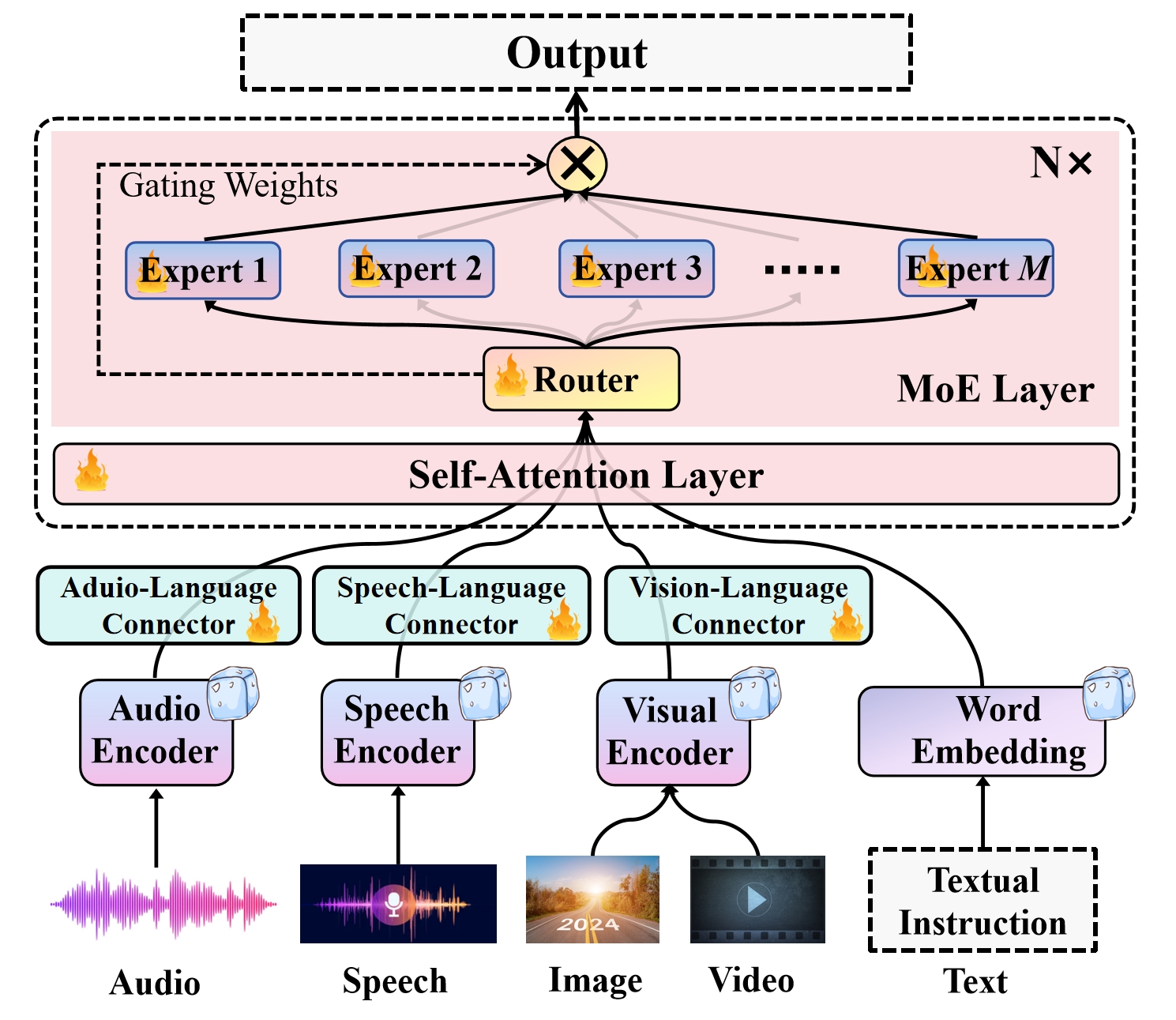
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
Read more5/21/2024
0
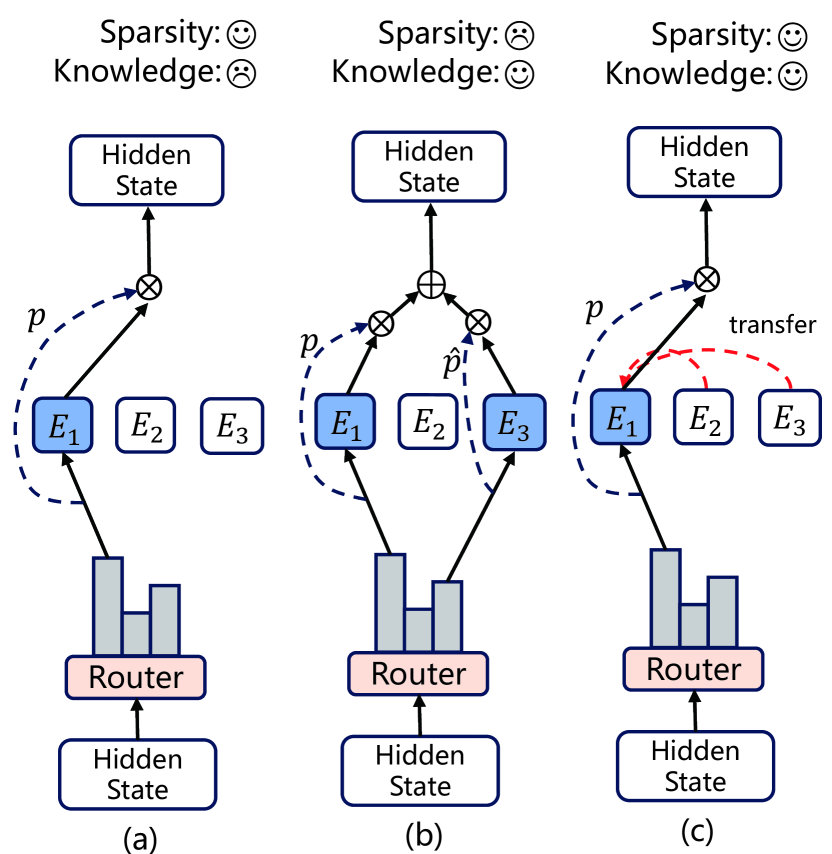
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
Read more7/26/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024