Model-Agnostic Utility-Preserving Biometric Information Anonymization
2405.15062
0
0

Abstract
The recent rapid advancements in both sensing and machine learning technologies have given rise to the universal collection and utilization of people's biometrics, such as fingerprints, voices, retina/facial scans, or gait/motion/gestures data, enabling a wide range of applications including authentication, health monitoring, or much more sophisticated analytics. While providing better user experiences and deeper business insights, the use of biometrics has raised serious privacy concerns due to their intrinsic sensitive nature and the accompanying high risk of leaking sensitive information such as identity or medical conditions. In this paper, we propose a novel modality-agnostic data transformation framework that is capable of anonymizing biometric data by suppressing its sensitive attributes and retaining features relevant to downstream machine learning-based analyses that are of research and business values. We carried out a thorough experimental evaluation using publicly available facial, voice, and motion datasets. Results show that our proposed framework can achieve a highlight{high suppression level for sensitive information}, while at the same time retain underlying data utility such that subsequent analyses on the anonymized biometric data could still be carried out to yield satisfactory accuracy.
Create account to get full access
Overview
- Presents a model-agnostic approach to anonymize biometric information while preserving utility for various downstream tasks
- Leverages perturbations to transform biometric data, such as face images, in a way that protects privacy while maintaining performance on tasks like face recognition
- Introduces a utility-preserving anonymization framework that can work with different machine learning models without needing to retrain them
Plain English Explanation
This research paper introduces a new way to protect people's privacy when it comes to biometric data, such as face images. Biometric data is often used for things like security and personalization, but it can also be used to identify and track individuals without their consent. The researchers developed a method that can anonymize this biometric data, making it harder to identify the person, while still keeping it useful for tasks like face recognition.
The key idea is to apply small, carefully-designed changes or "perturbations" to the biometric data that scramble the identifying information but leave the essential characteristics intact. This allows the data to still be useful for AI models that perform tasks like facial analysis, without revealing the person's identity. Importantly, this approach is "model-agnostic", meaning it can work with different AI models without needing to retrain them.
The researchers tested their method on face images and demonstrated that it could preserve the performance of face recognition models while significantly reducing the ability to identify the individuals. This suggests their technique could be a valuable tool for organizations that work with biometric data, helping them balance privacy and utility.
Technical Explanation
The paper presents a model-agnostic utility-preserving biometric information anonymization framework that can transform biometric data, such as face images, in a way that protects individual privacy while preserving the utility for downstream tasks.
The key components of the approach are:
- Perturbation Generation: The system generates small, carefully-designed perturbations to apply to the biometric data. These perturbations aim to obfuscate identifying information while preserving the essential characteristics needed for tasks like facial analysis.
- Utility Preservation: The perturbations are optimized to maximize the preservation of utility, as measured by the performance of various downstream machine learning models on the transformed data.
- Model-Agnostic Design: The framework is designed to work with different machine learning models without requiring retraining, making it a flexible and practical solution.
The researchers evaluated their approach on facial recognition tasks, demonstrating that it could significantly reduce the ability to identify individuals while maintaining high performance on tasks like facial analysis. This suggests the technique could be a valuable tool for organizations that work with sensitive biometric data, helping them balance privacy and utility.
Critical Analysis
The paper presents a compelling approach to the important challenge of preserving privacy in biometric data while maintaining its utility for various applications. The model-agnostic design and focus on utility preservation are particularly noteworthy, as they make the technique more practical and versatile than some previous privacy-preserving methods.
However, the paper does acknowledge some limitations and areas for further research. For example, the perturbations generated by the system may not be effective against more advanced de-anonymization attacks, and the utility preservation guarantees are specific to the tasks and models evaluated in the study. Additional research is needed to better understand the broader robustness and generalizability of the approach.
Furthermore, while the paper discusses the privacy-utility tradeoff, it does not delve deeply into the ethical implications of biometric data anonymization or the potential for misuse of such techniques. As with any privacy-preserving technology, there are important considerations around consent, transparency, and the appropriate use of these methods that warrant further discussion and investigation.
Overall, the model-agnostic utility-preserving biometric information anonymization approach presented in this paper represents a valuable contribution to the field of privacy-preserving machine learning. However, continued research and thoughtful deployment of such techniques will be necessary to ensure they are used responsibly and in alignment with ethical principles.
Conclusion
This research paper introduces a novel approach to anonymizing biometric data, such as facial images, while preserving the utility of the data for various downstream tasks. By applying carefully-designed perturbations to the biometric data, the system can obfuscate identifying information while maintaining the essential characteristics needed for applications like facial analysis.
The model-agnostic design and focus on utility preservation make this technique a practical and flexible solution for organizations that work with sensitive biometric data. The demonstrated ability to significantly reduce identification while preserving model performance suggests this approach could be a valuable tool for balancing privacy and utility in the age of biometric technology.
As the use of biometric data continues to expand, solutions like the one presented in this paper will become increasingly important for protecting individual privacy and ensuring the responsible use of these powerful technologies. While further research is needed to address the limitations and ethical considerations, this work represents an important step forward in the field of privacy-preserving machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
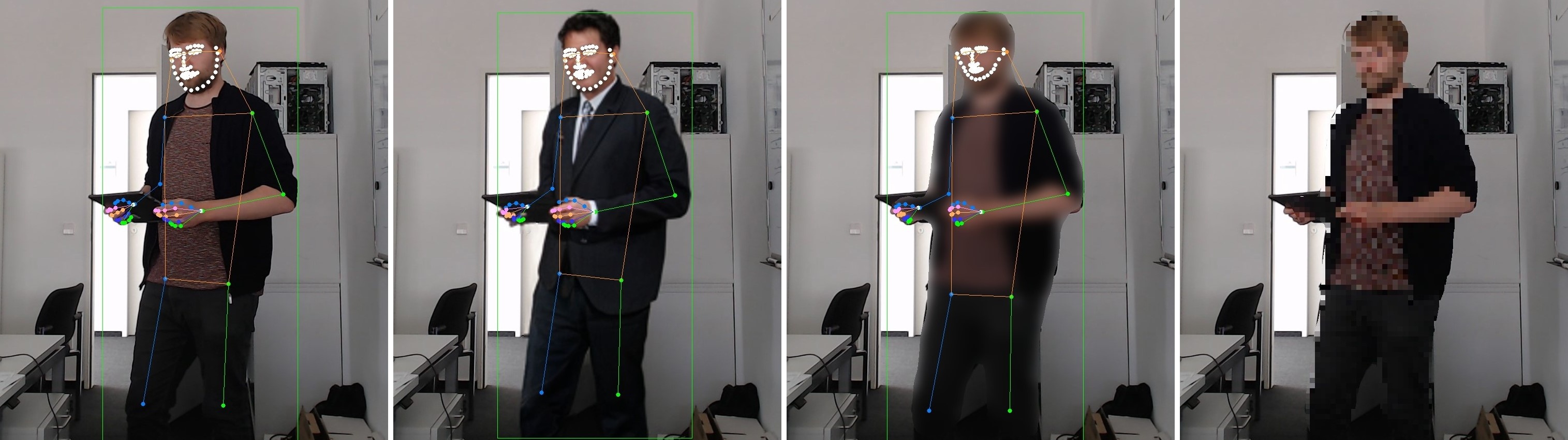
Exploring AI-based Anonymization of Industrial Image and Video Data in the Context of Feature Preservation
Sabrina Cynthia Triess, Timo Leitritz, Christian Jauch
0
0
With rising technologies, the protection of privacy-sensitive information is becoming increasingly important. In industry and production facilities, image or video recordings are beneficial for documentation, tracing production errors or coordinating workflows. Individuals in images or videos need to be anonymized. However, the anonymized data should be reusable for further applications. In this work, we apply the Deep Learning-based full-body anonymization framework DeepPrivacy2, which generates artificial identities, to industrial image and video data. We compare its performance with conventional anonymization techniques. Therefore, we consider the quality of identity generation, temporal consistency, and the applicability of pose estimation and action recognition.
5/30/2024

MaSS: Multi-attribute Selective Suppression for Utility-preserving Data Transformation from an Information-theoretic Perspective
Yizhuo Chen, Chun-Fu Chen, Hsiang Hsu, Shaohan Hu, Marco Pistoia, Tarek Abdelzaher
0
0
The growing richness of large-scale datasets has been crucial in driving the rapid advancement and wide adoption of machine learning technologies. The massive collection and usage of data, however, pose an increasing risk for people's private and sensitive information due to either inadvertent mishandling or malicious exploitation. Besides legislative solutions, many technical approaches have been proposed towards data privacy protection. However, they bear various limitations such as leading to degraded data availability and utility, or relying on heuristics and lacking solid theoretical bases. To overcome these limitations, we propose a formal information-theoretic definition for this utility-preserving privacy protection problem, and design a data-driven learnable data transformation framework that is capable of selectively suppressing sensitive attributes from target datasets while preserving the other useful attributes, regardless of whether or not they are known in advance or explicitly annotated for preservation. We provide rigorous theoretical analyses on the operational bounds for our framework, and carry out comprehensive experimental evaluations using datasets of a variety of modalities, including facial images, voice audio clips, and human activity motion sensor signals. Results demonstrate the effectiveness and generalizability of our method under various configurations on a multitude of tasks.
5/27/2024
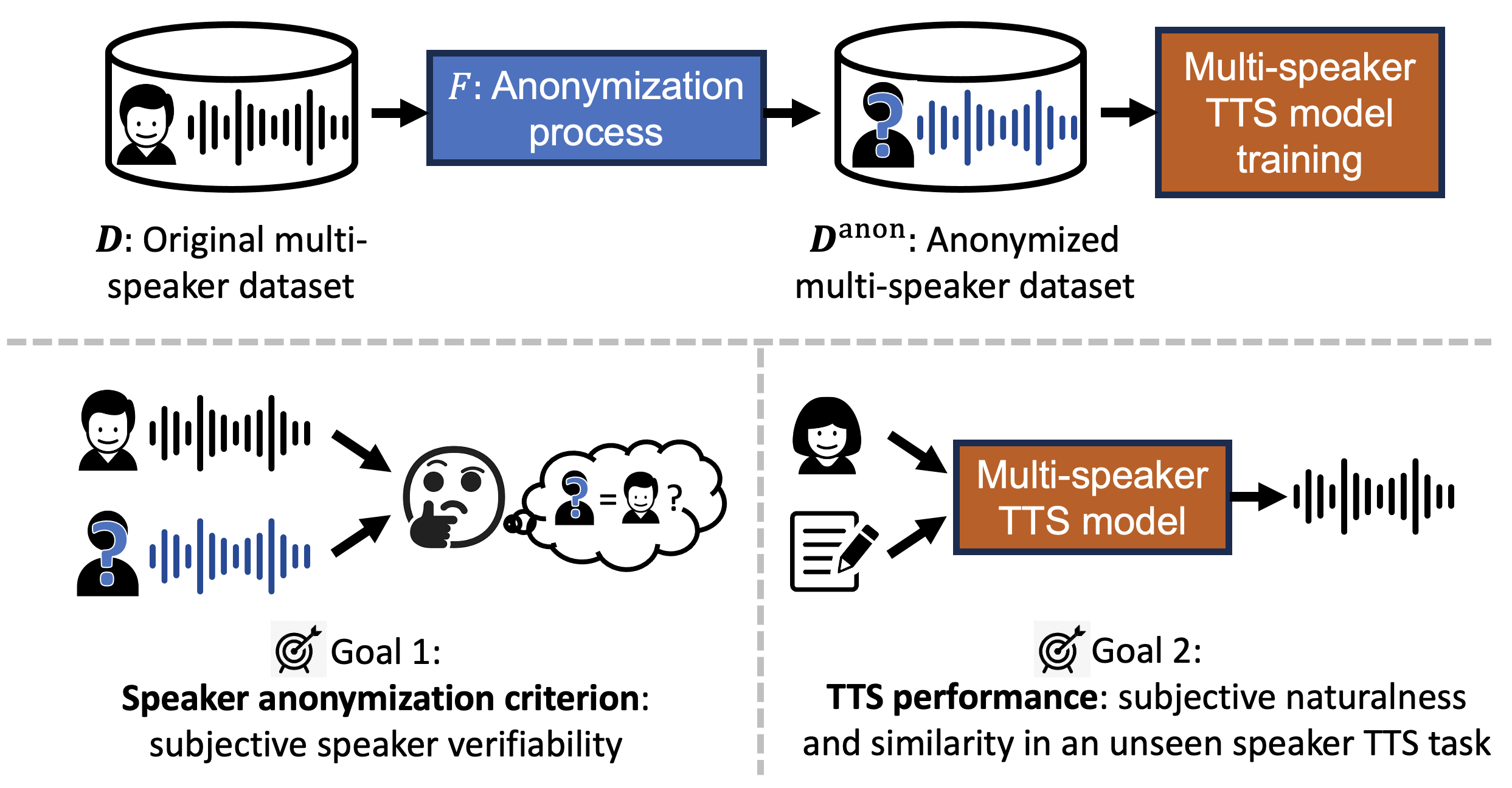
Multi-speaker Text-to-speech Training with Speaker Anonymized Data
Wen-Chin Huang, Yi-Chiao Wu, Tomoki Toda
0
0
The trend of scaling up speech generation models poses a threat of biometric information leakage of the identities of the voices in the training data, raising privacy and security concerns. In this paper, we investigate training multi-speaker text-to-speech (TTS) models using data that underwent speaker anonymization (SA), a process that tends to hide the speaker identity of the input speech while maintaining other attributes. Two signal processing-based and three deep neural network-based SA methods were used to anonymize VCTK, a multi-speaker TTS dataset, which is further used to train an end-to-end TTS model, VITS, to perform unseen speaker TTS during the testing phase. We conducted extensive objective and subjective experiments to evaluate the anonymized training data, as well as the performance of the downstream TTS model trained using those data. Importantly, we found that UTMOS, a data-driven subjective rating predictor model, and GVD, a metric that measures the gain of voice distinctiveness, are good indicators of the downstream TTS performance. We summarize insights in the hope of helping future researchers determine the goodness of the SA system for multi-speaker TTS training.
5/21/2024

Fingerprint Membership and Identity Inference Against Generative Adversarial Networks
Saverio Cavasin, Daniele Mari, Simone Milani, Mauro Conti
0
0
Generative models are gaining significant attention as potential catalysts for a novel industrial revolution. Since automated sample generation can be useful to solve privacy and data scarcity issues that usually affect learned biometric models, such technologies became widely spread in this field. In this paper, we assess the vulnerabilities of generative machine learning models concerning identity protection by designing and testing an identity inference attack on fingerprint datasets created by means of a generative adversarial network. Experimental results show that the proposed solution proves to be effective under different configurations and easily extendable to other biometric measurements.
6/24/2024