MaSS: Multi-attribute Selective Suppression for Utility-preserving Data Transformation from an Information-theoretic Perspective
2405.14981
0
0

Abstract
The growing richness of large-scale datasets has been crucial in driving the rapid advancement and wide adoption of machine learning technologies. The massive collection and usage of data, however, pose an increasing risk for people's private and sensitive information due to either inadvertent mishandling or malicious exploitation. Besides legislative solutions, many technical approaches have been proposed towards data privacy protection. However, they bear various limitations such as leading to degraded data availability and utility, or relying on heuristics and lacking solid theoretical bases. To overcome these limitations, we propose a formal information-theoretic definition for this utility-preserving privacy protection problem, and design a data-driven learnable data transformation framework that is capable of selectively suppressing sensitive attributes from target datasets while preserving the other useful attributes, regardless of whether or not they are known in advance or explicitly annotated for preservation. We provide rigorous theoretical analyses on the operational bounds for our framework, and carry out comprehensive experimental evaluations using datasets of a variety of modalities, including facial images, voice audio clips, and human activity motion sensor signals. Results demonstrate the effectiveness and generalizability of our method under various configurations on a multitude of tasks.
Create account to get full access
Overview
- This paper presents MaSS, a novel approach for utility-preserving data transformation that selectively suppresses attributes to protect sensitive information while preserving the overall utility of the data.
- The method is informed by information theory principles to balance the trade-off between privacy and utility.
- Experiments demonstrate MaSS can outperform existing techniques in preserving data utility while providing robust privacy guarantees.
Plain English Explanation
The paper introduces MaSS, a new way to transform data in a privacy-preserving manner. The key idea is to selectively hide or "suppress" certain attributes of the data, while still maintaining the overall usefulness or "utility" of the data for analysis.
The researchers used information theory concepts to carefully choose which attributes to suppress in order to strike the right balance between protecting sensitive information and preserving the data's value.
Through experiments, they showed that MaSS can outperform other existing techniques at this task. It is able to efficiently protect privacy while still keeping the transformed data highly useful for things like training machine learning models or conducting data analysis.
Technical Explanation
The paper proposes a technique called MaSS (Multi-attribute Selective Suppression) that aims to transform data in a way that protects sensitive information while preserving the overall utility of the data.
The key innovation is the selective suppression of attributes based on an information-theoretic framework. By analyzing the information content and interdependencies between different data attributes, MaSS can identify the optimal set of attributes to suppress in order to limit disclosure of sensitive information, while retaining as much of the data's utility as possible.
The authors formulate the problem as an optimization task, where the goal is to minimize the loss of useful information (utility) subject to a constraint on the amount of sensitive information that can be disclosed. They propose an efficient algorithm to solve this optimization problem.
Experiments on real-world datasets show that MaSS can significantly outperform existing techniques, such as Model-Agnostic Utility-Preserving Biometric Information Anonymization and Optimizing Privacy-Utility Tradeoffs for Group Interests through Individualized Distortions, in terms of preserving data utility while providing robust privacy guarantees.
Critical Analysis
The paper provides a thoughtful and well-designed approach to the challenge of balancing data privacy and utility. By leveraging information theory principles, the MaSS method offers a principled way to selectively suppress attributes in a way that preserves as much useful information as possible.
One potential limitation is that the method assumes the sensitive attributes are known a priori. In real-world scenarios, it may not always be clear which attributes are sensitive, and the notion of sensitivity can also be context-dependent. State-of-the-Art Approaches to Enhancing Privacy Preservation discusses some of the challenges in defining and identifying sensitive information.
Additionally, the experiments in the paper focus on traditional machine learning tasks, such as classification and regression. It would be interesting to see how MaSS performs in the context of more complex data analysis scenarios, such as those involving Privacy-Preserving Debiasing Using Data Augmentation and Machine Learning or Trusting Fair Data by Leveraging Quality and Fairness-Driven Data Curation.
Nevertheless, the paper makes a valuable contribution by introducing a novel and theoretically-grounded approach to the critical challenge of balancing privacy and utility in data transformation.
Conclusion
The MaSS technique presented in this paper offers a promising solution for utility-preserving data transformation. By selectively suppressing attributes based on an information-theoretic analysis, MaSS is able to protect sensitive information while retaining a high degree of data utility.
The authors' experimental results demonstrate the effectiveness of their approach, suggesting that MaSS could be a valuable tool for a wide range of data analysis tasks that require both privacy and utility preservation. As data privacy becomes an increasingly important concern, techniques like MaSS will be crucial for enabling the responsible use of sensitive data in service of scientific and societal progress.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
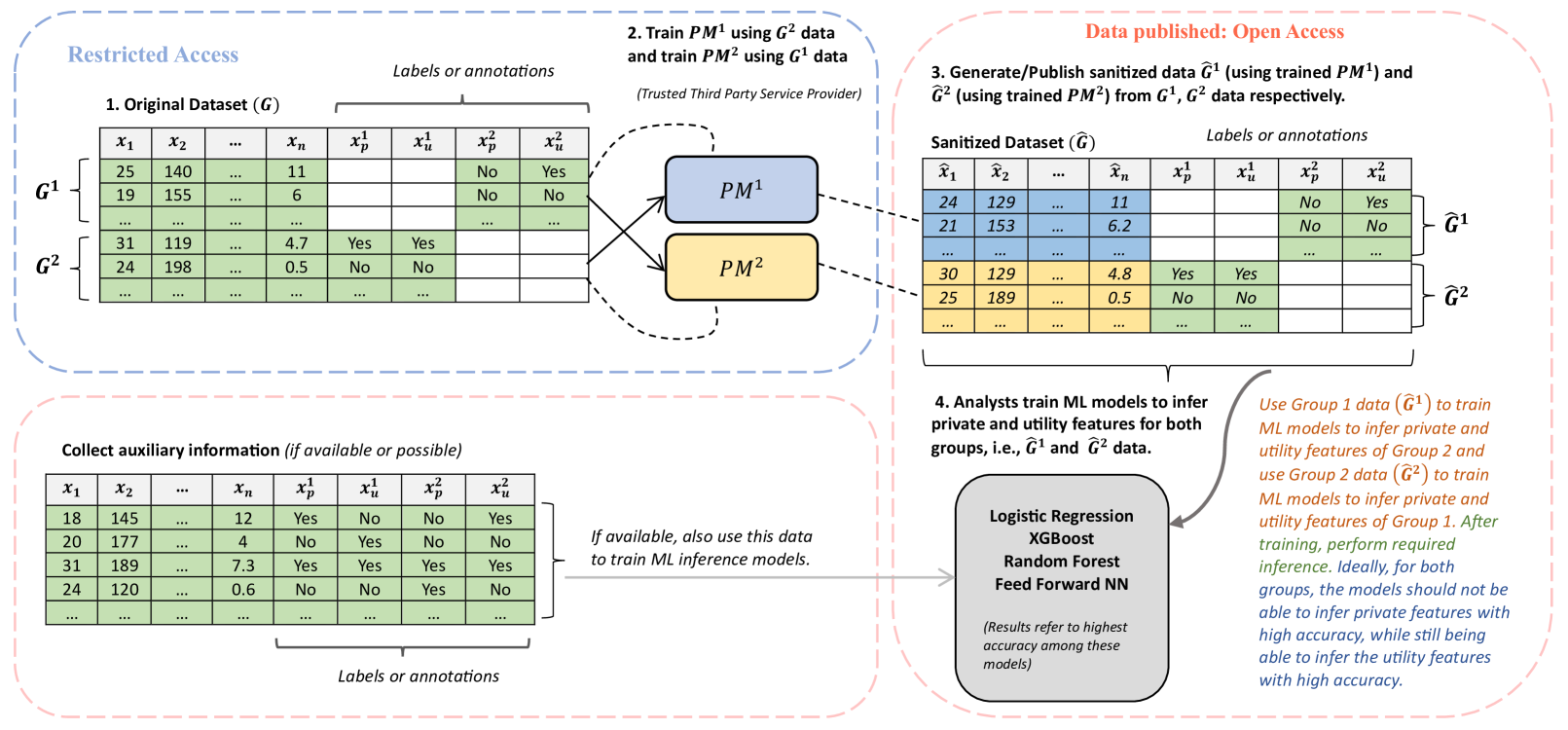
Optimizing Privacy and Utility Tradeoffs for Group Interests Through Harmonization
Bishwas Mandal, George Amariucai, Shuangqing Wei
0
0
We propose a novel problem formulation to address the privacy-utility tradeoff, specifically when dealing with two distinct user groups characterized by unique sets of private and utility attributes. Unlike previous studies that primarily focus on scenarios where all users share identical private and utility attributes and often rely on auxiliary datasets or manual annotations, we introduce a collaborative data-sharing mechanism between two user groups through a trusted third party. This third party uses adversarial privacy techniques with our proposed data-sharing mechanism to internally sanitize data for both groups and eliminates the need for manual annotation or auxiliary datasets. Our methodology ensures that private attributes cannot be accurately inferred while enabling highly accurate predictions of utility features. Importantly, even if analysts or adversaries possess auxiliary datasets containing raw data, they are unable to accurately deduce private features. Additionally, our data-sharing mechanism is compatible with various existing adversarially trained privacy techniques. We empirically demonstrate the effectiveness of our approach using synthetic and real-world datasets, showcasing its ability to balance the conflicting goals of privacy and utility.
4/9/2024
💬
State-of-the-Art Approaches to Enhancing Privacy Preservation of Machine Learning Datasets: A Survey
Chaoyu Zhang
0
0
This paper examines the evolving landscape of machine learning (ML) and its profound impact across various sectors, with a special focus on the emerging field of Privacy-preserving Machine Learning (PPML). As ML applications become increasingly integral to industries like telecommunications, financial technology, and surveillance, they raise significant privacy concerns, necessitating the development of PPML strategies. The paper highlights the unique challenges in safeguarding privacy within ML frameworks, which stem from the diverse capabilities of potential adversaries, including their ability to infer sensitive information from model outputs or training data. We delve into the spectrum of threat models that characterize adversarial intentions, ranging from membership and attribute inference to data reconstruction. The paper emphasizes the importance of maintaining the confidentiality and integrity of training data, outlining current research efforts that focus on refining training data to minimize privacy-sensitive information and enhancing data processing techniques to uphold privacy. Through a comprehensive analysis of privacy leakage risks and countermeasures in both centralized and collaborative learning settings, this paper aims to provide a thorough understanding of effective strategies for protecting ML training data against privacy intrusions. It explores the balance between data privacy and model utility, shedding light on privacy-preserving techniques that leverage cryptographic methods, Differential Privacy, and Trusted Execution Environments. The discussion extends to the application of these techniques in sensitive domains, underscoring the critical role of PPML in ensuring the privacy and security of ML systems.
4/29/2024

Model-Agnostic Utility-Preserving Biometric Information Anonymization
Chun-Fu Chen, Bill Moriarty, Shaohan Hu, Sean Moran, Marco Pistoia, Vincenzo Piuri, Pierangela Samarati
0
0
The recent rapid advancements in both sensing and machine learning technologies have given rise to the universal collection and utilization of people's biometrics, such as fingerprints, voices, retina/facial scans, or gait/motion/gestures data, enabling a wide range of applications including authentication, health monitoring, or much more sophisticated analytics. While providing better user experiences and deeper business insights, the use of biometrics has raised serious privacy concerns due to their intrinsic sensitive nature and the accompanying high risk of leaking sensitive information such as identity or medical conditions. In this paper, we propose a novel modality-agnostic data transformation framework that is capable of anonymizing biometric data by suppressing its sensitive attributes and retaining features relevant to downstream machine learning-based analyses that are of research and business values. We carried out a thorough experimental evaluation using publicly available facial, voice, and motion datasets. Results show that our proposed framework can achieve a highlight{high suppression level for sensitive information}, while at the same time retain underlying data utility such that subsequent analyses on the anonymized biometric data could still be carried out to yield satisfactory accuracy.
5/27/2024

Privacy-Preserving Debiasing using Data Augmentation and Machine Unlearning
Zhixin Pan, Emma Andrews, Laura Chang, Prabhat Mishra
0
0
Data augmentation is widely used to mitigate data bias in the training dataset. However, data augmentation exposes machine learning models to privacy attacks, such as membership inference attacks. In this paper, we propose an effective combination of data augmentation and machine unlearning, which can reduce data bias while providing a provable defense against known attacks. Specifically, we maintain the fairness of the trained model with diffusion-based data augmentation, and then utilize multi-shard unlearning to remove identifying information of original data from the ML model for protection against privacy attacks. Experimental evaluation across diverse datasets demonstrates that our approach can achieve significant improvements in bias reduction as well as robustness against state-of-the-art privacy attacks.
4/23/2024